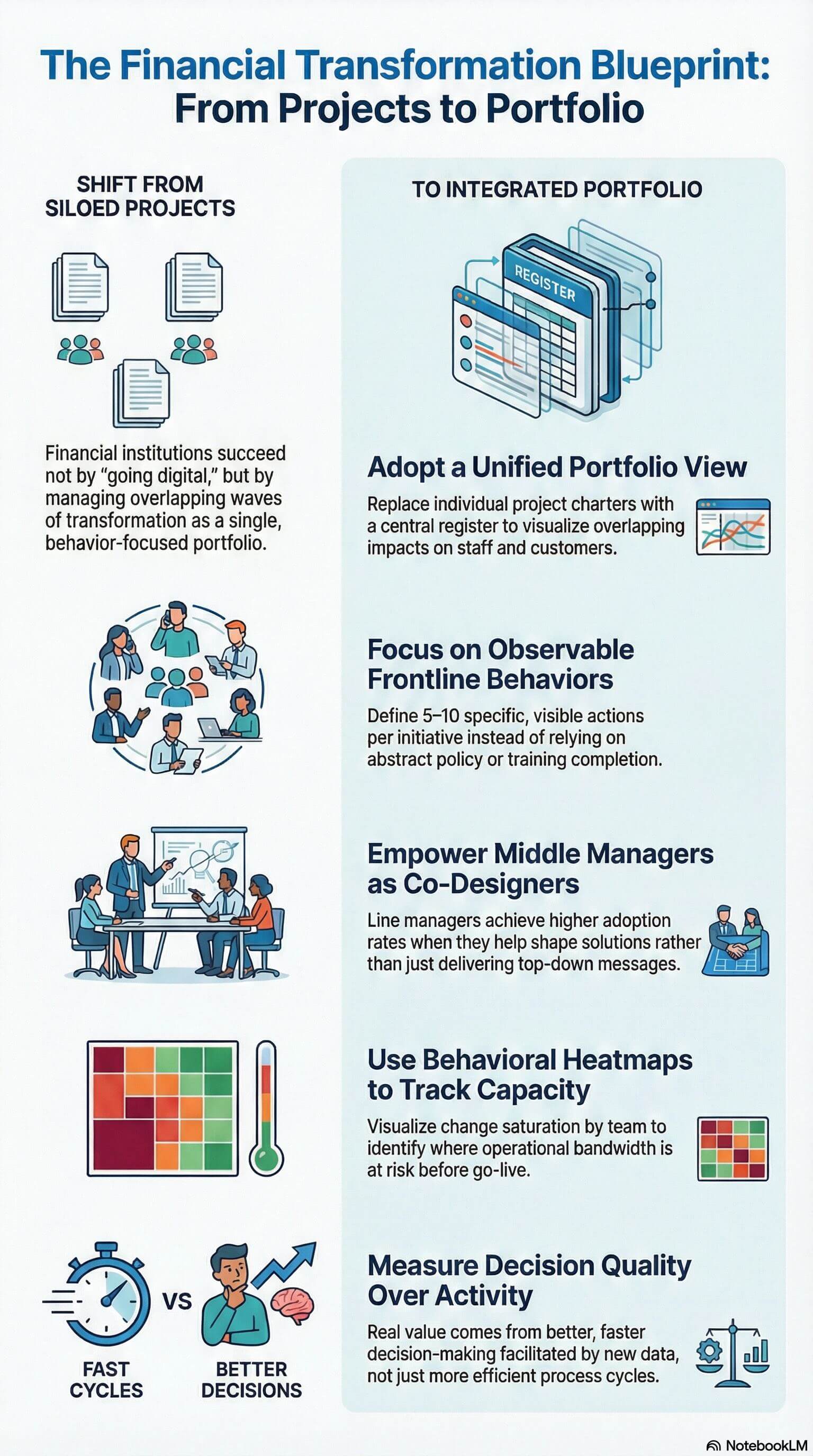
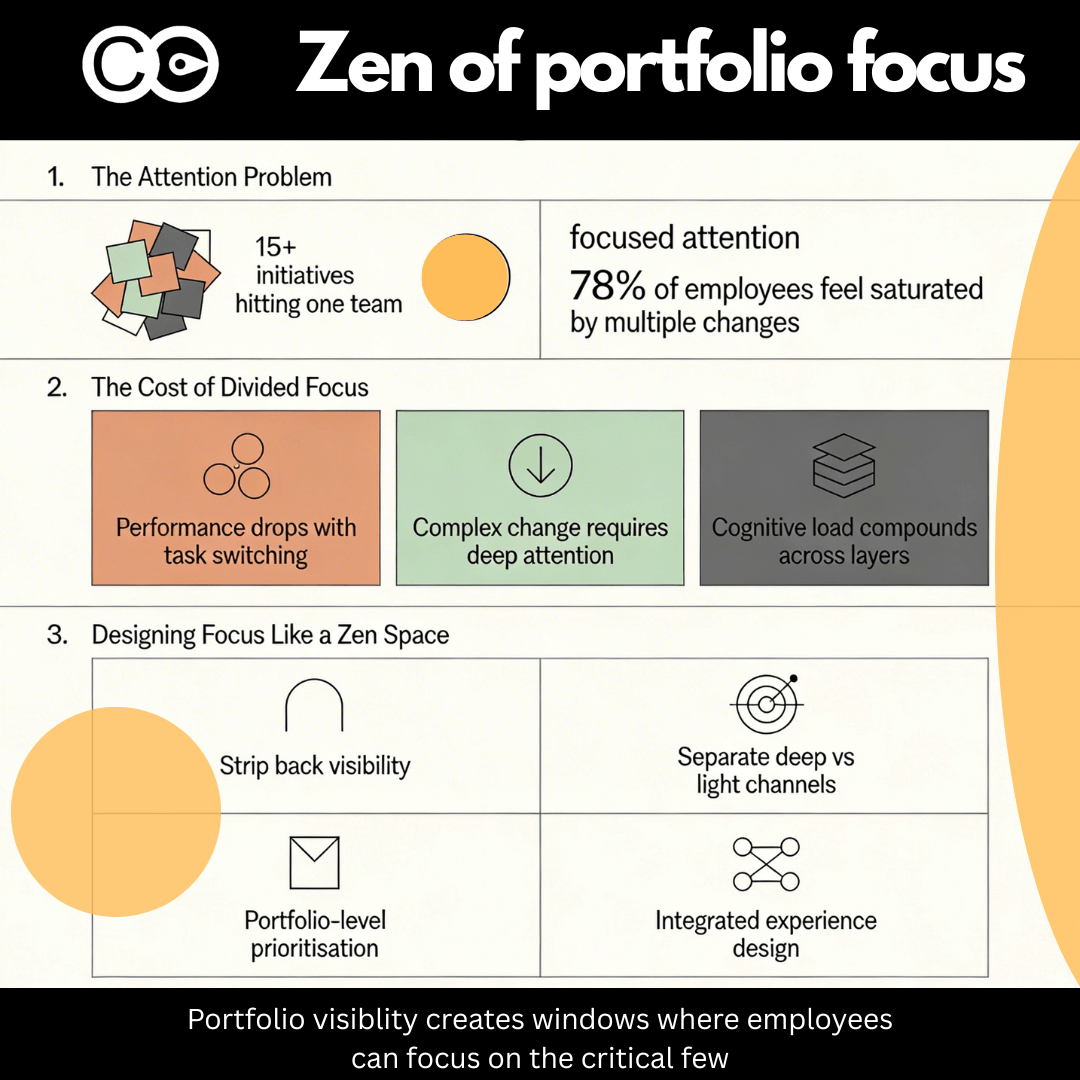
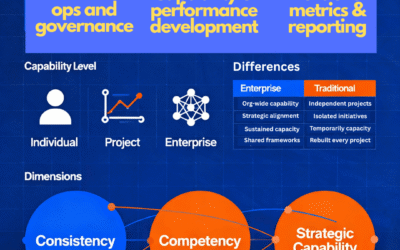
Financial services transformation refers to the structured programmes through which banks, insurers, wealth managers and capital markets firms reshape how they deliver value, manage risk and operate at the front, middle and back office. It is not a single category of...