Conducting a change readiness assessment is the practical process of evaluating, before a change goes live, whether each affected stakeholder group has the capacity, capability, commitment and conditions in place to absorb the change successfully. The step-by-step approach starts with defining what readiness means for this specific change, then segments the affected population, captures data from multiple sources (workload metrics, sentiment surveys, manager input, historical capacity data), scores each group against readiness criteria, and translates the results into specific intervention actions for low-readiness groups. The output is not a single score, but a prioritised action plan with named owners.
That number should give every change manager pause. Because the most common readiness tool in most organisations is a pre-launch survey, sent three weeks before go-live, with a 40% response rate and results that confirm what the project team already suspected. That is not readiness assessment. That is a post-rationalisation exercise.
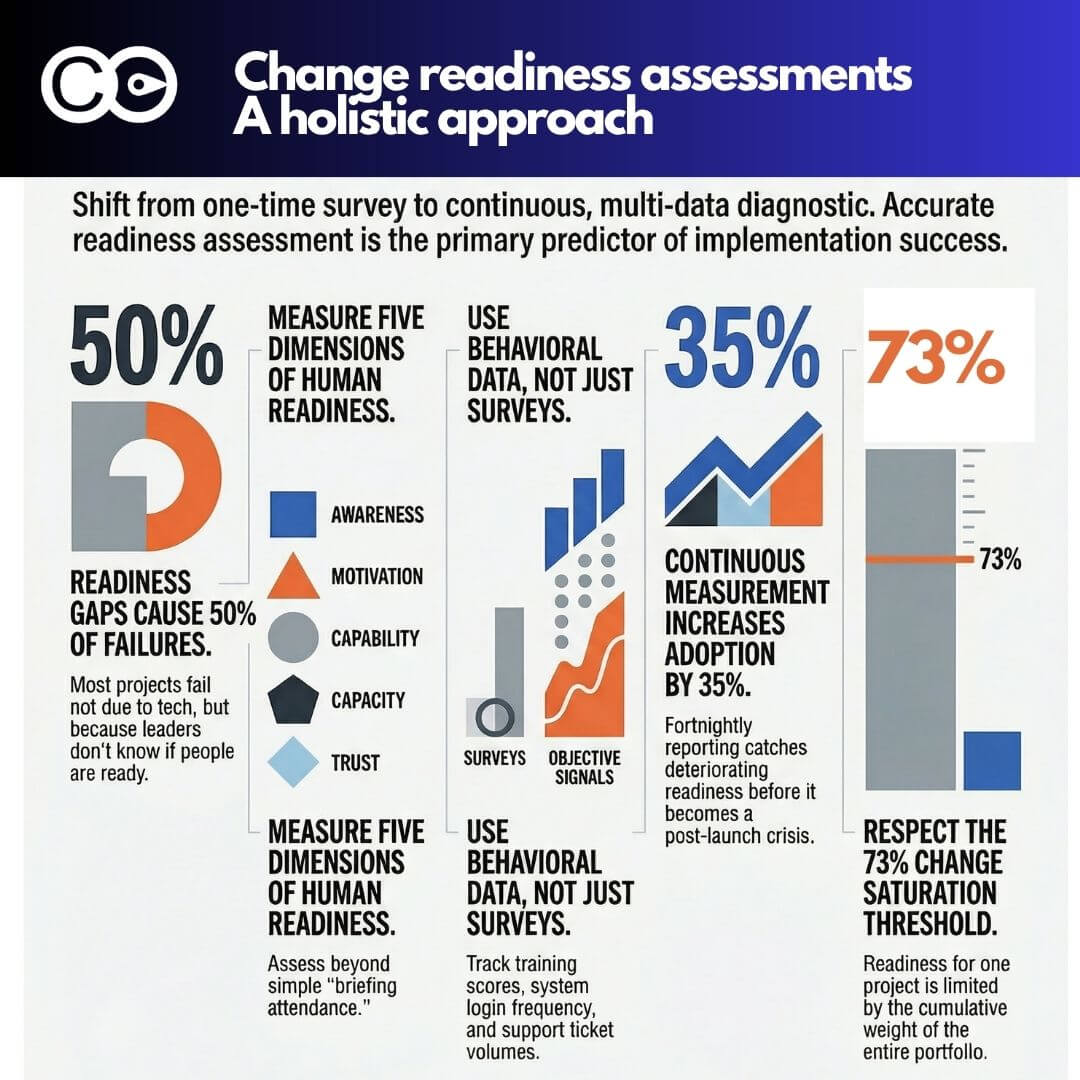
Genuine change readiness is a dynamic, multi-dimensional condition. It reflects whether employees have the awareness, motivation, capability, and psychological bandwidth to adopt a specific change right now, not just whether they attended a briefing session and ticked a box. And critically, it is shaped not only by their attitudes toward your particular initiative, but by everything else being asked of them simultaneously across the entire change portfolio.
This guide sets out a practical, evidence-based approach to change readiness assessment: one that goes well beyond the survey, incorporates behavioural and system data, uses AI to accelerate synthesis, and accounts for the cumulative weight of change that real employees actually carry.
Why readiness is the real precursor to adoption
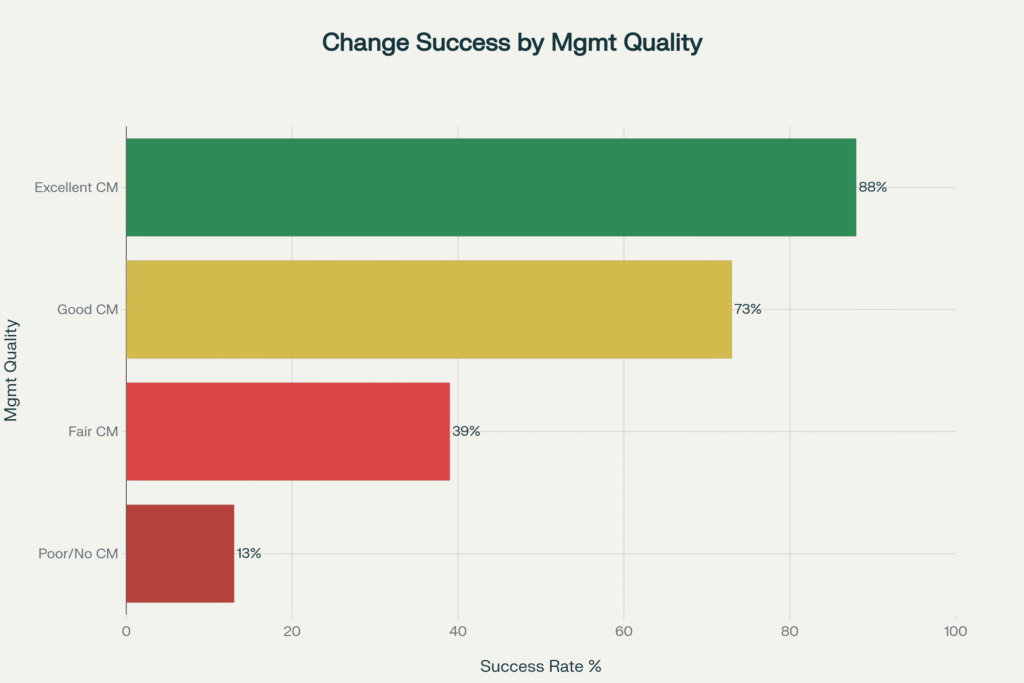
There is a persistent assumption in change management circles that adoption follows awareness. Build enough awareness, communicate clearly, and people will eventually adopt. The evidence does not support this. Prosci’s longitudinal research, drawing on more than 8,000 data points from organisations globally, shows that initiatives with excellent change management are six times more likely to meet their objectives than those with poor change management, and that the jump from awareness to actual behavioural change is where most programmes falter.
The ADKAR model is instructive here. Awareness and Desire are prerequisites for Knowledge, but Knowledge does not automatically produce Ability. People can understand exactly what a change requires and still be unable or unwilling to do it. Readiness sits squarely in that gap between knowing and doing. It is the accumulated condition of a person at a specific point in time: their confidence, their capacity, their trust in leadership, their workload, and their sense of whether this change is worth the effort it demands.
The Prosci research is unambiguous: when change management is applied with excellence, approximately 80% of projects meet or exceed their objectives. With poor or absent change management, that figure drops to 14%. The readiness assessment is your early-warning mechanism for which trajectory you are on.
What makes readiness especially critical is its predictive value. A readiness gap identified six weeks before go-live is actionable. The same gap identified two weeks post-launch is a crisis. Organisations that conduct continuous readiness measurement, rather than a single pre-launch snapshot, achieve 25–35% higher adoption rates than those relying on one-time assessment. Readiness is not a checkbox on a project plan. It is a continuous diagnostic.
The problem with survey-only readiness assessment
Surveys are useful. They are scalable, they are comparable over time, and when designed well they can surface genuine sentiment. But as the sole readiness instrument, they have serious limitations that most organisations overlook.
First, surveys measure declared intent, not demonstrated behaviour. A person can respond positively to “I feel confident using the new system” and still default to the old process when the pressure is on. The intention-behaviour gap is well documented in psychology: what people say they will do and what they actually do are often quite different, particularly in high-pressure or ambiguous environments.
Second, surveys are a lagging signal. By the time results are collated and reported, the organisation has moved on. Conditions change fast, particularly when multiple initiatives are running concurrently and team-level dynamics shift week by week.
Third, response rates and response bias skew the picture. Those most likely to respond to a readiness survey are often those with the strongest views: either enthusiastic adopters who inflate the readiness score, or disengaged resistors who depress it. The large silent middle, whose readiness is often the critical variable, is systematically underrepresented.
Finally, surveys can tell you that a readiness gap exists but rarely why it exists. Knowing that 42% of respondents feel “not confident” with the new process is interesting. Understanding whether that is driven by inadequate training, distrust of leadership, competing priorities, or unclear role expectations requires a different kind of data entirely.
A multi-method framework for change readiness assessment
Robust readiness assessment treats the survey as one of several data sources, not the primary one. The framework below sets out a step-by-step approach that change managers can apply to any initiative, from a technology rollout to a structural reorganisation.
Step 1: define the readiness dimensions for your specific change
Before deploying any assessment method, clarify what readiness actually means for this change. Generic readiness scales are rarely sufficient. An ERP implementation demands different readiness than a culture change programme. For each initiative, identify the specific dimensions you need to assess. These typically include:
Awareness: Do people understand what is changing, why, and what it means for their role?
Motivation: Do people see a personal benefit or at least a compelling reason to engage?
Capability: Do people have the skills, knowledge, and tools required to operate in the new way?
Capacity: Do people have the time and bandwidth to absorb this change given their current workload?
Trust and confidence: Do people trust that the change is being well-managed and that leadership is genuinely committed?
This scoping step prevents you from measuring the wrong things and ensures your assessment data connects directly to actionable interventions.
Step 2: use surveys as one signal, not the signal
Design your readiness survey around the specific dimensions you identified in Step 1, not a generic template. Keep it short (eight to twelve questions maximum), include at least two open-text questions to surface qualitative nuance, and run it at multiple points rather than once. Segment results by team, location, role, and manager, because aggregate scores mask the local variation that drives or blocks adoption.
Critically, build in a follow-up protocol for low-readiness scores. A survey that identifies a problem but triggers no response is worse than no survey at all: it signals to employees that their concerns were collected and ignored.
Step 3: gather behavioural and system data
This is where most change readiness assessments have a blind spot, and where the most honest picture of readiness lives. Behavioural and system data reflects what people are actually doing rather than what they say they will do.
Depending on your change, this data might include:
Training completion rates and assessment scores: Not just whether people attended, but how they performed. Low scores in required competency modules are a direct readiness signal.
System adoption data: Login frequency, feature utilisation, process completion rates, and error rates in new systems. These are real behavioural readiness indicators that most organisations already collect but rarely route to change teams.
Help desk and support ticket volumes: Spikes in support requests after go-live indicate either inadequate readiness or inadequate training design. Tracking ticket categories reveals exactly where readiness gaps are concentrated.
Process compliance data: Are people following the new process or reverting to old workarounds? Audit trails in systems like CRM, ERP, or workflow tools can reveal this directly.
Attendance and participation in change activities: Who is attending information sessions, completing pre-work, or engaging with change networks? Absence from these touchpoints is a passive readiness signal.
The discipline here is routing this data to change managers in near-real time, rather than leaving it siloed in IT systems or HR platforms where it is never seen through a readiness lens.
Step 4: conduct manager sensing and pulse reporting
Frontline and middle managers see readiness in ways that no survey can capture. They hear the informal conversations, notice who is quietly resistant, observe who needs extra support, and understand the team-level dynamics that shape how change lands.
Structured manager sensing involves regular (typically fortnightly) brief check-ins where managers report on a small number of consistent indicators: team sentiment, specific concerns raised, any behavioural changes in response to the upcoming change, and their own confidence in supporting the transition. This data should be structured enough to aggregate and compare across the organisation, but lightweight enough that managers will actually complete it.
Some organisations go further, using pulse tools that ask managers to rate team readiness across two or three dimensions on a simple scale, providing a running heatmap of readiness by team and location. This kind of continuous sensing is far more valuable than a single pre-launch survey, because it catches deteriorating readiness before it becomes an adoption problem.
Step 5: run diagnostic workshops and focus groups
Workshops serve a function that no quantitative method can replicate: they allow you to probe, test assumptions, and hear the reasoning behind attitudes. A well-facilitated readiness workshop with a cross-section of impacted employees will surface the specific concerns, misconceptions, capability gaps, and workload pressures that are shaping readiness in that part of the organisation.
Structured focus groups, particularly with sceptics or resistors, are especially valuable. These conversations often reveal systemic issues that no survey would capture: a lack of trust in a specific leader, a process design flaw that makes the new way harder than the old way, or a team-specific constraint that the broader programme has failed to account for.
Readiness workshops also serve a secondary purpose: they are themselves a readiness-building intervention. When employees feel heard, when their concerns are taken seriously and addressed directly, their readiness to engage with the change typically improves.
Step 6: synthesise signals into a dynamic readiness picture
The final step is the one most organisations skip. Gathering data from five different sources is useful only if that data is brought together into a coherent, interpretable picture of readiness at the group level and across the initiative’s lifecycle.
A readiness synthesis should map across the dimensions you defined in Step 1, draw on all your data sources, and be updated at meaningful intervals (typically fortnightly during an active change period). It should identify which groups are ready, which are borderline, and which are at risk, along with a clear articulation of the specific readiness gaps driving each risk rating. That synthesis is the document your sponsor and project team should be reviewing at every steering committee meeting.
The cumulative change problem: how your portfolio shapes readiness for any single initiative
Here is the readiness problem that change management programmes most consistently underestimate: the readiness of your people for this change is not determined solely by this change. It is shaped by everything else they are being asked to absorb simultaneously.
Research consistently shows that 73% of organisations are at or near their change saturation point: the threshold where concurrent initiatives overwhelm staff capacity and the ability to absorb any individual change, regardless of its quality, diminishes sharply. And the consequences are significant. Among employees experiencing high change fatigue, 54% are actively looking for new roles, compared to just 26% of those experiencing low fatigue, a retention gap of nearly 30 percentage points that is directly attributable to change overload.
The implication for change readiness assessment is significant. You cannot assess readiness for your ERP implementation without accounting for the fact that the same people are simultaneously navigating a restructure, a new performance management system, and an office relocation. Each of those initiatives consumes cognitive and emotional bandwidth. Each creates its own uncertainty and anxiety. And each reduces the available capacity for your initiative.
A change manager who assesses readiness in isolation from the broader change portfolio is working with an incomplete picture. They may diagnose low readiness for their initiative when the real issue is systemic change saturation: people who are fundamentally willing to adopt the new system but who simply do not have the bandwidth to engage with yet another change right now.
This demands a portfolio-level view of readiness. Organisations need to understand not just whether people are ready for a specific change, but what the cumulative change load looks like from the employee’s perspective, and how that load is distributed across different teams and roles.
Viewing readiness through the employee lens across the full change landscape
The most useful shift in perspective for any change readiness assessment is to move from the initiative view to the employee view. Instead of asking “are people ready for this change?”, ask “what does the full change picture look like for someone in this role right now, and does that picture leave them with the capacity and motivation to adopt this particular change?”
This means mapping the full set of changes affecting each impacted group, assessing the cumulative impact and demand on their time, and using that as the baseline against which you interpret readiness data for any individual initiative. A team that shows moderate readiness for your project but is simultaneously navigating three other significant changes is in a fundamentally different situation from a team with the same readiness score but minimal other change exposure.
The employee-centric view of readiness also reveals sequencing opportunities that an initiative-by-initiative assessment misses. If two high-impact changes are arriving at the same time for the same group of people, that is not a readiness problem, it is a scheduling problem, and the right intervention is timing adjustment rather than more training.
Organisations that adopt this perspective tend to make materially better decisions about go-live timing, phasing, and the allocation of change management resources. Rather than deploying equal effort across all initiatives regardless of context, they concentrate support where the cumulative load is highest and where readiness gaps are most pronounced.
How AI is transforming readiness intelligence
The traditional barriers to multi-method readiness assessment have been time and synthesis capacity. Gathering data from five sources, segmenting it by group, and producing a coherent readiness picture every two weeks was genuinely burdensome for most change teams. AI is materially changing this equation.
Large language models and AI-assisted analytics tools can now process qualitative survey responses at scale, automatically coding open-text comments by theme and sentiment, identifying patterns that would take a human analyst days to surface. A free-text comment from 400 survey respondents can be synthesised in minutes, with the most common concerns ranked, the strongest language flagged, and the themes segmented by business unit.
Predictive analytics applied to system and behavioural data can generate early-warning signals before readiness problems become visible to the naked eye. Drops in training assessment scores, spikes in specific support ticket categories, or declining engagement with change communications can all be weighted and combined into a predictive readiness score that alerts the change manager before go-live.
Natural language processing applied to collaboration platforms, such as workplace chat or internal forums, can provide a passive sentiment signal that reflects how employees are actually talking about a change in their day-to-day interactions, a very different and often more candid data source than anything they would submit in a formal survey.
The 2024 State of AI Change Readiness research by Microsoft found that the biggest barrier to AI adoption within organisations is not technological, it is leadership, and specifically the gap between leader confidence and actual employee readiness. That finding applies equally to AI-assisted readiness tools: the technology is available, but change teams need to actively embed it into their practice rather than waiting for it to arrive pre-packaged.
AI does not replace the human judgment required to interpret readiness data and design appropriate interventions. But it does dramatically accelerate the data collection, synthesis, and signal-detection work that currently consumes the majority of a change manager’s analytical time.
Using digital tools to maintain a dynamic view of readiness
For organisations managing multiple initiatives simultaneously, maintaining a dynamic, portfolio-level view of readiness requires more than spreadsheets and periodic reports. Digital change management platforms like Change Compass are specifically designed to provide this visibility, allowing change managers to track readiness indicators across multiple initiatives, overlay cumulative change impact data, and view readiness from the employee-centric perspective rather than the initiative view. The platform’s ability to aggregate multiple data inputs and present a real-time change load picture across the organisation makes the kind of portfolio-level readiness analysis described in this article genuinely scalable, rather than something that only the best-resourced programmes can afford to do.
Conclusion
Change readiness assessment is not a compliance activity or a project milestone to tick off. It is the most important predictive mechanism a change manager has, and the quality of that assessment is what separates teams that catch adoption problems early from teams that spend the post-launch period firefighting.
The shift required is from single-method, point-in-time assessment to a multi-method, continuous, employee-centric approach that accounts for the full change landscape people are navigating. That means triangulating surveys with system data, manager reports, behavioural signals, and workshop diagnostics. It means maintaining a portfolio-level view of cumulative change load. And it means using AI to accelerate synthesis so that readiness intelligence is available when it is needed, not three weeks after the window for intervention has closed.
Start with your current initiative. Define the readiness dimensions that matter. Map all five data collection methods. Build the portfolio-level overlay. That is the step from readiness assessment as a ritual to readiness assessment as a genuine strategic tool.
Frequently asked questions
What is a change readiness assessment?
A change readiness assessment is a structured process for evaluating whether employees and the organisation as a whole are prepared to adopt a specific change. It examines dimensions including awareness, motivation, capability, capacity, and trust. Effective assessments use multiple data sources, not just surveys, to build an accurate and actionable picture.
How is change readiness different from change adoption?
Readiness is a precondition for adoption: it describes the state of preparedness before and during a change, while adoption describes the demonstrated behavioural change that results from successful implementation. You assess readiness to predict and influence adoption outcomes. Low readiness, if unaddressed, reliably produces low adoption.
How often should change readiness be assessed?
Research indicates that organisations using continuous measurement rather than single-point assessments achieve significantly higher adoption rates. For active change initiatives, readiness should be assessed at meaningful intervals throughout the implementation lifecycle, typically fortnightly, with rapid-signal methods (manager sensing, system data) running continuously in between.
What is change saturation and how does it affect readiness?
Change saturation occurs when the cumulative volume of concurrent changes exceeds an organisation’s capacity to absorb them. Research indicates 73% of organisations are already at or near this threshold. Saturation directly undermines readiness for any individual initiative by consuming the cognitive and emotional bandwidth employees need to engage with and adopt a specific change.
How can AI support change readiness assessment?
AI can significantly accelerate readiness data collection and synthesis. Applications include automated thematic analysis of open-text survey responses, predictive analytics applied to system usage and support ticket data, passive sentiment analysis from internal collaboration platforms, and real-time dashboards that aggregate multiple readiness signals into an interpretable summary for change managers and sponsors.
“Is the project on track?” “Are we hitting milestones?” “What’s the budget status?”
Here’s the question almost no one asks:
“What is this change doing to our operational performance right now?”
Not after go-live. Not in a post-implementation review. Right now, during the transition, while people are absorbing the change and running the operation simultaneously.
The silence around this question reveals a fundamental blind spot in how organisations manage transformation. Everyone assumes there will be a temporary productivity dip. They accept it as inevitable. But almost no one measures it. No one knows if it’s a 5% dip or a 25% dip. No one tracks how long recovery takes. And when you’re running multiple changes across the enterprise, those dips stack, compound, and create operational crises that leadership only discovers after significant damage has occurred.
The research on performance dips: what we know and what we ignore
The phenomenon of performance decline during organisational change is well-documented. Research consistently shows measurable productivity drops during implementation periods, yet few organisations actively track these impacts in real time.
The magnitude of performance loss
Studies examining various types of change initiatives reveal striking patterns:
ERP implementations: Performance dips range from 10% to 25% on average, with some organisations experiencing dips as high as 40%.
Enterprise system implementations: Productivity losses range from 5% to 50% depending on the organisation and system complexity.
Electronic health record (EHR) systems: Performance dips can reach 5% to 60%, particularly when high customisation is required.
Digital transformations: McKinsey research found organisations typically experience 10% to 15% productivity dips during implementation phases.
Supply chain systems: Average productivity losses sit at 12%.
These aren’t marginal impacts. A 25% productivity dip in a customer service operation processing 10,000 transactions weekly means 2,500 fewer transactions completed. A 15% dip in a manufacturing environment translates directly to output reduction, delayed shipments, and revenue impact. Yet most organisations discover these impacts only after they’ve compounded into visible crises.
Why performance dips occur
The mechanisms behind performance decline during change are well understood from cognitive and operational perspectives:
Cognitive load and task switching: Research on divided attention shows that complex tasks combined with frequent switching between demands significantly degrade performance. Employees navigating new systems whilst maintaining BAU operations experience measurable increases in error rates and reaction times.
Learning curves and proficiency gaps: Even with comprehensive training, real-world application of new processes reveals gaps between classroom scenarios and operational reality. The proficiency developed in controlled training environments doesn’t immediately transfer to production complexity.
Workaround proliferation: When new systems don’t match actual workflow requirements, employees develop workarounds. These workarounds initially appear functional but create hidden dependencies, data quality issues, and cascading problems that surface weeks later.
Support capacity constraints: As implementation teams scale back intensive go-live support, incident resolution slows. Issues that were resolved in minutes during week one take hours or days by week three, compounding operational delays.
Change saturation: When multiple initiatives land concurrently, performance impacts don’t add linearly—they compound exponentially. Research shows that 48% of employees experiencing change fatigue report increased stress and tiredness, directly impacting productivity.
The recovery timeline reality
Without structured change management and continuous monitoring, organisations experience extended recovery periods. Research indicates:
Without effective change management: Productivity at week three sits at 65-75% of pre-implementation levels, with recovery timelines extending 4-6 months.
With effective change management: Recovery happens within 60-90 days, with continuous measurement approaches achieving 25-35% higher adoption rates than single-point assessments.
The difference isn’t marginal. It’s the difference between a brief, managed disruption and a prolonged operational crisis that undermines the business case for change.
The compounding problem: multiple changes, invisible impacts
The performance dip research cited above assumes a critical condition that rarely exists in modern enterprises: one change at a time.
Most organisations today manage portfolios of concurrent initiatives. A finance function implements a new ERP system whilst rolling out revised compliance processes and restructuring the shared services team. A healthcare system deploys new clinical documentation software whilst updating scheduling systems and migrating financial platforms. A telecommunications company launches customer portal changes whilst implementing billing system upgrades and operational support system modifications.
When concurrent changes overlap, impacts don’t simply add up, they multiply.
The mathematics of compound disruption
Consider a realistic scenario: Three initiatives land across the same operations team within 12 weeks:
Initiative A (customer data platform): Expected 12% productivity dip
Initiative B (revised underwriting workflow): Expected 15% productivity dip
Initiative C (updated operational dashboard): Expected 8% productivity dip
If these were sequential, total disruption time would span perhaps 18-24 weeks with three distinct dip-and-recovery cycles. Challenging, but manageable.
When concurrent, the mathematics change. Employees don’t experience 12% + 15% + 8% = 35% productivity loss. They experience cognitive overload that drives productivity losses exceeding 40-50% because:
Attention fragments across three learning curves simultaneously
Support capacity spreads thin across three incident response systems
Training saturation occurs as employees attend sessions for multiple systems without time to embed any
Workarounds interact as temporary solutions in one system create problems in another
Psychological capacity depletes as change fatigue sets in
Research confirms this pattern. Organisations managing multiple concurrent initiatives report 78% of employees feeling saturated by change, with change-fatigued employees showing 54% higher turnover intentions. The productivity dip becomes not a temporary disruption but a sustained operational degradation lasting months.
The visibility gap
Here’s the critical problem: Most organisations lack the data infrastructure to see this happening in real time.
Research shows only 12% of organisations measure change impact across their portfolio, meaning 88% lack fundamental data needed to identify saturation before it undermines initiatives. Without portfolio-level visibility, leaders discover compound disruption only after:
Customer complaints spike
Error rates become unacceptable
Revenue targets are missed
Employee turnover accelerates
Projects are declared “failures” despite solid technical execution
By then, the cost of remediation far exceeds the cost of prevention.
Why organisations don’t track operational performance during change
If the research is clear and the impacts are measurable, why do so few organisations track operational performance during transitions?
Assumption that disruption is inevitable
Many leaders treat productivity dips as unavoidable costs of change, like renovation dust. “We’re implementing a major system, of course there will be disruption.” This mindset accepts performance loss as fate rather than a variable that leadership actions can influence.
Research challenges this assumption. Studies show that whilst some disruption accompanies complex change, the magnitude and duration are directly influenced by how well the transition is managed. High-performing organisations experience minimal performance penalties precisely because they track, intervene, and course-correct based on operational data.
Lack of baseline data
You can’t measure a dip if you don’t know the baseline. Many organisations lack established operational metrics or track them inconsistently. When change arrives, there’s no reliable pre-change performance level to compare against.
Without baselines, statements like “adoption is going well” or “the team is adjusting” remain subjective assessments unsupported by evidence. Leaders operate on impression rather than data.
Measurement infrastructure gaps
Even organisations with operational metrics often lack systems to correlate performance changes with change activities. They know processing times have increased or error rates have risen, but they can’t pinpoint whether the cause is the new system rollout, the concurrent process redesign, seasonal volume spikes, or unrelated factors.
This correlation gap means operational performance remains in one dashboard, project status in another, and no integration connects them. Steering committees review project milestones without visibility into business impact.
Focus on project metrics over business outcomes
Traditional project governance emphasises activity-based metrics: milestones completed, training sessions delivered, defects resolved. These metrics matter for project execution but don’t answer the question executives actually care about: Is the business performing through this change?
Research from McKinsey shows organisations tracking meaningful operational KPIs during change implementation achieve 51% success rates compared to just 13% for those that don’t, making change efforts four times more likely to succeed when measurement focuses on business outcomes rather than project activities.
Change management credibility gap
When change practitioners report on soft metrics like “stakeholder sentiment” or “readiness scores” without connecting them to hard operational outcomes, they struggle to maintain executive attention. Leaders want to know: What is this doing to our operation? If change management can’t answer with data, the discipline loses credibility.
The solution isn’t to abandon readiness and adoption metrics, those remain essential. The solution is to connect them explicitly to operational performance, demonstrating that well-managed change readiness translates into maintained or improved business outcomes.
What to measure: identifying operational metrics that matter
The first step in tracking operational performance during change is identifying which metrics genuinely reflect business health. Not every metric matters equally, and tracking too many creates noise rather than insight.
The 3-5 critical metrics principle
Focus on the 3-5 operational metrics that matter most to the business. These should be:
Directly tied to business outcomes: Metrics that executive leadership already monitors for business health, not change-specific proxies.
Sensitive to operational disruption: Metrics that would visibly shift if people struggle with new systems or processes.
Measurable at appropriate frequency: Metrics you can track weekly or daily during peak disruption periods, not quarterly lagging indicators.
Understandable to all stakeholders: Metrics that don’t require explanation. “Processing time” is clear. “Readiness index” requires interpretation.
Operational metric categories by function
Different functions have different critical metrics. Here are examples across common areas:
Customer service and support operations:
Average handling time per transaction
First-call resolution rate
Customer satisfaction scores (CSAT)
Ticket backlog age and volume
Escalation rates to supervisors
Manufacturing and production:
Throughput volume (units per shift/day/week)
Cycle time from order to completion
Defect rates and rework percentages
Equipment utilisation rates
On-time delivery percentages
Finance and accounting:
Invoice processing time
Days sales outstanding (DSO)
Error rates in journal entries or reconciliations
Month-end close timeline
Payment processing accuracy
Sales and revenue operations:
Quote-to-order conversion time
Sales cycle length
Forecast accuracy
Pipeline velocity
Customer onboarding time
Healthcare clinical operations:
Patient wait times
Documentation completion rates
Medication error rates
Bed turnover time
Chart completion timeliness
Technology and IT operations:
System availability and uptime
Mean time to resolution (MTTR) for incidents
Change success rate
Deployment frequency
Service desk ticket volume
The specific metrics vary by industry and function, but the principle holds: choose metrics that executives already care about, that reflect operational health, and that would visibly shift if change is disrupting performance.
Leading vs lagging operational indicators
Operational performance measurement should include both leading indicators (predictive) and lagging indicators (confirmatory):
Leading indicators provide early warning of emerging problems:
Training completion rates relative to go-live timing
Support ticket volumes and trends
System login frequency and feature usage
Employee sentiment scores
Workaround documentation requests
Lagging indicators confirm actual outcomes:
Throughput volumes and processing times
Error rates and rework
Customer satisfaction scores
Revenue and cost performance
Quality metrics
Both matter. Leading indicators enable intervention before performance degrades visibly. Lagging indicators validate whether interventions worked.
How to establish baselines before change lands
Baselines are the foundation of meaningful performance measurement. Without knowing where you started, you can’t quantify impact or demonstrate recovery.
Baseline establishment process
Step 1: Identify the 3-5 critical operational metrics for the impacted function or team, using the principles outlined above.
Step 2: Determine baseline measurement period. Ideally, capture 8-12 weeks of pre-change data to account for normal operational variation. This reveals typical performance ranges rather than single-point snapshots.
Step 3: Document baseline performance. Calculate average performance, typical variation ranges, and any seasonal patterns. For example: “Average processing time: 4.2 minutes per transaction, typical range 3.8-4.6 minutes, with slight increases during month-end periods.”
Step 4: Establish thresholds for concern. Define what magnitude of change warrants intervention. A 5% dip might be acceptable and temporary. A 20% dip signals serious disruption requiring immediate action.
Step 5: Communicate baselines to governance. Ensure steering committees and leadership understand baseline performance and what “normal” looks like before change begins.
Baseline data sources
Where does baseline data come from? Most organisations already collect operational metrics—they just don’t use them for change impact assessment:
Operational dashboards and business intelligence systems: Most functions track performance metrics for ongoing management. Leverage existing data rather than creating parallel measurement systems.
Time and motion studies: For processes lacking automated measurement, conduct time studies during the baseline period to understand current performance.
Quality assurance and audit data: Error rates, defect rates, and compliance metrics often exist in quality systems.
Customer feedback systems: CSAT scores, Net Promoter Scores (NPS), and complaint volumes provide external validation of operational performance.
Financial systems: Cost per transaction, revenue per employee, and similar financial metrics reflect operational efficiency.
The goal isn’t to create new measurement infrastructure (though sometimes that’s necessary). The goal is to systematically capture and document performance levels before change disrupts them.
When baselines don’t exist
What if you don’t have historical operational data? You’re implementing change into a new function, or metrics were never established?
Option 1: Rapid baseline establishment. Implement measurement 4-6 weeks before go-live. Not ideal, but better than no baseline.
Option 2: Industry benchmarks. Use external benchmarks to establish expected performance ranges. “Industry average for similar operations is X; we’ll track whether we maintain that level through change”.
Option 3: Relative baselines. If absolute metrics aren’t available, track relative changes: “Week 1 post-change will be our baseline; we’ll track whether performance improves or degrades from that point”.
Option 4: Proxy metrics. If direct operational metrics don’t exist, identify proxies that correlate with performance: employee hours worked, system transaction volumes, customer contact rates.
None of these are as robust as established baselines, but all provide more insight than flying blind.
Tracking operational performance during the transition
Once baselines exist and change begins, systematic tracking transforms assumptions into evidence.
Measurement cadence during change
Pre-change (weeks -8 to 0): Establish and validate baselines. Ensure data collection processes are reliable.
Go-live week (week 1): Daily measurement. Performance during go-live is artificial due to hypervigilant support, but daily tracking captures immediate issues.
Peak disruption period (weeks 2-4): Daily or at minimum three times per week. This is when performance dips typically peak and when early intervention matters most.
Stabilisation period (weeks 5-12): Weekly measurement. Performance should trend toward baseline recovery. Persistent gaps signal unresolved issues.
Post-stabilisation (months 4-6): Biweekly or monthly measurement. Confirm sustained recovery and benefit realisation.
The frequency isn’t arbitrary. Research shows week two is when peak disruption hits as artificial go-live conditions end and real operational complexity surfaces. Daily measurement during this window enables rapid response.
Creating integrated performance dashboards
Operational performance data should integrate with change rollout timelines in unified dashboards visible to all governance forums.
Dashboard design principles:
Integrate operational and change metrics on one view. Left side shows project milestones and change activities. Right side shows operational performance trends. The correlation becomes immediately visible.
Use visual indicators for thresholds. Green (within acceptable variance), amber (approaching concern threshold), red (intervention required). Leaders grasp status at a glance.
Overlay change activities on performance trend lines. When a performance dip occurs, the dashboard shows which change activity coincided. “Error rates spiked on Day 8, coinciding with the process redesign go-live”.
Enable drill-down to detail. High-level executive dashboards show summary trends. Operational leaders can drill into specific teams, shifts, or transaction types.
Update in real-time or near-real-time. During peak disruption periods, yesterday’s data is stale. Automated feeds from operational systems provide current visibility.
Interpretation and intervention triggers
Data without interpretation is noise. Establish clear triggers for intervention:
Threshold 1: Acceptable variance (0-10% from baseline). Continue monitoring. Some variation is normal. No intervention required unless sustained beyond expected recovery window.
Threshold 2: Concern zone (10-20% from baseline). Investigate causes. Increase support intensity. Prepare contingency actions if deterioration continues.
Threshold 3: Critical disruption (>20% from baseline). Immediate intervention required. Options include: pausing additional changes, deploying emergency support resources, simplifying rollout scope, or reverting to previous state if business impact is severe.
These thresholds aren’t universal—they depend on operational criticality and baseline variability. A 15% dip in non-critical administrative processing might be tolerable. A 15% dip in patient safety metrics or financial controls is not.
Bringing operational data into steering committees
Measurement matters only if it drives decisions. That means bringing operational performance data into governance forums where change priorities and resources are allocated.
Shifting the steering committee conversation
Traditional steering committee agendas focus on project status:
Milestone completion
Budget and timeline status
Risk and issue logs
Upcoming deliverables
These remain important, but they’re insufficient. The agenda must expand to include:
Operational performance trends: “Processing times increased 18% in week two, exceeding our concern threshold. Here’s what we’re seeing and what we’re doing about it.”
Business impact quantification: “The performance dip has reduced throughput by 2,200 transactions this week, representing approximately $X in delayed revenue.”
Correlation analysis: “The spike in errors correlates with the data migration issues we identified in last week’s incident log. Resolution is in progress.”
Recovery trajectory: “Performance recovered from 72% of baseline in week three to 85% in week four. We expect full recovery by week six based on current trend.”
Intervention decisions: “Given concurrent Initiative B launching next week whilst Initiative A is still stabilising, we recommend deferring Initiative B by three weeks to avoid compound disruption.”
This isn’t just reporting. It’s decision-making based on evidence.
Earning credibility through operational language
When change practitioners speak in operational terms … throughput, error rates, processing times, customer satisfaction, they speak the language of business leaders.
“Stakeholder readiness scores improved from 6.2 to 7.1” has less impact than “Processing times returned to baseline levels, confirming the team has embedded the new workflow.” Both metrics have value, but operational outcomes resonate more powerfully with executives focused on business performance.
Research confirms this principle. Change management earns its seat at leadership tables by demonstrating measurable impact on business outcomes, not just change activities.
Portfolio-level operational visibility
When organisations manage multiple concurrent changes, steering committees need portfolio-level operational visibility:
Heatmaps showing which teams are under highest operational pressure from concurrent changes. “Customer service is absorbing changes from Initiatives A, B, and C simultaneously. Operations is managing only Initiative B.”
Aggregate performance impact across all initiatives. “Total enterprise productivity is at 82% of baseline due to overlapping disruptions. Sequencing Initiative D would drop this to 74%, exceeding our risk tolerance.”
Recovery timelines across the portfolio. “Initiative A has stabilised. Initiative B is in week-three disruption. Initiative C hasn’t launched yet. This sequencing allows focused support where it’s needed most.”
This portfolio view enables trade-off decisions impossible at individual project level: defer lower-priority changes, reallocate support resources to highest-disruption areas, establish blackout periods for overloaded teams.
Real-world application: case example
Consider a mid-sized financial services firm implementing three concurrent technology changes affecting the same operations team:
Week 1 (Initiative A go-live): Daily tracking showed processing time increased to 3.8 hours (+19%), error rate jumped to 7.1% (+69%), volume dropped to 165 applications (-8%). CSAT held at 4.2.
Response: Increased on-site support from two FTEs to five. Extended helpdesk hours. Daily huddles to address emerging issues.
Week 3: Processing time recovered to 3.4 hours (+6% from baseline). Error rate improved to 5.1% (+21% from baseline but improving). Volume reached 174 applications (-3%). CSAT recovered to 4.3.
Decision point: Initiative B was scheduled to launch Week 4. Dashboard data showed Initiative A was stabilising but not yet fully recovered. Leadership faced a choice:
Option 1: Proceed with Initiative B as scheduled. Risk compound disruption whilst Initiative A is still embedded.
Option 2: Defer Initiative B launch by three weeks, allowing full Initiative A stabilisation before introducing new disruption.
Decision: Defer Initiative B. The operational data made visible the risk of compound impact. Three-week deferral extended overall timeline but protected operational performance and adoption quality.
Outcome: By Week 6, Initiative A metrics returned to baseline. Initiative B launched Week 7 into a stabilised operation. The team absorbed Initiative B with minimal disruption (processing time peaked at +8% vs the +19% for Initiative A, because the team wasn’t simultaneously managing two changes). Initiative C launched Week 12 after Initiative B stabilised.
Total programme timeline: Extended by three weeks. Total operational disruption: Reduced by an estimated 40% because changes were sequenced to respect team capacity rather than pushed concurrently for timeline optimisation.
This is what operational performance tracking enables: evidence-based decisions that optimise for business outcomes rather than project schedules.
Building the measurement infrastructure
For organisations without existing infrastructure to track operational performance during change, building capability requires systematic steps:
Month 1: Inventory and assess
Identify all operational metrics currently tracked across functions
Assess data quality, frequency, and accessibility
Identify gaps where critical functions lack performance metrics
Catalogue data sources and integration points
Month 2: Establish standards
Define the 3-5 critical metrics for each major function
Standardise calculation methods and reporting formats
Establish baseline measurement protocols
Create integration between operational systems and change dashboards
Month 3: Pilot measurement
Select one upcoming change initiative for pilot
Implement full baseline-to-recovery tracking
Test dashboard integration and governance reporting
Refine based on pilot learnings
Month 4-6: Scale enterprise-wide
Roll out standardised operational performance tracking across all major initiatives
Train project managers and change leads on measurement protocols
Integrate operational performance into steering committee agendas
Establish portfolio-level tracking for concurrent changes
Month 7+: Continuous improvement
Refine metrics based on what proves most predictive
Automate data collection and reporting where possible
Expand portfolio visibility and decision-making capability
Build predictive models based on historical change-performance correlation
Tools like The Change Compass provide ready-built infrastructure for this type measurement, enabling organisations to skip months of development and begin tracking immediately.
The strategic value of operational performance tracking
When organisations systematically track operational performance during change, the benefits extend beyond individual project success:
Evidence-based portfolio prioritisation: Data showing which teams are under highest operational pressure enables rational sequencing decisions rather than political negotiations.
Predictive capacity planning: Historical patterns of disruption by change type enable future planning: “ERP implementations typically create 12-15% productivity dips for 8-10 weeks. We need to plan support resources and defer lower-priority work accordingly.”
ROI validation: Connecting change investments to sustained operational improvements demonstrates value. “Initiative A cost $2M and delivered sustained 8% processing time improvement, representing $4M annual benefit.”
Change management credibility: Speaking the language of operational outcomes positions change management as strategic business capability, not administrative overhead.
Risk mitigation: Early detection of performance degradation enables intervention before crises emerge, protecting customer experience and revenue.
Research confirms these benefits are measurable. Organisations using continuous operational performance measurement during change achieve 25-35% higher adoption rates and 6.5x higher initiative success rates than those relying on project activity metrics alone.
Frequently Asked Questions
Why is it important to track operational performance during change implementation?
Tracking operational performance during change reveals the real business impact of transformation in real-time, enabling early intervention before productivity dips become crises. Research shows organisations measuring operational performance during change achieve 51% success rates compared to 13% for those focused only on project metrics.
What operational metrics should I track during organisational change?
Focus on 3-5 metrics that matter most to your business: processing times, error rates, throughput volumes, customer satisfaction scores, and cycle times. These should be metrics executives already monitor for business health, sensitive to disruption, and measurable at high frequency.
How large are typical productivity dips during change implementation?
Research shows productivity dips range from 5-60% depending on change complexity and management approach. ERP implementations average 10-25% dips, digital transformations see 10-15% drops, and EHR systems can experience 5-60% depending on customisation. With effective change management, recovery occurs within 60-90 days.
How do you establish baseline metrics before a change initiative?
Capture 8-12 weeks of pre-change performance data for your critical operational metrics. Document average performance, typical variation ranges, and seasonal patterns. Establish thresholds defining acceptable variance vs concern levels. Communicate baselines to governance before change begins.
What happens when multiple changes impact operations simultaneously?
Concurrent changes create compound disruption where productivity losses multiply rather than add. When three initiatives each causing 10-15% dips overlap, total impact often exceeds 40-50% due to cognitive overload, fragmented attention, and support capacity constraints. Portfolio-level tracking becomes essential.
How often should operational performance be measured during change?
Measure daily during go-live week and peak disruption period (weeks 2-4), when performance dips typically peak. Shift to weekly measurement during stabilisation (weeks 5-12), then biweekly or monthly post-stabilisation. High-frequency measurement during critical windows enables rapid intervention.
What is the connection between change management and operational performance?
Effective change management directly influences operational performance during transition. Organisations with structured change management recover from productivity dips within 60-90 days and achieve 25-35% higher adoption rates. Without change management, recovery extends to 4-6 months with productivity remaining 65-75% of baseline.
Most organisations anticipate disruption around go-live. That’s when attention focuses on system stability, support readiness, and whether the new process flows will actually work. But the real crisis arrives 10 to 14 days later.
Week two is when peak disruption hits. Not because the system fails, as often it’s running adequately by then, but because the gap between how work was supposed to work and how it actually works becomes unavoidable. Training scenarios don’t match real workflows. Data quality issues surface when people need specific information for decisions. Edge cases that weren’t contemplated during design hit customer-facing teams. Workarounds that started as temporary solutions begin cascading into dependencies.
This pattern appears consistently across implementation types. EHR systems experience it. ERP platforms encounter it. Business process transformations face it. The specifics vary, but the timing holds: disruption intensity peaks in week two, then either stabilises or escalates depending on how organisations respond.
Understanding why this happens, what value it holds, and how to navigate it strategically is critical, especially when organisations are managing multiple disruptions simultaneously across concurrent projects. That’s where most organisations genuinely struggle.
The pattern: why disruption peaks in week 2
Go-live day itself is deceptive. The environment is artificial. Implementation teams are hypervigilant. Support staff are focused exclusively on the new system. Users know they’re being watched. Everything runs at artificial efficiency levels.
By day four or five, reality emerges. Users relax slightly. They try the workflows they actually do, not the workflows they trained on. They hit the branch of the process tree that the scripts didn’t cover. A customer calls with a request that doesn’t fit the designed workflow. Someone realises they need information from the system that isn’t available in the standard reports. A batch process fails because it references data fields that weren’t migrated correctly.
These issues arrive individually, then multiply.
Research on implementation outcomes shows this pattern explicitly. A telecommunications case study deploying a billing system shows week one system availability at 96.3%, week two still at similar levels, but by week two incident volume peaks at 847 tickets per week. Week two is not when availability drops. It’s when people discover the problems creating the incidents.
Here’s the cascade that makes week two critical:
Days 1 to 7: Users work the happy paths. Trainers are embedded in operations. Ad-hoc support is available. Issues get resolved in real time before they compound. The system appears to work.
Days 8 to 14: Implementation teams scale back support. Users begin working full transaction volumes. Edge cases emerge systematically. Support systems become overwhelmed. Individual workarounds begin interconnecting. Resistance crystallises, and Prosci research shows resistance peaks 2 to 4 weeks post-implementation. By day 14, leadership anxiety reaches a peak. Finance teams close month-end activities and hit system constraints. Operations teams process their full transaction volumes and discover performance issues. Customer service teams encounter customer scenarios not represented in training.
Weeks 3 to 4: Either stabilisation occurs through focused remediation and support intensity, or problems compound further. Organisations that maintain intensive support through week two recover within 60 to 90 days. Those that scale back support too early experience extended disruption lasting months.
The research quantifies this. Performance dips during implementation average 10 to 25%, with complex systems experiencing dips of 40% or more. These dips are concentrated in weeks 1 to 4, with week two as the inflection point. Supply chain systems average 12% productivity loss. EHR systems experience 5 to 60% depending on customisation levels. Digital transformations typically see 10 to 15% productivity dips.
The depth of the dip depends on how well organisations manage the transition. Without structured change management, productivity at week three sits at 65 to 75% of pre-implementation levels, with recovery timelines extending 4 to 6 months. With effective change management and continuous support, recovery happens within 60 to 90 days.
Understanding the value hidden in disruption
Most organisations treat week-two disruption as a problem to minimise. They try to manage through it with extended support, workarounds, and hope. But disruption, properly decoded, provides invaluable intelligence.
Each issue surfaced in week two is diagnostic data. It tells you something real about either the system design, the implementation approach, data quality, process alignment, or user readiness. Organisations that treat these issues as signals rather than failures extract strategic value.
Process design flaws surface quickly.
A customer-service workflow that seemed logical in design fails when customer requests deviate from the happy path. A financial close process that was sequenced one way offline creates bottlenecks when executed at system speed. A supply chain workflow that assumed perfect data discovers that supplier codes haven’t been standardised. These aren’t implementation failures. They’re opportunities to redesign processes based on actual operational reality rather than theoretical process maps.
Integration failures reveal incompleteness.
A data synchronisation issue between billing and provisioning systems appears in week two when the volume of transactions exposing the timing window is processed. A report that aggregates data from multiple systems fails because one integration wasn’t tested with production data volumes. An automated workflow that depends on customer master data being synchronised from an upstream system doesn’t trigger because the synchronisation timing was wrong. These issues force the organisation to address integration robustness rather than surfacing in month six when it’s exponentially more costly to fix.
Training gaps become obvious.
Not because users lack knowledge, as training was probably thorough, but because knowledge retention drops dramatically once users are under operational pressure. That field on a transaction screen no one understood in training becomes critical when a customer scenario requires it. The business rule that sounded straightforward in the classroom reveals nuance when applied to real transactions. Workarounds start emerging not because the system is broken but because users revert to familiar mental models when stressed.
Data quality problems declare themselves.
Historical data migration always includes cleansing steps. Week two is when cleansed data collides with operational reality. Customer address data that was “cleaned” still has variants that cause matching failures. Supplier master data that was de-duplicated still includes records no one was aware of. Inventory counts that were migrated don’t reconcile with physical systems because the timing window wasn’t perfect. These aren’t test failures. They’re production failures that reveal where data governance wasn’t rigorous enough.
System performance constraints appear under load.
Testing runs transactions in controlled batches. Real operations involve concurrent transaction volumes, peak period spikes, and unexpected load patterns. Performance issues that tests didn’t surface appear when multiple users query reports simultaneously or when a batch process runs whilst transaction processing is also occurring. These constraints force decisions about infrastructure, system tuning, or workflow redesign based on evidence rather than assumptions.
Adoption resistance crystallises into actionable intelligence.
Resistance in weeks 1 to 2 often appears as hesitation, workaround exploration, or question-asking. By week two, if resistance is adaptive and rooted in legitimate design or readiness concerns, it becomes specific. “The workflow doesn’t work this way because of X” is more actionable than “I’m not ready for this system.” Organisations that listen to week-two resistance can often redesign elements that actually improve the solution.
The organisations that succeed at implementation are those that treat week-two disruption as discovery rather than disaster. They maintain support intensity specifically because they know disruption reveals critical issues. They establish rapid response mechanisms. They use the disruption window to test fixes and process redesigns with real operational complexity visible for the first time.
This doesn’t mean chaos is acceptable. It means disruption, properly managed, delivers value.
The reality when disruption stacks: multiple concurrent go-lives
The week-two disruption pattern assumes focus. One system. One go-live. One disruption window. Implementation teams concentrated. Support resources dedicated. Executive attention singular.
This describes almost no large organisations actually operating today.
Most organisations manage multiple implementations simultaneously. A financial services firm launches a new customer data platform, updates its payments system, and implements a revised underwriting workflow across the same support organisations and user populations. A healthcare system deploys a new scheduling system, upgrades its clinical documentation platform, and migrates financial systems, often on overlapping timelines. A telecommunications company implements BSS (business support systems) whilst updating OSS (operational support systems) and launching a new customer portal.
When concurrent disruptions overlap, the impacts compound exponentially rather than additively.
Disruption occurring at week two for Initiative A coincides with go-live week one for Initiative B and the first post-implementation month for Initiative C. Support organisations are stretched across three separate incident response mechanisms. Training resources are exhausted from Initiative A training when Initiative B training ramps. User psychological capacity, already strained from one system transition, absorbs another concurrently.
Research on concurrent change shows this empirically. Organisations managing multiple concurrent initiatives report 78% of employees feeling saturated by change. Change-fatigued employees show 54% higher turnover intentions compared to 26% for low-fatigue employees. Productivity losses don’t add up; they cascade. One project’s 12% productivity loss combined with another’s 15% loss doesn’t equal 27% loss. Concurrent pressures often drive losses exceeding 40 to 50%.
The week-two peak disruption of Initiative A, colliding with go-live intensity for Initiative B, creates what one research study termed “stabilisation hell”, a period where organisations struggle simultaneously to resolve unforeseen problems, stabilise new systems, embed users, and maintain business-as-usual operations.
Consider a real scenario. A financial services firm deployed three major technology changes into the same operations team within 12 weeks. Initiative A: New customer data platform. Initiative B: Revised loan underwriting workflow. Initiative C: Updated operational dashboard.
Week four saw Initiative A hit its week-two peak disruption window. Incident volumes spiked. Data quality issues surfaced. Workarounds proliferated. Support tickets exceeded capacity. Week five, Initiative B went live. Training for a new workflow began whilst Initiative A fires were still burning. Operations teams were learning both systems on the fly.
Week eight, Initiative C launched. By then, operations teams had learned two new systems, embedded neither, and were still managing Initiative A stabilisation issues. User morale was low. Stress was high. Error rates were increasing. The organisation had deployed three initiatives but achieved adoption of none. Each system remained partially embedded, each adoption incomplete, each system contributing to rather than resolving operational complexity.
Research on this scenario is sobering. 41% of projects exceed original timelines by 3+ months. 71% of projects surface issues post go-live requiring remediation. When three projects encounter week-two disruptions simultaneously or overlappingly, the probability that all three stabilise successfully drops dramatically. Adoption rates for concurrent initiatives average 60 to 75%, compared to 85 to 95% for single initiatives. Recovery timelines extend from 60 to 90 days to 6 to 12 months or longer.
The core problem: disruption is valuable for diagnosis, but only if organisations have capacity to absorb it. When capacity is already consumed, disruption becomes chaos.
Strategies to prevent operational collapse across the portfolio
Preventing operational disruption when managing concurrent initiatives requires moving beyond project-level thinking to portfolio-level orchestration. This means designing disruption strategically rather than hoping to manage through it.
Step 1: Sequence initiatives to prevent concurrent peak disruptions
The most direct strategy is to avoid allowing week-two peak disruptions to occur simultaneously.
This requires mapping each initiative’s disruption curve. Initiative A will experience peak disruption weeks 2 to 4. Initiative B, scheduled to go live once Initiative A stabilises, will experience peak disruption weeks 8 to 10. Initiative C, sequenced after Initiative B stabilises, disrupts weeks 14 to 16. Across six months, the portfolio experiences three separate four-week disruption windows rather than three concurrent disruption periods.
Does sequencing extend overall timeline? Technically yes. Initiative A starts week one, Initiative B starts week six, Initiative C starts week twelve. Total programme duration: 20 weeks vs 12 weeks if all ran concurrently. But the sequencing isn’t linear slowdown. It’s intelligent pacing.
More critically: what matters isn’t total timeline, it’s adoption and stabilisation. An organisation that deploys three initiatives serially over six months with each fully adopted, stabilised, and delivering value exceeds in value an organisation that deploys three initiatives concurrently in four months with none achieving adoption above 70%.
Sequencing requires change governance to make explicit trade-off decisions. Do we prioritise getting all three initiatives out quickly, or prioritise adoption quality? Change portfolio management creates the visibility required for these decisions, showing that concurrent Initiative A and B deployment creates unsustainable support load, whereas sequencing reduces peak support load by 40%.
Step 2: Consolidate support infrastructure across initiatives
When disruptions must overlap, consolidating support creates capacity that parallel support structures don’t.
Most organisations establish separate support structures for each initiative. Initiative A has its escalation path. Initiative B has its own. Initiative C has its own. This creates three separate 24-hour support rotations, three separate incident categorisation systems, three separate communication channels.
Consolidated support establishes one enterprise support desk handling all issues concurrently. Issues get triaged to the appropriate technical team, but user-facing experience is unified. A customer-service representative doesn’t know whether their problem stems from Initiative A, B, or C, and shouldn’t have to. They have one support number.
Consolidated support also reveals patterns individual support teams miss. When issues across Initiative A and B appear correlated, when Initiative B’s workflow failures coincide with Initiative A data synchronisation issues, consolidated support identifies the dependency. Individual teams miss this connection because they’re focused only on their initiative.
Step 3: Integrate change readiness across initiatives
Standard practice means each initiative runs its own readiness assessment, designs its own training programme, establishes its own change management approach.
This creates training fragmentation. Users receive five separate training programmes from five separate change teams using five different approaches. Training fatigue emerges. Messaging conflicts create confusion.
Integrated readiness means:
One readiness framework applied consistently across all initiatives
Consolidated training covering all initiatives sequentially or in integrated learning paths where possible
Unified change messaging that explains how the portfolio of changes supports a coherent organisational direction
Shared adoption monitoring where one dashboard shows readiness and adoption across all initiatives simultaneously
This doesn’t require initiatives to be combined technically. Initiative A and B remain distinct. But from a change management perspective, they’re orchestrated.
Research shows this approach increases adoption rates 25 to 35% compared to parallel change approaches.
Step 4: Create structured governance over portfolio disruption
Change portfolio management governance operates at two levels:
Initiative level: Sponsor, project manager, change lead, communications lead manage Initiative A’s execution, escalations, and day-to-day decisions.
Portfolio level: Representatives from all initiatives meet fortnightly to discuss:
Emerging disruptions across all initiatives
Support load analysis, identifying where capacity limits are being hit
Escalation patterns and whether issues are compounding across initiatives
Readiness progression and whether adoption targets are being met
Adjustment decisions, including whether to slow Initiative B to support Initiative A stabilisation
Portfolio governance transforms reactive problem management into proactive orchestration. Instead of discovering in week eight that support capacity is exhausted, portfolio governance identifies the constraint in week four and adjusts Initiative B timeline accordingly.
Tools like The Change Compass provide the data governance requires. Real-time dashboards show support load across initiatives. Heatmaps reveal where particular teams are saturated. Adoption metrics show which initiatives are ahead and which are lagging. Incident patterns identify whether issues are initiative-specific or portfolio-level.
Step 5: Use disruption windows strategically for continuous improvement
Week-two disruptions, whilst painful, provide a bounded window for testing process improvements. Once issues surface, organisations can test fixes with real operational data visible.
Rather than trying to suppress disruption, portfolio management creates space to work within it:
Days 1 to 7: Support intensity is maximum. Issues are resolved in real time. Limited time for fundamental redesign.
Days 8 to 14: Peak disruption is more visible. Teams understand patterns. Workarounds have emerged. This is the window to redesign: “The workflow doesn’t work because X. Let’s redesign process Y to address this.” Changes tested at this point, with full production visibility, are often more effective than changes designed offline.
Weeks 3 to 4: Stabilisation period. Most issues are resolved. Remaining issues are refined through iteration.
Organisations that allocate capacity specifically for week-two continuous improvement often emerge with more robust solutions than those that simply try to push through disruption unchanged.
Operational safeguards: systems to prevent disruption from becoming crisis
Beyond sequencing and governance, several operational systems prevent disruption from cascading into crisis:
Load monitoring and reporting
Before initiatives launch, establish baseline metrics:
Support ticket volume (typical week has X tickets)
Incident resolution time (typical issue resolves in Y hours)
User productivity metrics (baseline is Z transactions per shift)
System availability metrics (target is 99.5% uptime)
During disruption weeks, track these metrics daily. When tickets approach 150% of baseline, escalate. When resolution times extend beyond 2x normal, adjust support allocation. When productivity dips exceed 30%, trigger contingency actions.
This monitoring isn’t about stopping disruption. It’s about preventing disruption from becoming uncontrolled. The organisation knows the load is elevated, has data quantifying it, and can make decisions from evidence rather than impression.
Readiness assessment across the portfolio
Don’t run separate readiness assessments. Run one portfolio-level readiness assessment asking:
Which populations are ready for Initiative A?
Which are ready for Initiative B?
Which face concurrent learning demand?
Where do we have capacity for intensive support?
Where should we reduce complexity or defer some initiatives?
This single assessment reveals trade-offs. “Operations is ready for Initiative A but faces capacity constraints with Initiative B concurrent. Options: Defer Initiative B two weeks, assign additional change support resources, or simplify Initiative B scope for operations teams.”
Blackout periods and pacing restrictions
Most organisations establish blackout periods for financial year-end, holiday periods, or peak operational seasons. Many don’t integrate these with initiative timing.
Portfolio management makes these explicit:
October to December: Reduced change deployment (year-end focus)
January weeks 1 to 2: No major launches (people returning from holidays)
July to August: Minimal training (summer schedules)
March to April: Capacity exists; good deployment window
Planning initiatives around blackout periods and organisational capacity rhythms rather than project schedules dramatically improves outcomes.
Contingency support structures
For initiatives launching during moderate-risk windows, establish contingency support plans:
If adoption lags 15% behind target by week two, what additional support deploys?
If critical incidents spike 100% above baseline, what escalation activates?
If user resistance crystallises into specific process redesign needs, what redesign process engages?
If stabilisation targets aren’t met by week four, what options exist?
This isn’t pessimism. It’s realistic acknowledgement that week-two disruption is predictable and preparations can address it.
Integrating disruption management into change portfolio operations
Preventing operational disruption collapse requires integrating disruption management into standard portfolio operations:
Month 1: Portfolio visibility
Map all concurrent initiatives
Identify natural disruption windows
Assess portfolio support capacity
Month 2: Sequencing decisions
Determine which initiatives must sequence vs which can overlap
Identify where support consolidation is possible
Establish integrated readiness framework
Month 3: Governance establishment
Launch portfolio governance forum
Establish disruption monitoring dashboards
Create escalation protocols
Months 4 to 12: Operational execution
Monitor disruption curves as predicted
Activate contingencies if necessary
Capture continuous improvement opportunities
Track adoption across portfolio
Tools supporting this integration, such as change portfolio platforms like The Change Compass, provide the visibility and monitoring capacity required. Real-time dashboards show disruption patterns as they emerge. Adoption tracking reveals whether initiatives are stabilising or deteriorating. Support load analytics identify bottleneck periods before they become crises.
The research imperative: what we know about disruption
The evidence on implementation disruption is clear:
Week-two peak disruption is predictable, not random
Disruption provides diagnostic value when organisations have capacity to absorb and learn from it
Concurrent disruptions compound exponentially, not additively
Sequencing initiatives strategically improves adoption and stabilisation vs concurrent deployment
Organisations with portfolio-level governance achieve 25 to 35% higher adoption rates
Recovery timelines for managed disruption: 60 to 90 days; unmanaged disruption: 6 to 12 months
The alternative to strategic disruption management is reactive crisis management. Most organisations experience week-two disruption reactively, scrambling to support, escalating tickets, hoping for stabilisation. Some organisations, especially those managing portfolios, are choosing instead to anticipate disruption, sequence it thoughtfully, resource it adequately, and extract value from it.
The difference in outcomes is measurable: adoption, timeline, support cost, employee experience, and long-term system value.
Frequently asked questions
Why does disruption peak specifically at week 2, not week 1 or week 3?
Week one operates under artificial conditions: hypervigilant support, implementation team presence, trainers embedded, users following scripts. Real patterns emerge when artificial conditions end. Week two is when users attempt actual workflows, edge cases surface, and accumulated minor issues combine. Peak incident volume and resistance intensity typically occur weeks 2 to 4, with week two as the inflection point.
Should organisations try to suppress week-two disruption?
No. Disruption reveals critical information about process design, integration completeness, data quality, and user readiness. Suppressing it masks problems. The better approach: acknowledge disruption will occur, resource support intensity specifically for the week-two window, and use the disruption as diagnostic opportunity.
How do we prevent week-two disruptions from stacking when managing multiple concurrent initiatives?
Sequence initiatives to avoid concurrent peak disruption windows. Consolidate support infrastructure across initiatives. Integrate change readiness across initiatives rather than running parallel change efforts. Establish portfolio governance making explicit sequencing decisions. Use change portfolio tools providing real-time visibility into support load and adoption across all initiatives.
What’s the difference between well-managed disruption and unmanaged disruption in recovery timelines?
Well-managed disruption with adequate support resources, portfolio orchestration, and continuous improvement capacity returns to baseline productivity within 60 to 90 days post-go-live. Unmanaged disruption with reactive crisis response, inadequate support, and no portfolio coordination extends recovery timelines to 6 to 12 months or longer, often with incomplete adoption.
Can change portfolio management eliminate week-two disruption?
No, and that’s not the goal. Disruption is inherent in significant change. Portfolio management’s purpose is to prevent disruption from cascading into crisis, to ensure organisations have capacity to absorb disruption, and to extract value from disruption rather than merely enduring it.
How does the size of an organisation affect week-two disruption patterns?
Patterns appear consistent: small organisations, large enterprises, government agencies all experience week-two peak disruption. Scale affects the magnitude. A 50-person firm’s week-two disruption affects everyone directly, whilst a 5,000-person firm’s disruption affects specific departments. The timing and diagnostic value remain consistent.
What metrics should we track during the week-two disruption window?
Track system availability (target: maintain 95%+), incident volume (expect 200%+ of normal), mean time to resolution (expect 2x baseline), support ticket backlog (track growth and aging), user productivity in key processes (expect 65 to 75% of baseline), adoption of new workflows (expect initial adoption with workaround development), and employee sentiment (expect stress with specific resistance themes).
How can we use week-two disruption data to improve future implementations?
Document incident patterns, categorise by root cause (design, integration, data, training, performance), and use these insights for process redesign. Test fixes during week-two disruption when full production complexity is visible. Capture workarounds users develop, as they often reveal legitimate unmet needs. Track which readiness interventions were most effective. Use this data to tailor future implementations.
An enterprise change management strategy is the deliberate, multi-year plan that determines how an organisation will build and apply change capability at scale across every business unit, programme and transformation initiative. It covers the operating model (centralised, federated or hybrid), the methodology and tooling that will be used consistently, the capability-building approach for change practitioners and leaders, the governance structures that connect change to portfolio decisions, and the measurement framework that proves adoption and benefit realisation. The strategy distinguishes itself from individual project plans by treating change capability as a strategic asset rather than a delivery activity.
Enterprise change management has evolved from a tactical support function into a strategic discipline that directly determines whether large organizations successfully execute complex transformations and realize value from major investments. Rather than focusing narrowly on training and communications for individual projects, effective enterprise change management operates as an integrated business partner aligned with organizational strategy, optimizing multiple concurrent initiatives across the portfolio, and building organizational capability to navigate change as a core competency. The 10 strategies outlined in this guide provide a practical roadmap for large organizations to design and operate enterprise change management as a value driver that delivers faster benefit realization, prevents change saturation, and increases project success rates by six times compared to organizations without structured enterprise change capability.
Understanding Enterprise Change Management in Modern Organizations
Enterprise change management differs fundamentally from project-level change management in both scope and strategic integration. While project-level change management focuses on helping teams transition to new tools and processes within a specific initiative, ECM operates at the enterprise level to coordinate and optimize multiple concurrent change initiatives across the entire organization. This distinction is critical: ECM aligns all change initiatives with strategic goals, manages cumulative organizational capacity, and builds sustainable change competency that compounds over time.
The scope of ECM encompasses three interconnected levels of capability development:
Individual level: Building practical skills in leaders and employees to navigate change, explain strategy, support teams, and use new ways of working
Project level: Applying consistent change processes across major initiatives, integrating change activities into delivery plans, and measuring adoption
Enterprise level: Establishing standards, templates, governance structures, and metrics that ensure change is approached consistently across the portfolio
In large organizations managing multiple strategic initiatives simultaneously, ECM provides the connective tissue between strategy, projects, and day-to-day operations. Rather than treating each initiative in isolation, ECM looks across the enterprise to understand who is impacted, when, and by what level of change, and then shapes how the organization responds to maximize value and minimize disruption.
The Business Case for Enterprise Change Management
Before examining strategies, it is important to understand the compelling business rationale for investing in enterprise change management. Organizations with effective change management capabilities achieve substantially different outcomes than those without structured approaches.
Return on investment represents the most significant financial differentiator.
Organizations with effective change management achieve an average ROI of 143 percent compared to just 35 percent without, creating a four-fold difference in returns. When calculated as a ratio, change management typically delivers 3 to 7 dollars in benefits for every dollar invested. These returns manifest through faster benefit realization, higher adoption rates, fewer failed projects, and reduced implementation costs.
Project success rates are dramatically influenced by change management capability.
Projects with excellent change management practices are 6 to 7 times more likely to meet project objectives than those with poor change management. Organizations that measure change effectiveness systematically achieve a 51 percent success rate, compared to just 13 percent for those that do not track change metrics.
Productivity impact during transitions is measurable and significant.
Organizations with effective change management typically experience productivity dips of only 15 percent during transitions, compared to 45 to 65 percent in organizations without structured change management. This difference directly translates to revenue impact during implementation periods.
When organizations exceed their change capacity threshold without portfolio-level coordination, consequences cascade across multiple performance dimensions. Research shows that organizations applying appropriate change management during periods of high change increased adoption by 72 percent and decreased employee turnover by almost 10 percent, generating savings averaging $72,000 per company per year in training programs alone.
Understanding this business case provides essential context for why the strategies outlined below matter. Enterprise change management is not a discretionary function but an investment that demonstrably improves organizational performance.
10 Strategies for Enterprise Change Management: Delivering Business Goals in Large Organizations
Strategy 1: Connect Enterprise Change Management Directly to Business Goals
A strong ECM strategy starts by explicitly linking change work to the organization’s strategic objectives. Rather than launching generic capability initiatives or responding only to project requests, the ECM function prioritizes its effort around where change will most influence revenue growth, cost efficiency, risk reduction, customer experience, or regulatory compliance outcomes.
This strategic alignment serves multiple purposes. It focuses limited ECM resources on the initiatives that matter most to the business. It demonstrates clear line of sight from change investment to corporate goals, which supports executive sponsorship and funding. It ensures that ECM advice on sequencing, timing, and investment is grounded in business priorities rather than change management principles alone.
Practical implementation steps include:
Map each strategic objective to a set of initiatives, key impacted groups, required behaviour shifts and services provided
Define 3 to 5 “enterprise outcomes” for ECM (such as faster benefit realization, fewer change-related incidents, higher adoption scores) and track them year-on-year
Use strategy language in ECM artefacts, roadmaps, reports, and dashboards so executives see clear line of sight from ECM work to corporate goals
Present ECM’s annual plan in the same forums and language as other strategic functions, positioning it as a strategic enabler rather than a project support service
Strategy 2: Design an Enterprise Change Management Operating Model That Fits Your Context
The way ECM is structured makes a significant difference to its impact and scalability. Research and practice show that large organizations typically succeed with one of three core operating models: centralized, federated, or hybrid ECM.
Centralized ECM establishes a single enterprise change team that sets standards, runs portfolio oversight, and supplies practitioners into priority initiatives. This approach works well where strategy and funding are tightly controlled at the centre, and where the organization requires consistency across geographies or business units. The advantage is strong governance and consistent methodology; the risk is inflexibility in local contexts and potential bottlenecks if the central team becomes stretched.
Federated ECM empowers business-unit change teams to work to a common framework but tailor approaches locally. This model suits diversified organizations or those with strong regional autonomy. The advantage is local responsiveness and cultural fit; the risk is potential inconsistency and difficulty maintaining enterprise-wide visibility and standards.
Hybrid ECM establishes a small central team that owns methods, tools, governance, and enterprise-level analytics, while embedded practitioners sit in key portfolios or divisions. This model is common in complex, matrixed enterprises and organizations managing multiple concurrent transformations. The advantage is both consistency and responsiveness; the risk is complexity in defining roles and decision-making authority.
When designing the operating model, clarify:
Who owns ECM strategy, standards, and governance
How change practitioners are allocated and funded across the portfolio
Where key decisions are made on priorities, sequencing, and risk mitigation
How the ECM function interfaces with PMOs, strategy, and business operations
Strategy 3: Build Capability Across Individual, Project, and Enterprise Levels
Sustainable ECM capability rests on deliberate development across all three levels of the organization. Too many organizations invest only in individual capability (training) or only at the project level (methodologies) without embedding organizational standards and governance. This results in uneven capability, lack of consistency, and difficulty scaling.
Individual capability building ensures leaders and employees have practical skills to navigate change. This includes explaining why change is happening and how it connects to strategy, supporting teams through transition periods, and using new tools and processes effectively. Effective approaches include targeted coaching, practical playbooks, and self-help resources that enable leaders to act without always requiring a specialist.
Project-level capability applies a consistent change process across major initiatives. Prosci’s 3-phase process (Prepare, Manage, Sustain) and similar frameworks provide structure that improves predictability and effectiveness. Integration with delivery planning is essential, so change activities (communications, training, resistance management, adoption measurement) are built into delivery schedules rather than running separately.
Enterprise-level capability establishes standards, templates, tools, and governance so change is approached consistently across the portfolio. This level includes maturity assessments using frameworks like the CMI or Prosci models, defining the organization’s current state and desired progression. Strong enterprise capability means that regardless of which business unit or initiative is delivering change, standards and support are consistent.
A practical maturity roadmap typically involves:
Stage 1 (Ad Hoc): Establish basics with common language, simple framework, and small central team
Stage 2 (Repeatable): Build consistency through standard tools, regular reporting, and PMO integration
Stage 3 (Defined): Scale through business-unit change teams, champion networks, and clear metrics
Stage 4 (Managed): Embed through organizational integration and leadership expectations
Stage 5 (Optimized): Achieve full integration with strategy and performance management
Strategy 4: Use Portfolio-Level Planning to Avoid Change Collisions and Saturation
One of the highest-value strategies for large organizations is introducing portfolio-level visibility of all in-flight and upcoming changes. Portfolio change planning differs fundamentally from project change planning: rather than optimizing one project at a time, ECM helps the organization optimize the entire portfolio against capacity, risk, and benefit outcomes.
The impact of portfolio-level planning is substantial. Organizations with effective portfolio management reduce the likelihood of change saturation, avoid costly collisions where multiple initiatives hit the same teams simultaneously, and increase the odds that high-priority initiatives actually land and stick. Portfolio visibility also informs critical business decisions about sequencing and timing of major initiatives.
Practical implementation steps include:
Create a single view of change across the enterprise showing initiative name, impacted audiences, timing, and impact level using simple heatmaps or dashboards
Identify “hot spots” where multiple changes hit the same teams or customers in the same period, and work with portfolio and PMO partners to reschedule or reduce load
Establish portfolio governance forums where investment and sequencing decisions explicitly consider both financial and people-side capacity constraints
Use portfolio data to advise on optimal sequencing of initiatives, typically spacing major changes to allow adoption and benefits realization between waves
Portfolio-level change planning transforms ECM from a project support service into a strategic advisor on organizational capacity and risk.
Strategy 5: Anchor Enterprise Change Management in Benefits Realization and Performance Tracking
Enterprise change strategy should be framed fundamentally as a way to protect and accelerate benefits, not simply as a mechanism to support adoption. Benefits realization management significantly improves alignment of projects with strategic objectives and provides data that drives future portfolio decisions.
Benefit realization management operates in stages. Before change, organizations establish clear baselines for the metrics they expect to improve (cycle time, cost, error rates, customer satisfaction, revenue, etc.). During change, teams track adoption and intermediate indicators. After go-live, systematic measurement determines whether the organization actually achieved promised benefits.
The discipline of benefits management drives several strategic advantages. First, it forces clarity about what success actually means for each initiative, moving beyond “adoption” to genuine business impact. Second, it enables organizations to calculate true ROI and demonstrate value to stakeholders. Third, it provides feedback for continuous improvement: when benefits fall short, measurement reveals whether the issue was weak adoption, flawed design, or external factors.
Practical implementation includes:
For each major initiative, define 3 to 5 measurable business benefits (for example cost to serve, error reduction, revenue per customer, service time) and link them to specific behaviour and process changes
Assign owners for each benefit on the business side and clarify how and when benefits will be measured post-go-live
Establish a simple benefits and adoption dashboard that surfaces progress across initiatives and highlights where ECM focus is needed to close gaps
Report on benefits progress in regular forums so benefit realization becomes a key topic in performance discussions
When ECM consistently reports in business-outcome terms (for example “this change is at 80 percent of targeted benefit due to low usage in X function”), it becomes a natural partner in performance discussions and strategic planning.
Strategy 6: Make Leaders and Sponsorship the Engine of Enterprise Change
Leadership behaviour is one of the strongest predictors of successful change. An effective ECM strategy treats leaders as both the primary audience and the primary channel through which change cascades through the organization.
Executive sponsors set the tone for how the organization approaches change through the signals they send about priority, urgency, and willingness to adapt themselves. Line leaders translate strategic intent into local action and model new behaviours for their teams. Middle managers often become the critical influencers who determine whether change lands effectively at the frontline.
An enterprise strategy focused on leadership excellence includes:
Clear expectations of sponsors and line leaders (setting direction, modeling change, communicating consistently, removing barriers to adoption) integrated into leadership frameworks and performance conversations
Practical, brief, role-specific resources: talking points for key milestones, stakeholder maps, coaching guides, and short “how to lead this change” sessions
Use of data on adoption, sentiment, and performance to give leaders concrete feedback on how their areas are responding and where they need to lean in
Development programs for emerging change leaders so the organization builds internal bench strength for future transformations
This leadership focus supports organizational goals by improving alignment, speeding decision-making, maintaining trust and engagement during transformation, and building internal change leadership capability that compounds over time.
Strategy 7: Build Scalable Change Networks and Communities
To execute change at enterprise scale, ECM needs leverage beyond the central team. Change champion networks and communities of practice are proven mechanisms to extend reach, build local ownership, and create feedback loops that surface emerging issues.
Change champions are practitioners embedded in business units who interpret change locally, provide peer support, and serve as feedback channels to the centre. Communities of practice bring together change practitioners across the organization to share approaches, lessons learned, and tools. Done well, these networks help the organization adapt more quickly while reducing reliance on a small central change team.
Practical elements of a scalable network model include:
Identify and train champions with clear role definitions, and provide them with resources, community, and feedback
Create a change community of practice that meets regularly to share approaches, tools, lessons, and data
Use networks not only for communications but as insight channels to capture emerging risks, adoption blockers, and improvement ideas from the frontline
Document and share best practices so successful approaches from one part of the organization can be adapted by others
Effective change networks create organizational resilience and reduce bottlenecks that can occur when all change leadership is concentrated in a small central team.
Strategy 8: Integrate Enterprise Change Management with Project, Product, and Agile Delivery
Change strategy should be tightly aligned with how the organization actually delivers work: traditional waterfall projects, product-based development, agile teams, or hybrid approaches. When ECM is bolted on as an afterthought late in project delivery, it slows progress and creates rework. When integrated from the start, it accelerates delivery while reducing adoption risk.
Integration practices that work across delivery models include:
Include change leads in portfolio shaping and discovery so that people-side impacts inform scope, design, and release planning
Use lightweight, iterative change approaches that match agile and product ways of working, including frequent stakeholder touchpoints, short feedback cycles, and gradual feature rollouts
Align artefacts so business cases, delivery plans, and release schedules carry clear sections on change impacts, adoption plans, and success measures
Make adoption and benefits realization criteria part of project definition of done, not separate activities that happen after deployment
This integration helps the organization deliver strategic initiatives faster while maintaining adoption and risk control.
Strategy 9: Use Data and Reporting as a Core Enterprise Change Management Product
For large organizations, one of the most powerful strategies is making “change intelligence” a standard management product. Rather than only delivering plans and training, ECM produces regular, simple, visual reports that show how change is landing across the enterprise.
When ECM operates as an intelligence function, it changes how executives perceive and use change management. Instead of seeing ECM as a cost, they see it as a source of insight into organizational performance and capacity.
Examples of high-value ECM reporting include:
Heatmaps showing change load by function, geography, or customer segment, with flagging of saturation risk
Adoption, sentiment, and readiness trends for key initiatives, with early warning of adoption gaps
Links between change activity and operational KPIs (incident volumes, processing time, customer satisfaction, etc.), demonstrating ECM’s contribution to business outcomes
Portfolio status showing which initiatives are on track for benefit realization and which require intervention
Research shows that organizations which measure and act on change-related metrics have much higher rates of project success and benefit realization. For executives, this positions ECM as a source of management insight, not just delivery support.
Strategy 10: Plan Enterprise Change Management Maturity as a Progressive Journey
Finally, effective ECM strategy treats capability building as a staged journey rather than a one-off rollout. Both CMI and Prosci maturity models describe five levels, from ad hoc to fully embedded organizational competency. Understanding these levels and planning progression provides essential context for resource investment and expectation setting.
Level 1 (Ad Hoc): The organization has no formal change management approach. Changes are managed reactively without structured methodology, and no dedicated change resources exist.
Level 2 (Repeatable): Senior leadership sponsors some changes but no formal company-wide program exists to train leaders. Some projects apply structured change approaches, but methodology is not standardized.
Level 3 (Defined): Standardized change management methodology is defined and applied across projects. Training and tools become available to project leaders. Managers develop coaching capability for frontline employees.
Level 4 (Managed): Change management competencies are actively built at every organizational level. Formalized change management practices ensure consistency, and organizational awareness of change management significance increases substantially.
Level 5 (Optimized): Change management is fully embedded in organizational culture and strategy. The organization operates with agility, with continuous improvement in change capability.
A practical maturity roadmap for a large organization often looks like:
Stage 1: Establish basics with a common language, simple framework, and small central team supporting priority programs
Stage 2: Build consistency through standard tools, regular reporting, and integration with PMO and portfolio processes
Stage 3: Scale and embed through business-unit change teams, champion networks, leadership expectations, and strong metrics
Stage 4-5: Optimize through data-driven planning, predictive analytics about change load and adoption, and ECM fully integrated into strategy and performance management cycles
This staged approach lets the organization grow ECM in line with its strategy, resources, and appetite, always anchored on supporting business goals rather than pursuing capability development for its own sake.
How Traditional ECM Functions Support the Strategic Framework
The established ECM functions you encounter in mature organizations (communities of practice, change leadership training, change methodologies, self-help resources, and portfolio dashboards) remain important, but they are most effective when explicitly connected to the strategies above rather than operating as standalone initiatives.
Community of practice supports Strategy 7 (building scalable networks) and Strategy 10 (progressing maturity). When designed well, communities become vehicles for sharing lessons, building peer support, and creating organizational learning that compounds over time.
Change leadership training and coaching forms the core of Strategy 6 (leaders as the engine). Rather than generic training, effective programs are specific to role, focused on practical skill development, and connected to organizational strategy.
Change methodology and framework underpins Strategy 3 (building three-level capability) and provides consistency across Strategy 4 (portfolio planning) and Strategy 8 (agile integration). A clear methodology helps teams understand expected activities and provides a common language across the organization.
Intranet self-help resources for leaders expands reach of Strategy 6 and supports day-to-day execution. Rather than requiring leaders to attend training, self-help resources provide just-in-time support that fits busy schedules.
Single view of change with traffic light indicators becomes a key artefact for Strategy 4 (portfolio planning) and Strategy 9 (data and reporting). Portfolio dashboards provide essential visibility that enables both operational decision-making and strategic advisory.
When these elements are designed and governed as part of an integrated enterprise strategy, ECM clearly supports the organization’s business goals instead of sitting on the margins as supplementary project support.
Demonstrating and Sustaining ECM Value
For ECM functions to truly demonstrate value to the organisation, survive cost-cutting periods and secure sustained investment, they must deliberately reposition themselves as strategic partners rather than support services. Over the years we have observed that even supposedly ‘mature’ ECM teams have ended up on the chopping block when resources are tight and cost efficiency is the focus for organisations. This is not necessarily because the work they are doing is not valuable, but that executives do not see the work as ‘essential’ and ‘high value’. Executives and decision makers need to ‘experience’ the value on an ongoing basis and can see that the ECM team’s work is crucial in business decision making, planning and overall organisational performance and effectiveness.
Anchor value in measurement. Move beyond anecdotal feedback and isolated project metrics to disciplined, data-driven approaches that capture the full spectrum of change activity, impact, and readiness. Organizations that measure change effectiveness systematically demonstrate value that executives recognize and fund.
Focus on business outcomes, not activities. The most compelling business cases emphasize what change management contributes to organizational performance, benefit realization, and competitive position, rather than counting communication sessions delivered or people trained.
Integrate with strategic planning. ECM functions that are involved early in strategic and operational planning cycles can model change implications, forecast resource requirements, and assess organizational readiness. This integration makes change management indispensable to strategic decision-making.
Develop advisory expertise. Build the capability to provide strategic advice about which changes sequencing will succeed, which pose highest risk, and where organizational capacity constraints exist. This elevates ECM from implementation support to strategic partnership.
Report continuously on impact. Establish regular reporting cadences that update senior leadership on change portfolio performance, adoption progress, benefit realization against targets, and operational impact. Sustained visibility of ECM’s contribution maintains stakeholder awareness and support.
Enterprise change management has evolved from a tactical support function into a strategic discipline that fundamentally affects an organization’s ability to execute strategy, realize value from capital investments, and maintain competitive position. The 10 strategies outlined in this guide provide a practical roadmap for large organizations to design and operate ECM as a value driver that supports business goals.
The most effective ECM strategies operate as an integrated system rather than as disconnected initiatives. Connecting ECM to business goals (Strategy 1), designing a sustainable operating model (Strategy 2), and building capability at all three levels (Strategy 3) provide the foundation. Portfolio planning (Strategy 4) and benefits realization tracking (Strategy 5) ensure that ECM focus translates into business outcomes. Leadership engagement (Strategy 6), scalable networks (Strategy 7), and integration with delivery (Strategy 8) ensure that change capability permeates the organization. Data-driven reporting (Strategy 9) demonstrates continuous value. And progressive maturity planning (Strategy 10) ensures the organization grows ECM capability in line with strategy and resources.
Large organizations that implement these strategies gain measurable competitive advantage through higher project success rates, faster benefit realization, reduced change saturation, and more engaged employees. For organizations managing increasingly complex transformation portfolios in competitive markets, enterprise change management is not a discretionary function but a core strategic capability that determines organizational success.
FAQ
What is enterprise change management?
Enterprise change management coordinates multiple concurrent initiatives across an organization, aligning them with strategic goals, managing capacity to prevent saturation, and maximizing benefit realization.
How does ECM differ from project change management?
Project change management supports individual initiatives. ECM operates at portfolio level, optimizing timing, resources, and impacts across all changes simultaneously.
What ROI does enterprise change management deliver?
ECM delivers 3-7X ROI ($3-$7 return per $1 invested) through faster benefits, avoided failures, and higher adoption rates.
What success rates can organizations expect with ECM?
Projects with excellent ECM achieve 88% success (vs 13% without) and are 6X more likely to meet objectives.
How do you prevent change saturation in large organizations?
Use portfolio-level visibility showing all concurrent changes by audience/timing, then sequence initiatives to protect capacity using heatmaps and governance forums.
What are the top ECM strategies for large organizations?
Connect ECM to business goals
Portfolio planning to avoid collisions
Benefits realization tracking
Leadership enablement
Data-driven reporting
What ECM operating models work best?
Hybrid model: Central team owns standards/governance, embedded practitioners execute locally. Balances consistency with responsiveness.
2-5 years: Year 1 = basics/standards, Year 2 = consistency/tools, Year 3+ = scale/embed across enterprise.
Why invest in ECM during cost pressures?
ECM demonstrates direct business value through portfolio optimization, risk reduction, and ROI tracking, making it indispensable rather than discretionary.
Measuring change management success means tracking whether an organisation’s transformation activities actually delivered the intended outcomes. That includes adoption, behaviour change, performance lift and business benefit, not just whether project milestones were ticked off on time. Effective measurement combines leading indicators such as readiness scores, training completion and sentiment data with lagging indicators such as productivity, customer outcomes and financial return. It differs from project management measurement, which tracks delivery against scope, time and budget. Change success measurement asks the executive-grade question: did the change stick, and is it producing the value the business case promised?
The difference between organisations that consistently deliver transformation value and those that struggle isn’t luck – measurement. Research from Prosci’s Best Practices in Change Management study reveals a stark reality: 88% of projects with excellent change management met or exceeded their objectives, compared to just 13% with poor change management. That’s not a marginal difference. That’s a seven-fold increase in likelihood of success.
This guide focuses on proving change programs delivered impact (the 5 outcome metrics). Three closely related guides on this site each cover a distinct angle, pick the one that matches what you need now:
Yet despite this compelling evidence, many change practitioners still struggle to articulate the value of their work in language that resonates with executives. The solution lies not in more sophisticated frameworks, but in focusing on the metrics that genuinely matter – the ones that connect change management activities to business outcomes and demonstrate tangible return on investment.
The five key metrics that matter for measuring change management success
Why Traditional Change Metrics Fall Short
Before exploring what to measure, it’s worth understanding why many organisations fail at change measurement. The problem often isn’t a lack of data – it’s measuring the wrong things. Too many change programmes track what’s easy to count rather than what actually matters.
Training attendance rates, for instance, tell you nothing about whether learning translated into behaviour change. Email open rates reveal reach but not resonance. Even employee satisfaction scores can mislead if they’re not connected to actual adoption of new ways of working. These vanity metrics create an illusion of progress whilst the initiative quietly stalls beneath the surface.
McKinsey research demonstrates that organisations tracking meaningful KPIs during change implementation achieve a 51% success rate, compared to just 13% for those that don’t – making change efforts four times more likely to succeed when measurement is embedded throughout. This isn’t about adding administrative burden. It’s about building feedback loops that enable real-time course correction and evidence-based decision-making.
Research shows initiatives with excellent change management are 7x more likely to meet objectives than those with poor change management
The Three-Level Measurement Framework
A robust approach to measuring change management success operates across three interconnected levels, each answering a distinct question that matters to different stakeholders.
Organisational Performance addresses the ultimate question executives care about: Did the project deliver its intended business outcomes? This encompasses benefit realisation, ROI, strategic alignment, and impact on operational performance. It’s the level where change management earns its seat at the leadership table.
Individual Performance examines whether people actually adopted and are using the change. This is where the rubber meets the road – measuring speed of adoption, utilisation rates, proficiency levels, and sustained behaviour change. Without successful individual transitions, organisational benefits remain theoretical.
Change Management Performance evaluates how well the change process itself was executed. This includes activity completion rates, training effectiveness, communication reach, and stakeholder engagement. While important, this level should serve the other two rather than become an end in itself.
The Three-Level Measurement Framework provides a comprehensive view of change success across organisational, individual, and process dimensions
The power of this framework lies in its interconnection. Strong change management performance should drive improved individual adoption, which in turn delivers organisational outcomes. When you measure at all three levels, you can diagnose precisely where issues are occurring and take targeted action.
Metric 1: Adoption Rate and Utilisation
Adoption rate is perhaps the most fundamental measure of change success, yet it’s frequently underutilised or poorly defined. True adoption measurement goes beyond counting system logins or tracking training completions. It examines whether people are genuinely integrating new ways of working into their daily operations. For a detailed breakdown of the specific adoption metrics to track across different change types, see our comprehensive guide to change management adoption metrics.
Effective adoption metrics include:
Speed of adoption: How quickly did target groups reach defined levels of new process or tool usage? Organisations using continuous measurement achieve 25-35% higher adoption rates than those conducting single-point assessments.
Ultimate utilisation: What percentage of the target workforce is actively using the new systems, processes, or behaviours? Technology implementations with structured change management show adoption rates around 95% compared to 35% without.
Proficiency levels: Are people using the change correctly and effectively? This requires moving beyond binary “using/not using” to assess quality of adoption through competency assessments and performance metrics.
Feature depth: Are people utilising the full functionality, or only basic features? Shallow adoption often signals training gaps or design issues that limit benefit realisation.
Practical application: Establish baseline usage patterns before launch, define clear adoption milestones with target percentages, and implement automated tracking where possible. Use the data not just for reporting but for identifying intervention opportunities – which teams need additional support, which features require better training, which resistance points need addressing.
Metric 2: Stakeholder Engagement and Readiness
Research from McKinsey reveals that organisations with robust feedback loops are 6.5 times more likely to experience effective change compared to those without. This staggering multiplier underscores why stakeholder engagement measurement is non-negotiable for change success.
Engagement metrics operate at both leading and lagging dimensions. Leading indicators predict future adoption success, while lagging indicators confirm actual outcomes. Effective measurement incorporates both.
Leading engagement indicators:
Stakeholder participation rates: Track attendance and active involvement in change-related activities, town halls, workshops, and feedback sessions. In high-interest settings, 60-80% participation from key groups is considered strong.
Readiness assessment scores: Regular pulse checks measuring awareness, desire, knowledge, ability, and reinforcement (the ADKAR dimensions) provide actionable intelligence on where to focus resources.
Manager involvement levels: Measure frequency and quality of manager-led discussions about the change. Manager advocacy is one of the strongest predictors of team adoption.
Feedback quality and sentiment: Monitor the nature of questions being asked, concerns raised, and suggestions submitted. Qualitative analysis often reveals issues before they appear in quantitative metrics.
Lagging engagement indicators:
Resistance reduction: Track the frequency and severity of resistance signals over time. Organisations applying appropriate resistance management techniques increase adoption by 72% and decrease employee turnover by almost 10%.
Repeat engagement: More than 50% repeat involvement in change activities signals genuine relationship building and sustained commitment.
Net promoter scores for the change: Would employees recommend the new way of working to colleagues? This captures both satisfaction and advocacy.
Prosci research found that two-thirds of practitioners using the ADKAR model as a measurement framework rated it extremely effective, with one participant noting, “It makes it easier to move from measurement results to actions. If Knowledge and Ability are low, the issue is training – if Desire is low, training will not solve the problem”.
Metric 3: Productivity and Performance Impact
The business case for most change initiatives ultimately rests on productivity and performance improvements. Yet measuring these impacts requires careful attention to attribution and timing.
Direct performance metrics:
Process efficiency gains: Cycle time reductions, error rate decreases, and throughput improvements provide concrete evidence of operational benefit. MIT research found organisations implementing continuous change with frequent measurement achieved a twenty-fold reduction in manufacturing cycle time whilst maintaining adaptive capacity.
Quality improvements: Track defect rates, rework cycles, and customer satisfaction scores pre and post-implementation. These metrics connect change efforts directly to business outcomes leadership cares about.
Productivity measures: Output per employee, time-to-completion for key tasks, and capacity utilisation rates demonstrate whether the change is delivering promised efficiency gains.
Indirect performance indicators:
Employee engagement scores: Research demonstrates a strong correlation between change management effectiveness and employee engagement. Studies found that effective change management is a precursor to both employee engagement and productivity, with employee engagement mediating the relationship between change and performance outcomes.
Absenteeism and turnover rates: Change fatigue manifests in measurable workforce impacts. Research shows 54% of change-fatigued employees actively look for new roles, compared to just 26% of those experiencing low fatigue.
Help desk and support metrics: The volume and nature of support requests often reveal adoption challenges. Declining ticket volumes combined with increasing proficiency indicates successful embedding.
Critical consideration: change saturation. Research reveals that 78% of employees report feeling saturated by change, and 48% of those experiencing change fatigue report feeling more tired and stressed at work. Organisations must monitor workload and capacity indicators alongside performance metrics. The goal isn’t maximum change volume – it’s optimal change outcomes. Empirical studies demonstrate that when saturation thresholds are crossed, productivity experiences sharp declines as employees struggle to maintain focus across competing priorities.
Metric 4: Training Effectiveness and Competency Development
Training is often treated as a box-ticking exercise – sessions delivered, attendance recorded, job done. This approach fails to capture whether learning actually occurred, and more importantly, whether it translated into changed behaviour.
Comprehensive training effectiveness measurement:
Pre and post-training assessments: Knowledge tests administered before and after training reveal actual learning gains. Studies show effective training programmes achieve 30% improvement in employees’ understanding of new systems and processes.
Competency assessments: Move beyond knowledge testing to practical skill demonstration. “Show me” testing requires employees to demonstrate proficiency, not just recall information.
Training satisfaction scores: While not sufficient alone, participant feedback on relevance, quality, and applicability provides important signals. Research indicates that 90% satisfaction rates correlate with effective programmes.
Time-to-competency: How long does it take for new starters or newly transitioned employees to reach full productivity? Shortened competency curves indicate effective capability building.
Connecting training to behaviour change:
Skill application rates: What percentage of trained behaviours are being applied 30, 60, and 90 days post-training? This measures transfer from learning to doing.
Performance improvement: Are trained employees demonstrating measurably better performance in relevant areas? Connect training outcomes to operational metrics.
Certification and accreditation completion: For changes requiring formal qualification, track completion rates and pass rates as indicators of workforce readiness.
The key insight is that training effectiveness should be measured in terms of behaviour change, not just learning. A change initiative might achieve 100% training attendance and high satisfaction scores whilst completely failing to shift on-the-ground behaviours. The metrics that matter connect training inputs to adoption outputs.
Metric 5: Return on Investment and Benefit Realisation
ROI measurement transforms change management from perceived cost centre to demonstrated value driver. Research from McKinsey shows organisations with effective change management achieve an average ROI of 143%, compared to just 35% for those without – a four-fold difference that demands attention from any commercially minded executive.
Calculating change management ROI:
The fundamental formula is straightforward:
Change Management ROI= (Benefits attributable to change management − Cost of change management ) / Cost of change management
However, the challenge lies in accurate benefit attribution. Not all project benefits result from change management activities – technology capabilities, process improvements, and market conditions all contribute. The key is establishing clear baselines and using control groups where possible to isolate change management’s specific contribution.
One aspect about change management ROI is that you need to think broader than just the cost of change management. You also need to take into account the value created (or value creation). To read more about this check out our article – Why using change management ROI calculations severely limits its value.
Benefit categories to track:
Financial metrics: Cost savings, revenue increases, avoided costs, and productivity gains converted to monetary value. Be conservative in attributions – overstatement undermines credibility.
Adoption-driven benefits: The percentage of project benefits realised correlates directly with adoption rates. Research indicates 80-100% of project benefits depend on people adopting new ways of working.
Risk mitigation value: What costs were avoided through effective resistance management, reduced implementation delays, and lower failure rates? Studies show organisations rated as “change accelerators” experience 264% more revenue growth compared to companies with below-average change effectiveness.
Benefits realisation management:
Benefits don’t appear automatically at go-live. Active management throughout the project lifecycle ensures intended outcomes are actually achieved.
Establish benefit baselines: Clearly document pre-change performance against each intended benefit.
Define benefit owners: Assign accountability for each benefit to specific business leaders, not just the project team.
Create benefit tracking mechanisms: Regular reporting against benefit targets with variance analysis and corrective actions.
Extend measurement beyond project close: Research confirms that benefit tracking should continue post-implementation, as many benefits materialise gradually.
Reporting to leadership:
Frame ROI conversations in terms executives understand. Rather than presenting change management activities, present outcomes:
“This initiative achieved 93% adoption within 60 days, enabling full benefit realisation three months ahead of schedule.”
“Our change approach reduced resistance-related delays by 47%, delivering $X in avoided implementation costs.”
“Continuous feedback loops identified critical process gaps early, preventing an estimated $Y in rework costs.”
Building Your Measurement Dashboard
Effective change measurement requires systematic infrastructure, not ad-hoc data collection. A well-designed dashboard provides real-time visibility into change progress and enables proactive intervention.
Balance leading and lagging indicators: Leading indicators enable early intervention; lagging indicators confirm actual results. You need both for effective change management.
Align with business language: Present metrics in terms leadership understands. Translate change jargon into operational and financial language.
Enable drill-down: High-level dashboards should allow investigation into specific teams, regions, or issues when needed.
Define metrics before implementation: Establish what will be measured and how before the change begins. This ensures appropriate baselines and consistent data collection.
Use multiple measurement approaches: Combine quantitative metrics with qualitative assessments. Surveys, observations, and interviews provide context that numbers alone miss.
Track both leading and lagging indicators: Monitor predictive measures alongside outcome measures. Leading indicators provide early warning; lagging indicators confirm results.
Implement continuous monitoring: Regular checkpoints enable course corrections. Research shows continuous feedback approaches produce 30-40% improvements in adoption rates compared to annual or quarterly measurement cycles.
Leveraging Digital Change Tools
As organisations invest in digital platforms for managing change portfolios, measurement capabilities expand dramatically. Tools like The Change Compass enable practitioners to move beyond manual tracking to automated, continuous measurement at scale.
Digital platform capabilities:
Automated data collection: System usage analytics, survey responses, and engagement metrics collected automatically, reducing administrative burden whilst improving data quality.
Real-time dashboards: Live visibility into adoption rates, readiness scores, and engagement levels across the change portfolio.
Predictive analytics: AI-powered insights that identify at-risk populations before issues escalate, enabling proactive rather than reactive intervention.
Cross-initiative analysis: Understanding patterns across multiple changes reveals insights invisible at individual project level – including change saturation risks and resource optimisation opportunities.
Stakeholder-specific reporting: Different audiences need different views. Digital tools enable tailored reporting for executives, project managers, and change practitioners.
The shift from manual measurement to integrated digital platforms represents the future of change management. When change becomes a measurable, data-driven discipline, practitioners can guide organisations through transformation with confidence and clarity.
Frequently Asked Questions
What are the most important metrics to track for change management success?
The five essential metrics are: adoption rate and utilisation (measuring actual behaviour change), stakeholder engagement and readiness (predicting future adoption), productivity and performance impact (demonstrating business value), training effectiveness and competency development (ensuring capability), and ROI and benefit realisation (quantifying financial return). Research shows organisations tracking these metrics achieve significantly higher success rates than those relying on activity-based measures alone.
How do I measure change adoption effectively?
Effective adoption measurement goes beyond simple usage counts to examine speed of adoption (how quickly target groups reach proficiency), ultimate utilisation (what percentage of the workforce is actively using new processes), proficiency levels (quality of adoption), and feature depth (are people using full functionality or just basic features). Implement automated tracking where possible and use baseline comparisons to demonstrate progress.
What is the ROI of change management?
Research indicates change management ROI typically ranges from 3:1 to 7:1, with organisations seeing $3-$7 return for every dollar invested. McKinsey research shows organisations with effective change management achieve average ROI of 143% compared to 35% without. The key is connecting change management activities to measurable outcomes like increased adoption rates, faster time-to-benefit, and reduced resistance-related costs.
How often should I measure change progress?
Continuous measurement significantly outperforms point-in-time assessments. Research shows organisations using continuous feedback achieve 30-40% improvements in adoption rates compared to those with quarterly or annual measurement cycles. Implement weekly operational tracking, monthly leadership reviews, and quarterly strategic assessments for comprehensive visibility.
What’s the difference between leading and lagging indicators in change management?
Leading indicators predict future outcomes – they include training completion rates, early usage patterns, stakeholder engagement levels, and feedback sentiment. Lagging indicators confirm actual results – sustained performance improvements, full workflow integration, business outcome achievement, and long-term behaviour retention. Effective measurement requires both: leading indicators enable early intervention whilst lagging indicators demonstrate real impact.
How do I demonstrate change management value to executives?
Frame conversations in business terms executives understand: benefit realisation, ROI, risk mitigation, and strategic outcomes. Present data showing correlation between change management investment and project success rates. Use concrete examples: “This initiative achieved 93% adoption, enabling $X in benefits three months ahead of schedule” rather than “We completed 100% of our change activities.” Connect change metrics directly to business results.