Data-driven change management: why methodology alone is no longer enough
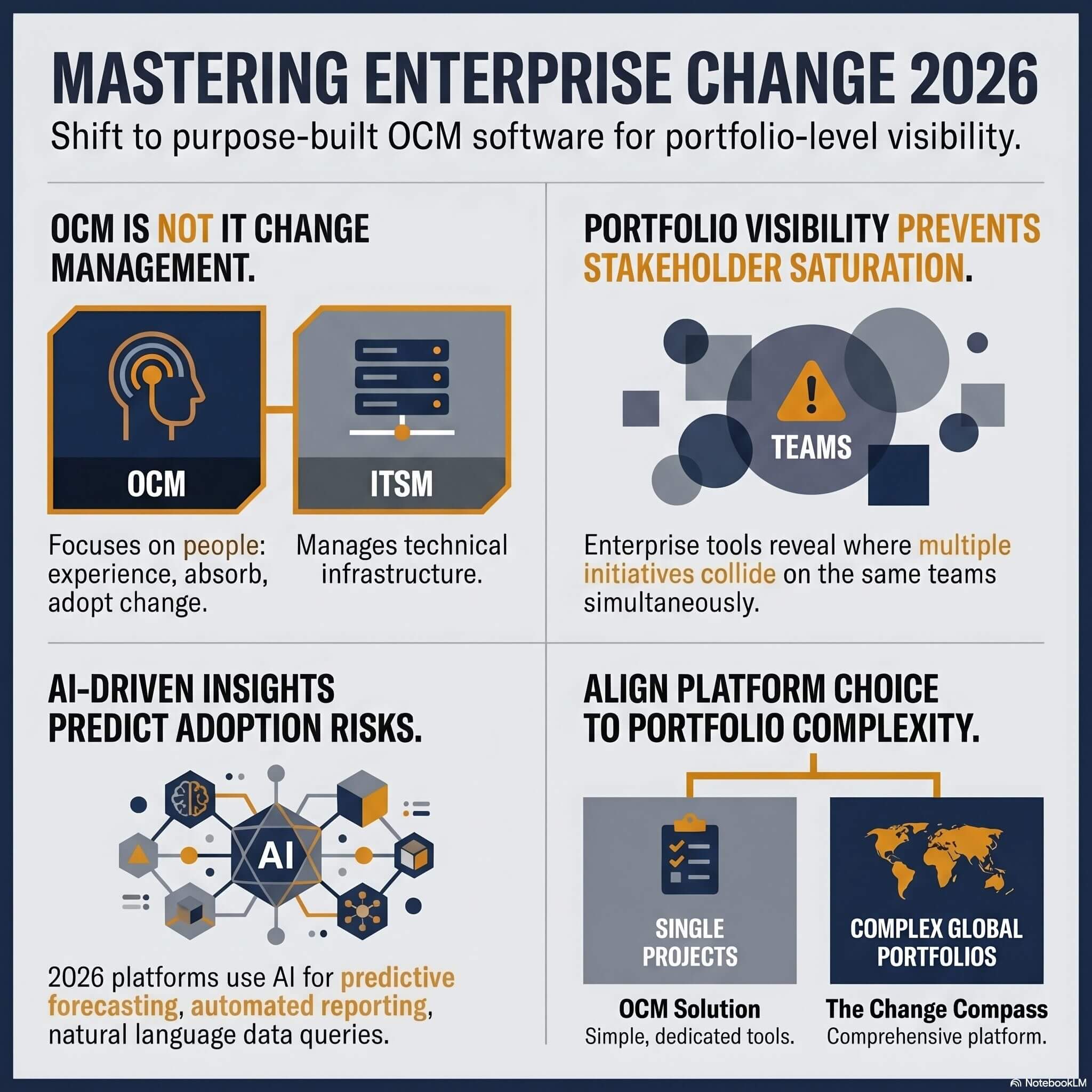
For the first twenty years of change management as a discipline, the primary question practitioners wrestled with was methodological: how do you follow the right sequence of steps to prepare people for change? The frameworks that emerged from that era, Kotter’s eight steps, Prosci’s ADKAR model, McKinsey’s influence model, were responses to a genuine gap. Most organisations had no structured approach to the people side of transformation at all.
That gap has largely closed. Most large organisations now have a change methodology. Many have multiple. The question that is keeping enterprise change leaders up at night in 2026 is not whether they have a methodology. It is whether they have the data to apply it intelligently.
Data-driven change management is not a rejection of methodology. It is the layer above it: the capability to determine where to focus the methodology, at what intensity, for which groups, and at what point in the change journey. Without that data layer, even the most sophisticated change methodology is applied with the same rough instrument to every situation, a guaranteed recipe for wasted effort and missed risk.
What methodology-only change management gets wrong
A methodology gives change practitioners a process to follow. It tells them what to do. Data tells them where, when, and how much. Without data, practitioners are making three critical assumptions that are rarely examined:
Assumption 1: All affected groups are equally at risk. Most change management plans allocate support resources proportionally to the number of people affected by a programme, rather than to the groups where adoption risk is highest. Without data on which groups face the steepest behaviour change, the most significant system transition, or the highest concurrent change load, this is the only allocation logic available.
Assumption 2: Readiness can be assessed by activity completion. The dominant measure of readiness in methodology-driven change management is whether change activities have been completed: training sessions delivered, communications sent, awareness workshops run. This tells you what the change team has done. It does not tell you whether the people receiving those activities are actually ready to perform differently.
Assumption 3: Problems will become visible quickly enough to respond. In a methodology-only model, problems typically surface when adoption starts to fail: after go-live, when the business begins to notice that new processes are not being followed or systems are not being used as designed. By that point, the cost of intervention is substantially higher than if the risk had been visible three months earlier.
A 2024 analysis of change management outcomes published by Deloitte found that organisations using data to guide their change strategy consistently outperform those relying on methodology alone, particularly on adoption speed and sustained behaviour change. The differential is not because data-driven organisations use better methodologies. It is because they apply their methodology more precisely.
What data-driven change management actually means
Data-driven change management is the practice of using systematically collected and analysed data to inform change strategy, prioritise change management effort, and monitor change outcomes in real time.
The phrase is widely used and frequently misunderstood. Having a stakeholder assessment spreadsheet is not data-driven change management. Sending a post-training survey with a satisfaction score is not data-driven change management. What distinguishes genuinely data-driven practice from these activities is the following:
- The data is collected consistently using standardised instruments, not ad hoc
- The data is aggregated across the portfolio, not siloed at the programme level
- The data is used to make decisions, not just to report on activity
- The data is analysed to surface patterns and risks, not just compiled into summaries
This distinction matters because many change functions believe they are data-driven because they produce reports. Reports are an output of data collection. Data-driven change management is about whether those reports change what happens next: whether they shift priorities, redirect resources, or trigger governance conversations about sequencing and scope.
The data types that matter most in change management
Not all change data is equally valuable. Understanding the data types that most reliably predict change outcomes helps change functions invest their measurement effort where it counts.
Impact and load data
The starting point of data-driven change management is an accurate, up-to-date picture of the change landscape: which groups are affected by which programmes, how significantly, and across which dimensions of change (process, system, role, behaviour, environment). This impact data is the raw material for everything else.
When impact data is aggregated across the portfolio, it becomes load data: the cumulative change demand on each stakeholder group at any point in time. Load data is the single most important predictor of saturation risk and the foundation of intelligent resource allocation. Without it, programme teams operate in isolation, each unaware of what other programmes are simultaneously asking of the same people.
Readiness data
Readiness data measures whether affected groups are prepared to perform differently when change lands. Useful readiness data goes beyond satisfaction with training. It assesses role-specific confidence in performing new tasks, manager preparedness to support their teams through the transition, and leadership alignment on the purpose and expectations of the change.
Readiness data is most valuable when it is collected early enough to act on. Readiness surveys completed two weeks before go-live are informational. Readiness data collected eight weeks before go-live, with a clear threshold below which intervention is triggered, is operational.
Adoption data
Adoption data measures whether change is actually sticking after go-live. For system changes, this typically includes usage metrics from the technology platform. For process changes, it includes adherence rates and quality indicators. For behaviour and cultural changes, it includes manager observations and pulse survey data.
McKinsey’s research on organisational agility identifies sustained adoption as the point at which change value is actually realised. Programmes that achieve technical go-live but fail to embed new behaviours do not deliver their projected benefits, regardless of how well the methodology was executed.
Sentiment and leading indicator data
Sentiment data fills the gap between structured survey cycles: real-time signals from employee feedback, manager escalations, support ticket categories, and participation rates in change activities. These leading indicators flag emerging problems before they show up in adoption metrics.
The value of sentiment data is in its speed. A spike in employee queries about a particular new process can indicate confusion that, if addressed within days, can be resolved before it becomes a pattern of non-adoption.
The difference data makes to change decisions
The practical impact of data-driven change management shows up in specific decisions that cannot be made well without it.
Resource allocation decisions. Without data, change management resources are typically allocated by programme size or budget. With load and readiness data, they can be directed to the groups where the risk is highest: the teams facing two major system transitions simultaneously, the business unit whose readiness scores have fallen three survey cycles in a row, the manager cohort that has not yet engaged with the change process at all.
Sequencing and timing decisions. Programme go-live dates are typically set by technology readiness, budget cycles, and executive preferences. Data on cumulative change load gives portfolio governance the evidence to make sequencing decisions on behalf of employee capacity, not just delivery convenience. This is the intervention that most directly prevents saturation.
Scope decisions. When data shows that a particular group is already at high saturation risk, the case for phasing the scope of a change landing on them, releasing essential changes first and adding complexity in subsequent phases, becomes objectively demonstrable rather than a judgement call that programme teams can dismiss.
Intervention targeting. Adoption data disaggregated by group, role, and geography identifies not just whether adoption is below target but exactly where. A targeted intervention for a specific team in a specific site is far more efficient than a blanket reinforcement campaign rolled out across the entire programme population.
Executive conversations. Change management has historically struggled to hold its ground in governance conversations with executives who are focused on schedule and cost. Data changes this. A change leader who can show a saturation risk score for a business unit, supported by load analysis and readiness trend data, is having a fundamentally different conversation than one who is making a subjective argument about “too much change.”
Building the data infrastructure for data-driven change management
The shift to data-driven change management requires more than a new mindset. It requires an infrastructure that makes consistent data collection and aggregation practical at scale.
The three components of that infrastructure are:
Standardised data collection tools. Every programme change impact assessment, readiness survey, and adoption tracking instrument needs to collect data in a consistent format. Without standardisation, aggregation is impossible. This is a foundational investment that pays dividends every time a new programme is launched.
A centralised data platform. Change data that lives in individual programme folders cannot be aggregated or analysed at the portfolio level. A shared platform where programme-level data flows into a portfolio view is the difference between a change function that can see the whole system and one that is working in the dark.
Analytical capacity within the change function. Data is only valuable when someone can analyse it and translate the analysis into recommendations. Dedicated change analyst roles, separate from programme delivery, are the emerging solution in enterprise change functions that have reached this level of maturity.
Research on data-driven enterprise capability from McKinsey finds that organisations with genuine data-driven capability in their operational functions are 23 times more likely to acquire customers and six times more likely to retain them than their peers. The same underlying capability differential applies within the change function: data-driven change management does not just produce better reports. It produces better outcomes.
Why data-driven change management is a competitive differentiator
The organisations that have invested in data-driven change management are building a capability that compounds over time. Each programme generates data that improves the accuracy of future impact assessments. Each adoption cycle produces evidence that refines the relationship between change load, intervention intensity, and outcome. Each saturation risk assessment that leads to a sequencing decision builds the political capital to make the next one.
This is the compounding advantage that methodology alone cannot replicate. A change methodology is a static set of steps. A data-driven change function is a learning system that becomes more precise with every programme it runs.
The implications for enterprise change functions are significant. Organisations investing in data-driven change capability now will be able to manage increasingly complex transformation portfolios with more confidence, less waste, and better outcomes than organisations that are still relying on methodological frameworks as their primary instrument.
For change leaders making the case for this investment to CFOs and CHROs, the business argument is straightforward. Prosci research on the correlation between change management and project success consistently shows that projects with excellent change management are six times more likely to meet objectives than those with poor change management. Data-driven change management is what makes the difference between good change management intentions and excellent change management outcomes.
How The Change Compass supports data-driven change management
Purpose-built platforms are what make data-driven change management practical at enterprise scale. Change Compass provides the data infrastructure that enterprise change functions need to aggregate impact data across the portfolio, visualise cumulative change load by stakeholder group, track readiness and adoption metrics in real time, and generate the executive reporting that keeps saturation risk visible to governance.
The platform is designed specifically for the challenge that methodology-only change management cannot address: seeing the whole portfolio at once, across all programmes, for all affected groups, in a format that drives decisions rather than just documents activity. The Change Automator extends this with workflow automation that reduces the manual overhead of keeping portfolio data current.
For change functions at the beginning of the data-driven journey, the weekly demo provides a practical demonstration of what portfolio-level change analytics looks like in a live environment.
The shift that actually changes outcomes
Methodology got the change management discipline to where it is. Data will take it where it needs to go.
The organisations that will manage the increasing pace and complexity of enterprise transformation over the next decade are those that have built the capability to use data to direct their change effort with precision: to see where risk is building before it becomes a crisis, to allocate resources based on evidence rather than assumption, and to demonstrate outcomes in the language that boards and executive teams can act on.
The shift from methodology-driven to data-driven change management is not a replacement. It is an evolution. The methodology still matters. But without data to guide its application, it will continue to produce the uneven, unpredictable outcomes that have made change management a challenging discipline to resource and justify.
Frequently asked questions
What is data-driven change management?
Data-driven change management is the practice of using systematically collected and analysed data to direct change strategy, allocate change management resources, and monitor change outcomes in real time. It goes beyond activity completion tracking to measure where adoption risk is highest, which groups are approaching saturation, and where readiness is falling short of the threshold needed for successful go-live.
How is data-driven change management different from traditional change management?
Traditional or methodology-driven change management follows a defined process regardless of the specific risk profile of the change and the affected groups. Data-driven change management uses impact, readiness, and adoption data to apply the methodology precisely: directing resources to the highest-risk groups, timing interventions based on leading indicator signals, and making sequencing and scope decisions based on evidence of employee capacity.
What data should change management functions be collecting?
The most valuable data types are: change impact and load data (which groups are affected, how significantly, across how many concurrent programmes), readiness data (whether groups are prepared to perform differently before go-live), adoption data (whether changes are sticking after go-live), and sentiment and leading indicator data (real-time signals of emerging risk between formal survey cycles).
What tools do you need for data-driven change management?
The foundational tools are standardised data collection templates applied consistently across all programmes, a shared data platform that enables portfolio-level aggregation, and visualisation tools that present cumulative change load and adoption trends in an executive-ready format. Purpose-built platforms like Change Compass are designed specifically to provide this infrastructure without requiring change functions to build it from scratch.
How does data-driven change management improve adoption outcomes?
By identifying where adoption risk is highest before go-live, data-driven change management enables earlier, more targeted intervention. Rather than deploying a uniform support programme across all affected employees, change resources are directed to the groups that data shows are least ready, most saturated, or falling furthest behind on adoption trajectory. This precision reduces both waste and missed risk.
References
- Deloitte Insights. (2024). Data’s role in effective change. https://action.deloitte.com/insight/3313/datas-role-in-effective-change
- McKinsey & Company. (2025). The data-driven enterprise of 2025. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-data-driven-enterprise-of-2025
- McKinsey & Company. (2024). The journey to an agile organisation. https://www.mckinsey.com/capabilities/people-and-organizational-performance/our-insights/the-journey-to-an-agile-organization
- Prosci. (2024). The Correlation Between Change Management and Project Success. https://www.prosci.com/blog/the-correlation-between-change-management-and-project-success
- Taylor & Francis. (2025). Change management and organisational performance: current key trends. https://www.tandfonline.com/doi/full/10.1080/23311975.2025.2478447