“Is the project on track?” “Are we hitting milestones?” “What’s the budget status?”
Here’s the question almost no one asks:
“What is this change doing to our operational performance right now?”
Not after go-live. Not in a post-implementation review. Right now, during the transition, while people are absorbing the change and running the operation simultaneously.
The silence around this question reveals a fundamental blind spot in how organisations manage transformation. Everyone assumes there will be a temporary productivity dip. They accept it as inevitable. But almost no one measures it. No one knows if it’s a 5% dip or a 25% dip. No one tracks how long recovery takes. And when you’re running multiple changes across the enterprise, those dips stack, compound, and create operational crises that leadership only discovers after significant damage has occurred.
The research on performance dips: what we know and what we ignore
The phenomenon of performance decline during organisational change is well-documented. Research consistently shows measurable productivity drops during implementation periods, yet few organisations actively track these impacts in real time.
The magnitude of performance loss
Studies examining various types of change initiatives reveal striking patterns:
ERP implementations: Performance dips range from 10% to 25% on average, with some organisations experiencing dips as high as 40%.
Enterprise system implementations: Productivity losses range from 5% to 50% depending on the organisation and system complexity.
Electronic health record (EHR) systems: Performance dips can reach 5% to 60%, particularly when high customisation is required.
Digital transformations: McKinsey research found organisations typically experience 10% to 15% productivity dips during implementation phases.
Supply chain systems: Average productivity losses sit at 12%.
These aren’t marginal impacts. A 25% productivity dip in a customer service operation processing 10,000 transactions weekly means 2,500 fewer transactions completed. A 15% dip in a manufacturing environment translates directly to output reduction, delayed shipments, and revenue impact. Yet most organisations discover these impacts only after they’ve compounded into visible crises.
Why performance dips occur
The mechanisms behind performance decline during change are well understood from cognitive and operational perspectives:
Cognitive load and task switching: Research on divided attention shows that complex tasks combined with frequent switching between demands significantly degrade performance. Employees navigating new systems whilst maintaining BAU operations experience measurable increases in error rates and reaction times.
Learning curves and proficiency gaps: Even with comprehensive training, real-world application of new processes reveals gaps between classroom scenarios and operational reality. The proficiency developed in controlled training environments doesn’t immediately transfer to production complexity.
Workaround proliferation: When new systems don’t match actual workflow requirements, employees develop workarounds. These workarounds initially appear functional but create hidden dependencies, data quality issues, and cascading problems that surface weeks later.
Support capacity constraints: As implementation teams scale back intensive go-live support, incident resolution slows. Issues that were resolved in minutes during week one take hours or days by week three, compounding operational delays.
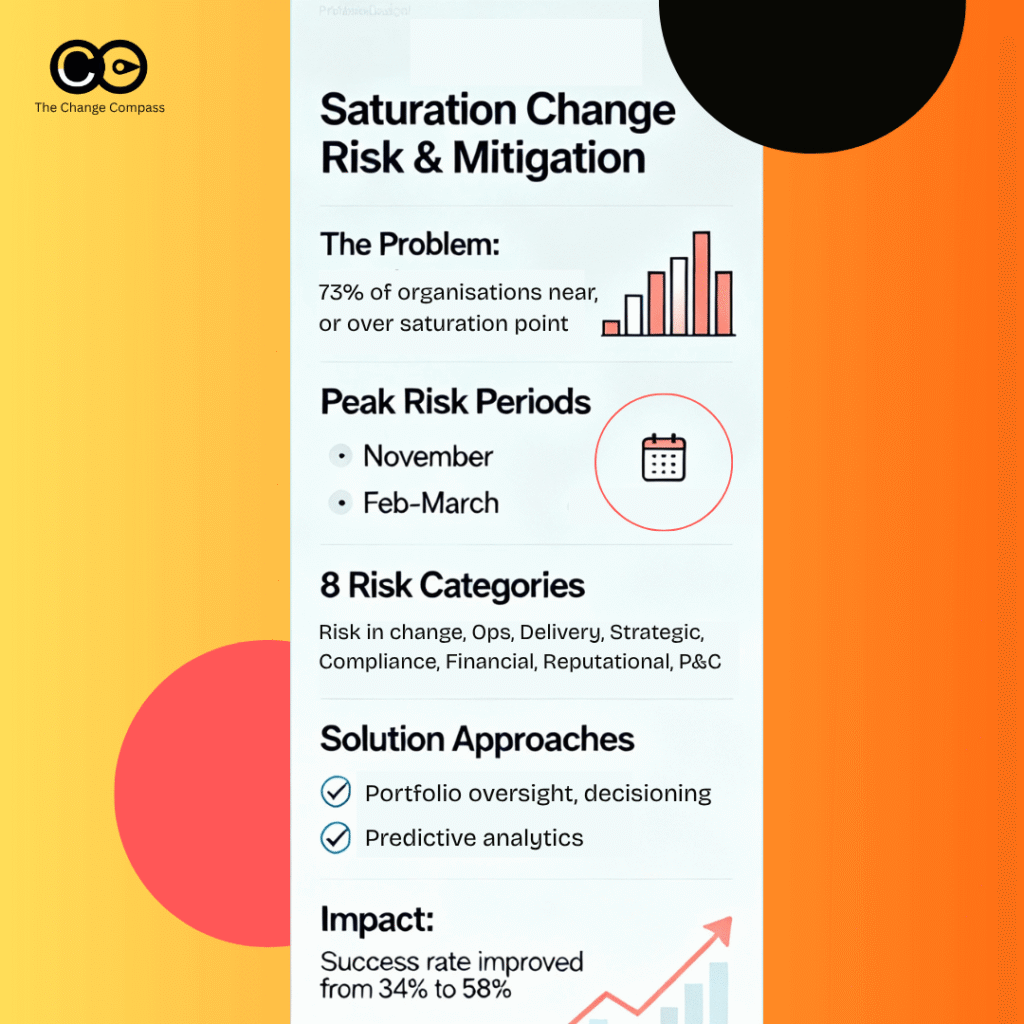
Change saturation: When multiple initiatives land concurrently, performance impacts don’t add linearly—they compound exponentially. Research shows that 48% of employees experiencing change fatigue report increased stress and tiredness, directly impacting productivity.
The recovery timeline reality
Without structured change management and continuous monitoring, organisations experience extended recovery periods. Research indicates:
Without effective change management: Productivity at week three sits at 65-75% of pre-implementation levels, with recovery timelines extending 4-6 months.
With effective change management: Recovery happens within 60-90 days, with continuous measurement approaches achieving 25-35% higher adoption rates than single-point assessments.
The difference isn’t marginal. It’s the difference between a brief, managed disruption and a prolonged operational crisis that undermines the business case for change.
The compounding problem: multiple changes, invisible impacts
The performance dip research cited above assumes a critical condition that rarely exists in modern enterprises: one change at a time.
Most organisations today manage portfolios of concurrent initiatives. A finance function implements a new ERP system whilst rolling out revised compliance processes and restructuring the shared services team. A healthcare system deploys new clinical documentation software whilst updating scheduling systems and migrating financial platforms. A telecommunications company launches customer portal changes whilst implementing billing system upgrades and operational support system modifications.
When concurrent changes overlap, impacts don’t simply add up, they multiply.
The mathematics of compound disruption
Consider a realistic scenario: Three initiatives land across the same operations team within 12 weeks:
Initiative A (customer data platform): Expected 12% productivity dip
Initiative B (revised underwriting workflow): Expected 15% productivity dip
Initiative C (updated operational dashboard): Expected 8% productivity dip
If these were sequential, total disruption time would span perhaps 18-24 weeks with three distinct dip-and-recovery cycles. Challenging, but manageable.
When concurrent, the mathematics change. Employees don’t experience 12% + 15% + 8% = 35% productivity loss. They experience cognitive overload that drives productivity losses exceeding 40-50% because:
Attention fragments across three learning curves simultaneously
Support capacity spreads thin across three incident response systems
Training saturation occurs as employees attend sessions for multiple systems without time to embed any
Workarounds interact as temporary solutions in one system create problems in another
Psychological capacity depletes as change fatigue sets in
Research confirms this pattern. Organisations managing multiple concurrent initiatives report 78% of employees feeling saturated by change, with change-fatigued employees showing 54% higher turnover intentions. The productivity dip becomes not a temporary disruption but a sustained operational degradation lasting months.
The visibility gap
Here’s the critical problem: Most organisations lack the data infrastructure to see this happening in real time.
Research shows only 12% of organisations measure change impact across their portfolio, meaning 88% lack fundamental data needed to identify saturation before it undermines initiatives. Without portfolio-level visibility, leaders discover compound disruption only after:
Customer complaints spike
Error rates become unacceptable
Revenue targets are missed
Employee turnover accelerates
Projects are declared “failures” despite solid technical execution
By then, the cost of remediation far exceeds the cost of prevention.
Why organisations don’t track operational performance during change
If the research is clear and the impacts are measurable, why do so few organisations track operational performance during transitions?
Assumption that disruption is inevitable
Many leaders treat productivity dips as unavoidable costs of change, like renovation dust. “We’re implementing a major system, of course there will be disruption.” This mindset accepts performance loss as fate rather than a variable that leadership actions can influence.
Research challenges this assumption. Studies show that whilst some disruption accompanies complex change, the magnitude and duration are directly influenced by how well the transition is managed. High-performing organisations experience minimal performance penalties precisely because they track, intervene, and course-correct based on operational data.
Lack of baseline data
You can’t measure a dip if you don’t know the baseline. Many organisations lack established operational metrics or track them inconsistently. When change arrives, there’s no reliable pre-change performance level to compare against.
Without baselines, statements like “adoption is going well” or “the team is adjusting” remain subjective assessments unsupported by evidence. Leaders operate on impression rather than data.
Measurement infrastructure gaps
Even organisations with operational metrics often lack systems to correlate performance changes with change activities. They know processing times have increased or error rates have risen, but they can’t pinpoint whether the cause is the new system rollout, the concurrent process redesign, seasonal volume spikes, or unrelated factors.
This correlation gap means operational performance remains in one dashboard, project status in another, and no integration connects them. Steering committees review project milestones without visibility into business impact.
Focus on project metrics over business outcomes
Traditional project governance emphasises activity-based metrics: milestones completed, training sessions delivered, defects resolved. These metrics matter for project execution but don’t answer the question executives actually care about: Is the business performing through this change?
Research from McKinsey shows organisations tracking meaningful operational KPIs during change implementation achieve 51% success rates compared to just 13% for those that don’t, making change efforts four times more likely to succeed when measurement focuses on business outcomes rather than project activities.
Change management credibility gap
When change practitioners report on soft metrics like “stakeholder sentiment” or “readiness scores” without connecting them to hard operational outcomes, they struggle to maintain executive attention. Leaders want to know: What is this doing to our operation? If change management can’t answer with data, the discipline loses credibility.
The solution isn’t to abandon readiness and adoption metrics, those remain essential. The solution is to connect them explicitly to operational performance, demonstrating that well-managed change readiness translates into maintained or improved business outcomes.
What to measure: identifying operational metrics that matter
The first step in tracking operational performance during change is identifying which metrics genuinely reflect business health. Not every metric matters equally, and tracking too many creates noise rather than insight.
The 3-5 critical metrics principle
Focus on the 3-5 operational metrics that matter most to the business. These should be:
Directly tied to business outcomes: Metrics that executive leadership already monitors for business health, not change-specific proxies.
Sensitive to operational disruption: Metrics that would visibly shift if people struggle with new systems or processes.
Measurable at appropriate frequency: Metrics you can track weekly or daily during peak disruption periods, not quarterly lagging indicators.
Understandable to all stakeholders: Metrics that don’t require explanation. “Processing time” is clear. “Readiness index” requires interpretation.
Operational metric categories by function
Different functions have different critical metrics. Here are examples across common areas:
Customer service and support operations:
Average handling time per transaction
First-call resolution rate
Customer satisfaction scores (CSAT)
Ticket backlog age and volume
Escalation rates to supervisors
Manufacturing and production:
Throughput volume (units per shift/day/week)
Cycle time from order to completion
Defect rates and rework percentages
Equipment utilisation rates
On-time delivery percentages
Finance and accounting:
Invoice processing time
Days sales outstanding (DSO)
Error rates in journal entries or reconciliations
Month-end close timeline
Payment processing accuracy
Sales and revenue operations:
Quote-to-order conversion time
Sales cycle length
Forecast accuracy
Pipeline velocity
Customer onboarding time
Healthcare clinical operations:
Patient wait times
Documentation completion rates
Medication error rates
Bed turnover time
Chart completion timeliness
Technology and IT operations:
System availability and uptime
Mean time to resolution (MTTR) for incidents
Change success rate
Deployment frequency
Service desk ticket volume
The specific metrics vary by industry and function, but the principle holds: choose metrics that executives already care about, that reflect operational health, and that would visibly shift if change is disrupting performance.
Leading vs lagging operational indicators
Operational performance measurement should include both leading indicators (predictive) and lagging indicators (confirmatory):
Leading indicators provide early warning of emerging problems:
Training completion rates relative to go-live timing
Support ticket volumes and trends
System login frequency and feature usage
Employee sentiment scores
Workaround documentation requests
Lagging indicators confirm actual outcomes:
Throughput volumes and processing times
Error rates and rework
Customer satisfaction scores
Revenue and cost performance
Quality metrics
Both matter. Leading indicators enable intervention before performance degrades visibly. Lagging indicators validate whether interventions worked.
How to establish baselines before change lands
Baselines are the foundation of meaningful performance measurement. Without knowing where you started, you can’t quantify impact or demonstrate recovery.
Baseline establishment process
Step 1: Identify the 3-5 critical operational metrics for the impacted function or team, using the principles outlined above.
Step 2: Determine baseline measurement period. Ideally, capture 8-12 weeks of pre-change data to account for normal operational variation. This reveals typical performance ranges rather than single-point snapshots.
Step 3: Document baseline performance. Calculate average performance, typical variation ranges, and any seasonal patterns. For example: “Average processing time: 4.2 minutes per transaction, typical range 3.8-4.6 minutes, with slight increases during month-end periods.”
Step 4: Establish thresholds for concern. Define what magnitude of change warrants intervention. A 5% dip might be acceptable and temporary. A 20% dip signals serious disruption requiring immediate action.
Step 5: Communicate baselines to governance. Ensure steering committees and leadership understand baseline performance and what “normal” looks like before change begins.
Baseline data sources
Where does baseline data come from? Most organisations already collect operational metrics—they just don’t use them for change impact assessment:
Operational dashboards and business intelligence systems: Most functions track performance metrics for ongoing management. Leverage existing data rather than creating parallel measurement systems.
Time and motion studies: For processes lacking automated measurement, conduct time studies during the baseline period to understand current performance.
Quality assurance and audit data: Error rates, defect rates, and compliance metrics often exist in quality systems.
Customer feedback systems: CSAT scores, Net Promoter Scores (NPS), and complaint volumes provide external validation of operational performance.
Financial systems: Cost per transaction, revenue per employee, and similar financial metrics reflect operational efficiency.
The goal isn’t to create new measurement infrastructure (though sometimes that’s necessary). The goal is to systematically capture and document performance levels before change disrupts them.
When baselines don’t exist
What if you don’t have historical operational data? You’re implementing change into a new function, or metrics were never established?
Option 1: Rapid baseline establishment. Implement measurement 4-6 weeks before go-live. Not ideal, but better than no baseline.
Option 2: Industry benchmarks. Use external benchmarks to establish expected performance ranges. “Industry average for similar operations is X; we’ll track whether we maintain that level through change”.
Option 3: Relative baselines. If absolute metrics aren’t available, track relative changes: “Week 1 post-change will be our baseline; we’ll track whether performance improves or degrades from that point”.
Option 4: Proxy metrics. If direct operational metrics don’t exist, identify proxies that correlate with performance: employee hours worked, system transaction volumes, customer contact rates.
None of these are as robust as established baselines, but all provide more insight than flying blind.
Tracking operational performance during the transition
Once baselines exist and change begins, systematic tracking transforms assumptions into evidence.
Measurement cadence during change
Pre-change (weeks -8 to 0): Establish and validate baselines. Ensure data collection processes are reliable.
Go-live week (week 1): Daily measurement. Performance during go-live is artificial due to hypervigilant support, but daily tracking captures immediate issues.
Peak disruption period (weeks 2-4): Daily or at minimum three times per week. This is when performance dips typically peak and when early intervention matters most.
Stabilisation period (weeks 5-12): Weekly measurement. Performance should trend toward baseline recovery. Persistent gaps signal unresolved issues.
Post-stabilisation (months 4-6): Biweekly or monthly measurement. Confirm sustained recovery and benefit realisation.
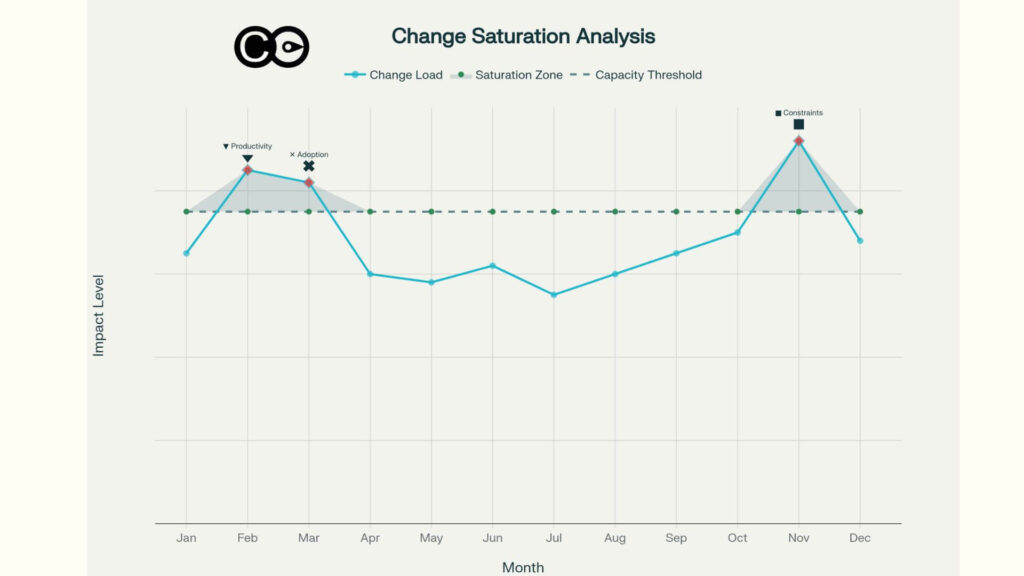
The frequency isn’t arbitrary. Research shows week two is when peak disruption hits as artificial go-live conditions end and real operational complexity surfaces. Daily measurement during this window enables rapid response.
Creating integrated performance dashboards
Operational performance data should integrate with change rollout timelines in unified dashboards visible to all governance forums.
Dashboard design principles:
Integrate operational and change metrics on one view. Left side shows project milestones and change activities. Right side shows operational performance trends. The correlation becomes immediately visible.
Use visual indicators for thresholds. Green (within acceptable variance), amber (approaching concern threshold), red (intervention required). Leaders grasp status at a glance.
Overlay change activities on performance trend lines. When a performance dip occurs, the dashboard shows which change activity coincided. “Error rates spiked on Day 8, coinciding with the process redesign go-live”.
Enable drill-down to detail. High-level executive dashboards show summary trends. Operational leaders can drill into specific teams, shifts, or transaction types.
Update in real-time or near-real-time. During peak disruption periods, yesterday’s data is stale. Automated feeds from operational systems provide current visibility.
Interpretation and intervention triggers
Data without interpretation is noise. Establish clear triggers for intervention:
Threshold 1: Acceptable variance (0-10% from baseline). Continue monitoring. Some variation is normal. No intervention required unless sustained beyond expected recovery window.
Threshold 2: Concern zone (10-20% from baseline). Investigate causes. Increase support intensity. Prepare contingency actions if deterioration continues.
Threshold 3: Critical disruption (>20% from baseline). Immediate intervention required. Options include: pausing additional changes, deploying emergency support resources, simplifying rollout scope, or reverting to previous state if business impact is severe.
These thresholds aren’t universal—they depend on operational criticality and baseline variability. A 15% dip in non-critical administrative processing might be tolerable. A 15% dip in patient safety metrics or financial controls is not.
Bringing operational data into steering committees
Measurement matters only if it drives decisions. That means bringing operational performance data into governance forums where change priorities and resources are allocated.
Shifting the steering committee conversation
Traditional steering committee agendas focus on project status:
Milestone completion
Budget and timeline status
Risk and issue logs
Upcoming deliverables
These remain important, but they’re insufficient. The agenda must expand to include:
Operational performance trends: “Processing times increased 18% in week two, exceeding our concern threshold. Here’s what we’re seeing and what we’re doing about it.”
Business impact quantification: “The performance dip has reduced throughput by 2,200 transactions this week, representing approximately $X in delayed revenue.”
Correlation analysis: “The spike in errors correlates with the data migration issues we identified in last week’s incident log. Resolution is in progress.”
Recovery trajectory: “Performance recovered from 72% of baseline in week three to 85% in week four. We expect full recovery by week six based on current trend.”
Intervention decisions: “Given concurrent Initiative B launching next week whilst Initiative A is still stabilising, we recommend deferring Initiative B by three weeks to avoid compound disruption.”
This isn’t just reporting. It’s decision-making based on evidence.
Earning credibility through operational language
When change practitioners speak in operational terms … throughput, error rates, processing times, customer satisfaction, they speak the language of business leaders.
“Stakeholder readiness scores improved from 6.2 to 7.1” has less impact than “Processing times returned to baseline levels, confirming the team has embedded the new workflow.” Both metrics have value, but operational outcomes resonate more powerfully with executives focused on business performance.
Research confirms this principle. Change management earns its seat at leadership tables by demonstrating measurable impact on business outcomes, not just change activities.
Portfolio-level operational visibility
When organisations manage multiple concurrent changes, steering committees need portfolio-level operational visibility:
Heatmaps showing which teams are under highest operational pressure from concurrent changes. “Customer service is absorbing changes from Initiatives A, B, and C simultaneously. Operations is managing only Initiative B.”
Aggregate performance impact across all initiatives. “Total enterprise productivity is at 82% of baseline due to overlapping disruptions. Sequencing Initiative D would drop this to 74%, exceeding our risk tolerance.”
Recovery timelines across the portfolio. “Initiative A has stabilised. Initiative B is in week-three disruption. Initiative C hasn’t launched yet. This sequencing allows focused support where it’s needed most.”
This portfolio view enables trade-off decisions impossible at individual project level: defer lower-priority changes, reallocate support resources to highest-disruption areas, establish blackout periods for overloaded teams.
Real-world application: case example
Consider a mid-sized financial services firm implementing three concurrent technology changes affecting the same operations team:
Week 1 (Initiative A go-live): Daily tracking showed processing time increased to 3.8 hours (+19%), error rate jumped to 7.1% (+69%), volume dropped to 165 applications (-8%). CSAT held at 4.2.
Response: Increased on-site support from two FTEs to five. Extended helpdesk hours. Daily huddles to address emerging issues.
Week 3: Processing time recovered to 3.4 hours (+6% from baseline). Error rate improved to 5.1% (+21% from baseline but improving). Volume reached 174 applications (-3%). CSAT recovered to 4.3.
Decision point: Initiative B was scheduled to launch Week 4. Dashboard data showed Initiative A was stabilising but not yet fully recovered. Leadership faced a choice:
Option 1: Proceed with Initiative B as scheduled. Risk compound disruption whilst Initiative A is still embedded.
Option 2: Defer Initiative B launch by three weeks, allowing full Initiative A stabilisation before introducing new disruption.
Decision: Defer Initiative B. The operational data made visible the risk of compound impact. Three-week deferral extended overall timeline but protected operational performance and adoption quality.
Outcome: By Week 6, Initiative A metrics returned to baseline. Initiative B launched Week 7 into a stabilised operation. The team absorbed Initiative B with minimal disruption (processing time peaked at +8% vs the +19% for Initiative A, because the team wasn’t simultaneously managing two changes). Initiative C launched Week 12 after Initiative B stabilised.
Total programme timeline: Extended by three weeks. Total operational disruption: Reduced by an estimated 40% because changes were sequenced to respect team capacity rather than pushed concurrently for timeline optimisation.
This is what operational performance tracking enables: evidence-based decisions that optimise for business outcomes rather than project schedules.
Building the measurement infrastructure
For organisations without existing infrastructure to track operational performance during change, building capability requires systematic steps:
Month 1: Inventory and assess
Identify all operational metrics currently tracked across functions
Assess data quality, frequency, and accessibility
Identify gaps where critical functions lack performance metrics
Catalogue data sources and integration points
Month 2: Establish standards
Define the 3-5 critical metrics for each major function
Standardise calculation methods and reporting formats
Establish baseline measurement protocols
Create integration between operational systems and change dashboards
Month 3: Pilot measurement
Select one upcoming change initiative for pilot
Implement full baseline-to-recovery tracking
Test dashboard integration and governance reporting
Refine based on pilot learnings
Month 4-6: Scale enterprise-wide
Roll out standardised operational performance tracking across all major initiatives
Train project managers and change leads on measurement protocols
Integrate operational performance into steering committee agendas
Establish portfolio-level tracking for concurrent changes
Month 7+: Continuous improvement
Refine metrics based on what proves most predictive
Automate data collection and reporting where possible
Expand portfolio visibility and decision-making capability
Build predictive models based on historical change-performance correlation
Tools like The Change Compass provide ready-built infrastructure for this type measurement, enabling organisations to skip months of development and begin tracking immediately.
The strategic value of operational performance tracking
When organisations systematically track operational performance during change, the benefits extend beyond individual project success:
Evidence-based portfolio prioritisation: Data showing which teams are under highest operational pressure enables rational sequencing decisions rather than political negotiations.
Predictive capacity planning: Historical patterns of disruption by change type enable future planning: “ERP implementations typically create 12-15% productivity dips for 8-10 weeks. We need to plan support resources and defer lower-priority work accordingly.”
ROI validation: Connecting change investments to sustained operational improvements demonstrates value. “Initiative A cost $2M and delivered sustained 8% processing time improvement, representing $4M annual benefit.”
Change management credibility: Speaking the language of operational outcomes positions change management as strategic business capability, not administrative overhead.
Risk mitigation: Early detection of performance degradation enables intervention before crises emerge, protecting customer experience and revenue.
Research confirms these benefits are measurable. Organisations using continuous operational performance measurement during change achieve 25-35% higher adoption rates and 6.5x higher initiative success rates than those relying on project activity metrics alone.
Frequently Asked Questions
Why is it important to track operational performance during change implementation?
Tracking operational performance during change reveals the real business impact of transformation in real-time, enabling early intervention before productivity dips become crises. Research shows organisations measuring operational performance during change achieve 51% success rates compared to 13% for those focused only on project metrics.
What operational metrics should I track during organisational change?
Focus on 3-5 metrics that matter most to your business: processing times, error rates, throughput volumes, customer satisfaction scores, and cycle times. These should be metrics executives already monitor for business health, sensitive to disruption, and measurable at high frequency.
How large are typical productivity dips during change implementation?
Research shows productivity dips range from 5-60% depending on change complexity and management approach. ERP implementations average 10-25% dips, digital transformations see 10-15% drops, and EHR systems can experience 5-60% depending on customisation. With effective change management, recovery occurs within 60-90 days.
How do you establish baseline metrics before a change initiative?
Capture 8-12 weeks of pre-change performance data for your critical operational metrics. Document average performance, typical variation ranges, and seasonal patterns. Establish thresholds defining acceptable variance vs concern levels. Communicate baselines to governance before change begins.
What happens when multiple changes impact operations simultaneously?
Concurrent changes create compound disruption where productivity losses multiply rather than add. When three initiatives each causing 10-15% dips overlap, total impact often exceeds 40-50% due to cognitive overload, fragmented attention, and support capacity constraints. Portfolio-level tracking becomes essential.
How often should operational performance be measured during change?
Measure daily during go-live week and peak disruption period (weeks 2-4), when performance dips typically peak. Shift to weekly measurement during stabilisation (weeks 5-12), then biweekly or monthly post-stabilisation. High-frequency measurement during critical windows enables rapid intervention.
What is the connection between change management and operational performance?
Effective change management directly influences operational performance during transition. Organisations with structured change management recover from productivity dips within 60-90 days and achieve 25-35% higher adoption rates. Without change management, recovery extends to 4-6 months with productivity remaining 65-75% of baseline.
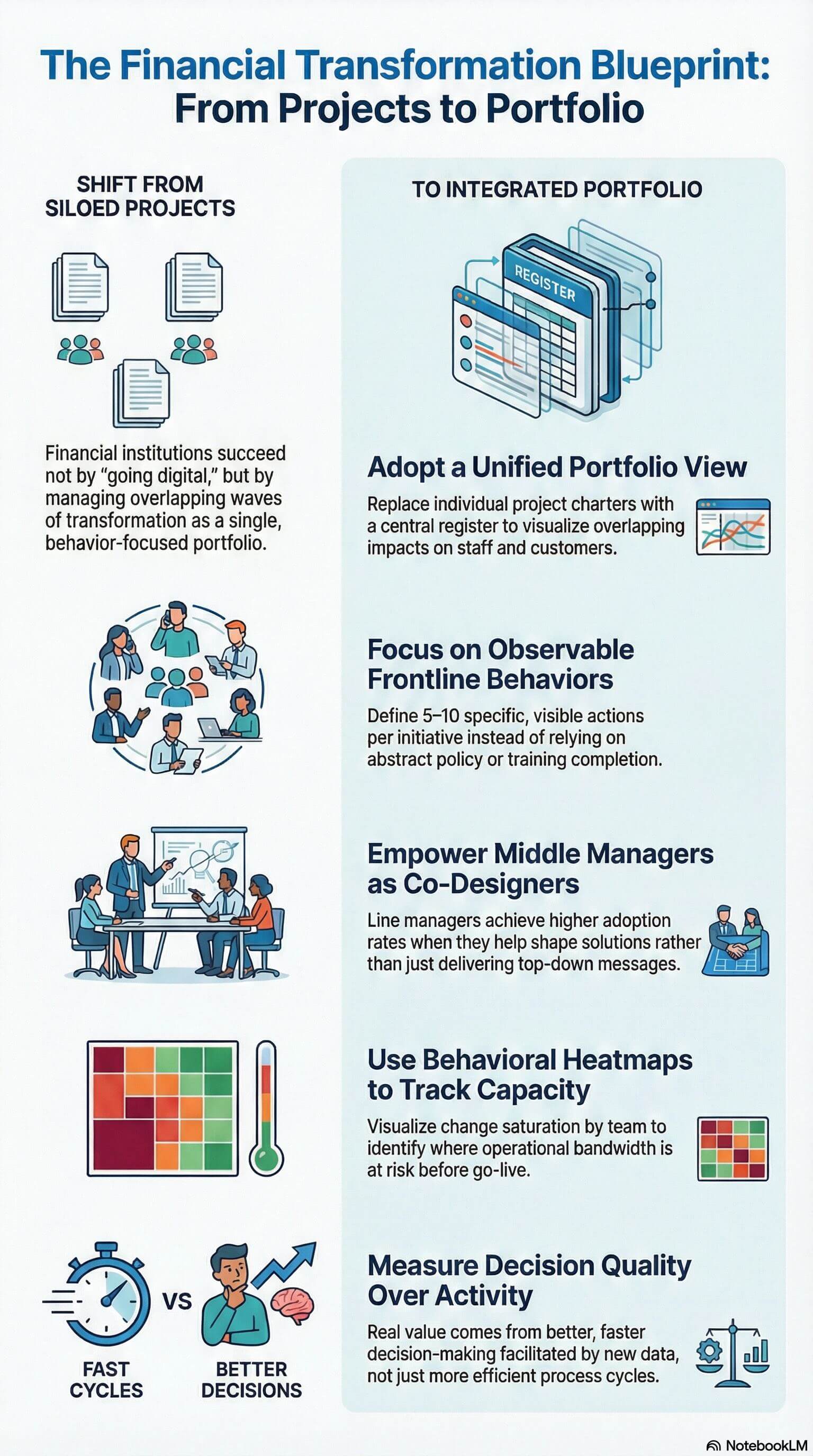
Financial services transformation refers to the structured programmes through which banks, insurers, wealth managers and capital markets firms reshape how they deliver value, manage risk and operate at the front, middle and back office. It is not a single category of change. The eight core transformation types observed across the sector include core banking and platform modernisation, regulatory and risk-driven change, customer experience and digital channel programmes, data and AI transformation, operational efficiency, mergers and divestments, culture and operating model transformation, and sustainability and climate-driven change. Each lands on the workforce differently, which is why portfolio-level change intelligence matters.
Financial services firms are not just “going digital” – they are running overlapping waves of highly specific transformations that rewrite how risk is managed, products are delivered, and work gets done. Research from BCG and McKinsey shows that banks and insurers that treat these as a managed portfolio, backed by clear behavioural expectations and data, deliver significantly better outcomes than those that approach each program in isolation. Prosci’s work in financial services further reinforces that projects with strong change management are multiple times more likely to meet or exceed objectives, particularly where leaders and middle managers are visibly engaged.
Below are the most common transformation types in financial services, the specific change management challenges they create, and concrete tactics you can apply straight away. The focus is on behaviour change, the pivotal role of middle managers, disciplined portfolio management, and data and tracking that go far beyond simple status reporting.
The eight transformation archetypes in financial services
Across major banks, insurers, and wealth managers, transformation activity tends to fall into a repeatable set of archetypes, regardless of geography.
Regulatory and risk transformation
Core systems and architecture modernisation
Customer, product, and distribution transformation
Operating model and cost transformation
Finance and performance management transformation
Data, analytics, and AI transformation
Culture, leadership, and ways of working
Sustainability and ESG transformation
Each of these requires different change tactics in practice, even though they often compete for the same people, customers, and operational bandwidth.
1. Regulatory and risk transformation
Examples include major AML and KYC uplifts, operational resilience programs (such as CPS 230 style requirements), conduct risk remediation, and Basel or capital and liquidity changes.
Typical change management challenges
Compliance fatigue: Staff feel there is always another policy, training, or control, which can drive surface-level completion without genuine behaviour change.
Fragmented ownership: Risk, compliance, operations, and product all run “their” reg programs without a single view of impacts on customers and staff.
Middle manager overload: Line managers are the ones chasing attestations and juggling rosters for training, but rarely see the full picture of what their people are experiencing across the portfolio.
Practical tactics and strategies
Start with a regulatory change portfolio view, not a single project charter
Create a simple but comprehensive register of all in-flight and planned regulatory changes, with columns for impacted segments, business units, timeframes, and required behaviours (for example, “always verify source of funds for X category”).
Visualise this as a heatmap by team or branch so middle managers can see when their people are being hit from multiple directions at once.
Translate regulations into a small set of observable frontline behaviours
Instead of leading with policy clauses, define 5 to 10 behaviours per initiative that are easy to observe in the field, such as “no account opened without documented beneficial owner verification”.
Train middle managers to coach against these specific behaviours and to log what they see weekly in a simple tool or platform. This creates a feedback loop that is much richer than generic training completion data.
Use middle managers as co-designers, not just messengers
Hold short design sessions by segment (for example, branch leaders, contact centre leaders) to jointly simplify processes and scripts that meet both regulatory and operational needs.
Research on change in banking shows that when line managers feel they have shaped the solution, adoption and sustainment rates rise markedly compared with purely top-down designs.
Track “real” compliance through behaviour and outcome metrics
Combine leading indicators (observation checklists, targeted QA, mystery shopping) with lagging indicators (breach numbers, near misses, remediation volumes).
Use a portfolio dashboard to compare teams and regions, then direct support and coaching where variance is highest rather than applying blanket training.
2. Core systems and architecture modernisation
This includes core banking or policy administration replacements, payment rail upgrades, and large-scale cloud and integration programs.
Typical change management challenges
The impact is often underestimated: core changes alter hundreds of micro behaviours such as how exceptions are handled or how data is captured.
Go live dates are treated as the finish line even though research by McKinsey shows that value realisation often lags well beyond technical cutover in financial institutions.
Middle managers are asked to handle extra work during migration at the same time as hitting BAU efficiency and risk targets.
Practical tactics and strategies
Build a process impact catalogue that middle managers can own
Map each process affected by core changes and assign a named operational owner, typically a middle manager or team leader.
For each process, define specific behaviour changes, such as “use system workflow instead of offline spreadsheet”, and how they will be measured (for example, utilisation of new paths, rework rates).
Use sequential “dress rehearsals” that focus on behaviours, not just technology
McKinsey’s research on technology transformation in financial services highlights the value of iterative testing in realistic conditions before full cutover.
Run rehearsals where real users process real or realistic work items end to end in the new system. Capture not only defects but also where people attempted to revert to old workarounds, and feed this back to middle managers as coaching material.
Give middle managers a short, structured playbook for stabilisation
Provide a stabilisation playbook that includes standard daily huddles, defect and workarounds logging templates, and a simple decision guide on what can be fixed locally versus escalated.
Track stabilisation metrics such as transaction turnaround time, error rates, and staff confidence scores by team, not only at program level, so support can be targeted quickly.
Tie portfolio decisions to operational capacity and risk appetite
Use the change portfolio to decide whether to pause or slow less critical initiatives in the same period so middle managers are not overwhelmed during cutover and stabilisation.
This is where tools that can visualise initiative overlaps, change saturation, and operational risk at a portfolio level are particularly valuable.
3. Customer, product, and distribution transformation
Examples include end-to-end journey redesigns for onboarding, lending or claims, open banking and ecosystem plays, and repositioning of wealth or insurance propositions.
Typical change management challenges
Competing priorities between customer experience, revenue, and risk objectives.
Channel conflict: frontline distribution leaders may fear losing volume to digital or partner channels.
Behaviour change is subtle: the same journey may exist, but the tone, sequencing, and use of data in interactions are different.
Practical tactics and strategies
Make a journey portfolio and clarify the “north star” (or Southern Cross for us in the southern hemisphere) for each
Identify your key journeys and map which initiatives touch each one in the next 12 to 24 months.
For each journey, define a small set of target behaviours at manager and staff level, for example “always check eligibility in the new tool before discussing price” or “offer digital completion as default, not exception”.
Give middle managers ownership of journey performance, not just channel metrics
Provide them with an integrated data view of their customers’ journey, such as abandonment points, complaint themes, and NPS, not just product sales volumes.
Prosci’s work shows that when direct managers can see clear cause and effect between new behaviours and improved outcomes, they are much more likely to coach and reinforce those behaviours consistently.
Use small experiments with clear behavioural hypotheses
Rather than rolling out a single script or process nationally, test two or three alternative behaviours in small pilots and measure the impact on both customer and risk outcomes.
Middle managers should be directly involved in choosing which variant to scale and in sharing practical stories with their peers on what worked and why.
Track experience and adoption through both quantitative and qualitative data
Supplement NPS and conversion metrics with quick frontline and middle manager pulse checks focused on questions such as “what is getting in the way of using the new journey consistently”.
Use this data in fortnightly or monthly portfolio reviews where you decide whether to double down, adjust, or stop specific initiatives touching each journey.
4. Operating model and cost transformation
Typical examples are zero-based cost reviews, shared service consolidation, offshoring or nearshoring of operations, and enterprise agile or product model shifts.
Typical change management challenges
Perceived as cost cutting rather than value creation, which triggers defensive behaviours and talent flight.
Middle managers are squeezed between efficiency targets and expectations to support their people through change.
Benefits often erode over 12 to 24 months if behaviours drift back to old patterns once scrutiny eases.
Practical tactics and strategies
Make benefits and behaviour explicit in the portfolio ledger
For each initiative, identify target benefits (for example, 20 per cent reduction in manual handling) and the specific behaviours required to sustain those benefits, such as “route 95 per cent of claims through straight through processing”.
Track both in the same dashboard and review monthly with operational leaders and finance so there is a shared understanding of progress and slippage.
Give middle managers a clear deal: support in exchange for ownership
Research into transformation programs finds that where managers are given clarity about their role, additional support such as coaching or extra resources, and recognition for benefits delivery, they are more likely to own difficult trade offs.
Make it explicit that success is not just “hitting the savings number” but embedding new ways of working in team routines, and track their performance against both dimensions.
Use data and stories together to rebuild trust
Publish regular, transparent data on how operating changes are affecting service levels, risk incidents, and staff engagement.
Encourage middle managers to bring forward examples where a new operating model led to better customer outcomes or staff development, and use these stories in broader communication to avoid a purely cost narrative.
5. Finance and performance management transformation
This includes moving to rolling forecasts, implementing new profitability and capital allocation models, and automating finance processes such as record to report and procure to pay.
Typical change management challenges
Strong professional identity among finance teams built around existing tools and methods.
Stakeholders outside finance may see new performance frameworks as opaque or unfair.
Middle managers in business units may not be equipped to interpret new metrics and adjust behaviours accordingly.
Practical tactics and strategies
Co-design new performance narratives with business managers
Rather than simply issuing new dashboards, hold short design workshops with middle managers from the front line, operations, and support functions where they test drive the new metrics using real scenarios.
Ask explicitly “what decisions would you make differently with this information” and refine the design until those decisions are clear and actionable.
Track decision quality, not only forecast accuracy
Research into finance transformation highlights that the real value comes from better, faster decisions, not only more efficient forecasting cycles.
For major decisions, such as pricing changes or capital allocation shifts, log whether the new data and tools were used and whether outcomes improved relative to prior approaches. Feed this back into coaching for both finance and business leaders.
Equip middle managers with simple “metric to behaviour” guides
Produce short guides that link each key metric to two or three concrete behaviours. For example, if a branch profitability measure now includes risk-adjusted capital, suggest specific actions like “rebalance lending mix” or “target fee leakage in particular segments”.
Monitor usage of these guides through manager feedback and pulse surveys, and refine them based on real examples from the field.
6. Data, analytics, and AI transformation
Financial institutions are investing heavily in data platforms, self service analytics, and AI for use cases such as fraud detection, credit decisioning, and personalised marketing.
Typical change management challenges
Significant trust issues: staff may not understand how models work or may fear being replaced.
Shadow solutions: teams revert to spreadsheets or legacy reports if new tools are hard to use.
Ethics and risk questions that cut across many parts of the organisation.
Practical tactics and strategies
Treat analytics and AI initiatives as a single, governed portfolio
Maintain a central register of models and analytics products that records owners, stakeholders, risk level, and intended user behaviours (for example, “check AI recommendation first, then apply judgement”).
Use this to identify where the same people are being targeted by multiple tools and to coordinate training and communication.
Focus on building data literacy via middle managers
Prosci and others emphasise that direct supervisors are the strongest influence on individual adoption of new ways of working in financial services.
Train middle managers in basic concepts such as data quality, bias, and model limitations, and equip them with talking points and scenarios so they can explain tools to their teams in practical, contextualised language.
Monitor adoption at granular levels and act fast on early signals
Track usage by team and role, such as logins, feature use, and whether recommendations are accepted or overridden.
If adoption lags, use targeted interventions such as peer demos facilitated by respected middle managers, or small design adjustments based on user feedback.
Integrate ethics and model risk into everyday behaviour expectations
Reinforce that challenging or overriding a model when it does not make sense is a desired behaviour, not a failure.
Track and review override patterns in governance forums, and surface positive examples where human judgement improved outcomes.
7. Culture, leadership, and ways of working
Many financial services firms are moving to more agile, customer centric, and data driven cultures, often supported by new leadership frameworks and people processes.
Typical change management challenges
Culture is often treated as a separate workstream rather than something woven through each transformation.
Middle managers receive high level values statements but little practical support on how to change their own daily behaviour.
Progress is hard to quantify without robust measures.
Practical tactics and strategies
Anchor culture change in a small set of observable leadership behaviours
For example, “leaders ask for data before making decisions”, “leaders run regular retrospectives on major changes”, “leaders acknowledge and learn from failures”.
Incorporate these into leadership expectations, 360 feedback, and performance processes.
Equip middle managers with routines that embed cultural behaviours
Provide concrete rituals such as weekly team huddles focusing on customer outcomes, monthly story sharing sessions, or “metrics and learning” segments in regular meetings.
Track the use of these routines and their impact on engagement and performance over time.
Use pulse surveys and qualitative data as serious inputs to portfolio decisions
Research into transformation suggests that employee sentiment is a leading indicator of whether change will stick.
Integrate sentiment and behavioural data into your portfolio dashboards alongside financial and delivery metrics, and be prepared to slow or reshape initiatives where signals are deteriorating.
8. Sustainability and ESG transformation
Banks and insurers are reworking portfolios, risk frameworks, and disclosures to meet rising expectations around climate and social responsibility.
Typical change management challenges
Perceived as compliance or marketing rather than core to strategy.
Complex, cross-cutting metrics that middle managers may find abstract.
Potential tension between short term financial targets and long term ESG goals.
Practical tactics and strategies
Connect ESG targets to day to day portfolio decisions
For example, include financed emissions or responsible investment metrics in the criteria used to prioritise initiatives in the change portfolio.
Make it explicit which projects are expected to contribute to ESG outcomes and how progress will be measured.
Give middle managers practical decision tools
Provide simple decision trees and case examples that show how to apply ESG policies in realistic client situations, such as when to escalate a lending decision related to high emission sectors.
Track how often managers use these tools and collect feedback on where policies or guidance are unclear.
Report ESG progress alongside traditional financial metrics
Integrate ESG indicators into regular performance reviews, so they become part of the everyday language of success rather than an annual report exercise.
Highlight examples where ESG aligned decisions have also led to strong commercial outcomes.
Making portfolio management, the work of middle managers, and data work together
Across all eight archetypes, three levers consistently differentiate successful financial services transformations from those that disappoint:
Active, data led change portfolio management: A single, integrated view of initiatives, impacts, timing, and risks that is used to make real trade off decisions.
Empowered, equipped middle managers: Line managers who understand the why, have clear behavioural expectations for their teams, and are given the tools and time to support change.
Rich, behaviour focused data and tracking: Moving beyond activity counts and training completions to observable behaviours, sentiment, outcome measures, and feedback loops at team level.
Firms that approach change in this integrated way are better able to handle the intensity and complexity of modern financial services transformation and to sustain benefits beyond the life of individual programs.
Platforms like The Change Compass illustrate how portfolio level insights, operational data, and change metrics can be combined to support these practices in a systematic way across financial services organisations.
Frequently asked questions
How do we practically start with change portfolio management if we are currently project centric?
Start by building a simple central register of all significant initiatives with fields for impacted business units and customer segments, timing, and estimated people impact. Use this in a monthly forum with senior and middle managers to review hotspots, adjust timing, and agree priorities.
What should middle managers in financial services focus on first when there are many concurrent changes?
Research and practice suggest that middle managers create the most value when they focus on clarifying expectations for their teams, coaching observable behaviours linked to outcomes, and escalating systemic issues that individual teams cannot fix alone.
Which metrics are most powerful for tracking behaviour change during transformation?
A balanced set usually includes leading indicators such as adoption and utilisation of new tools or processes, observation or QA scores of key behaviours, and employee sentiment about specific changes, combined with lagging indicators such as customer outcomes, risk incidents, or process performance.
How can we make research and data resonate with senior leaders who are sceptical about change management?
Use a small number of solid external references, such as Prosci and McKinsey studies on success rates in transformation, alongside your own internal data to show the relationship between strong change practices, risk outcomes, and financial performance.
Where can we find more detailed examples tailored to financial services?
Industry specific insights and case based guidance are increasingly available from consulting firms and specialist platforms. For example, The Change Compass knowledge hub focuses on how financial services organisations can use change data and portfolio analytics to plan and deliver complex transformations more effectively.
Most organisations anticipate disruption around go-live. That’s when attention focuses on system stability, support readiness, and whether the new process flows will actually work. But the real crisis arrives 10 to 14 days later.
Week two is when peak disruption hits. Not because the system fails, as often it’s running adequately by then, but because the gap between how work was supposed to work and how it actually works becomes unavoidable. Training scenarios don’t match real workflows. Data quality issues surface when people need specific information for decisions. Edge cases that weren’t contemplated during design hit customer-facing teams. Workarounds that started as temporary solutions begin cascading into dependencies.
This pattern appears consistently across implementation types. EHR systems experience it. ERP platforms encounter it. Business process transformations face it. The specifics vary, but the timing holds: disruption intensity peaks in week two, then either stabilises or escalates depending on how organisations respond.
Understanding why this happens, what value it holds, and how to navigate it strategically is critical, especially when organisations are managing multiple disruptions simultaneously across concurrent projects. That’s where most organisations genuinely struggle.
The pattern: why disruption peaks in week 2
Go-live day itself is deceptive. The environment is artificial. Implementation teams are hypervigilant. Support staff are focused exclusively on the new system. Users know they’re being watched. Everything runs at artificial efficiency levels.
By day four or five, reality emerges. Users relax slightly. They try the workflows they actually do, not the workflows they trained on. They hit the branch of the process tree that the scripts didn’t cover. A customer calls with a request that doesn’t fit the designed workflow. Someone realises they need information from the system that isn’t available in the standard reports. A batch process fails because it references data fields that weren’t migrated correctly.
These issues arrive individually, then multiply.
Research on implementation outcomes shows this pattern explicitly. A telecommunications case study deploying a billing system shows week one system availability at 96.3%, week two still at similar levels, but by week two incident volume peaks at 847 tickets per week. Week two is not when availability drops. It’s when people discover the problems creating the incidents.
Here’s the cascade that makes week two critical:
Days 1 to 7: Users work the happy paths. Trainers are embedded in operations. Ad-hoc support is available. Issues get resolved in real time before they compound. The system appears to work.
Days 8 to 14: Implementation teams scale back support. Users begin working full transaction volumes. Edge cases emerge systematically. Support systems become overwhelmed. Individual workarounds begin interconnecting. Resistance crystallises, and Prosci research shows resistance peaks 2 to 4 weeks post-implementation. By day 14, leadership anxiety reaches a peak. Finance teams close month-end activities and hit system constraints. Operations teams process their full transaction volumes and discover performance issues. Customer service teams encounter customer scenarios not represented in training.
Weeks 3 to 4: Either stabilisation occurs through focused remediation and support intensity, or problems compound further. Organisations that maintain intensive support through week two recover within 60 to 90 days. Those that scale back support too early experience extended disruption lasting months.
The research quantifies this. Performance dips during implementation average 10 to 25%, with complex systems experiencing dips of 40% or more. These dips are concentrated in weeks 1 to 4, with week two as the inflection point. Supply chain systems average 12% productivity loss. EHR systems experience 5 to 60% depending on customisation levels. Digital transformations typically see 10 to 15% productivity dips.
The depth of the dip depends on how well organisations manage the transition. Without structured change management, productivity at week three sits at 65 to 75% of pre-implementation levels, with recovery timelines extending 4 to 6 months. With effective change management and continuous support, recovery happens within 60 to 90 days.
Understanding the value hidden in disruption
Most organisations treat week-two disruption as a problem to minimise. They try to manage through it with extended support, workarounds, and hope. But disruption, properly decoded, provides invaluable intelligence.
Each issue surfaced in week two is diagnostic data. It tells you something real about either the system design, the implementation approach, data quality, process alignment, or user readiness. Organisations that treat these issues as signals rather than failures extract strategic value.
Process design flaws surface quickly.
A customer-service workflow that seemed logical in design fails when customer requests deviate from the happy path. A financial close process that was sequenced one way offline creates bottlenecks when executed at system speed. A supply chain workflow that assumed perfect data discovers that supplier codes haven’t been standardised. These aren’t implementation failures. They’re opportunities to redesign processes based on actual operational reality rather than theoretical process maps.
Integration failures reveal incompleteness.
A data synchronisation issue between billing and provisioning systems appears in week two when the volume of transactions exposing the timing window is processed. A report that aggregates data from multiple systems fails because one integration wasn’t tested with production data volumes. An automated workflow that depends on customer master data being synchronised from an upstream system doesn’t trigger because the synchronisation timing was wrong. These issues force the organisation to address integration robustness rather than surfacing in month six when it’s exponentially more costly to fix.
Training gaps become obvious.
Not because users lack knowledge, as training was probably thorough, but because knowledge retention drops dramatically once users are under operational pressure. That field on a transaction screen no one understood in training becomes critical when a customer scenario requires it. The business rule that sounded straightforward in the classroom reveals nuance when applied to real transactions. Workarounds start emerging not because the system is broken but because users revert to familiar mental models when stressed.
Data quality problems declare themselves.
Historical data migration always includes cleansing steps. Week two is when cleansed data collides with operational reality. Customer address data that was “cleaned” still has variants that cause matching failures. Supplier master data that was de-duplicated still includes records no one was aware of. Inventory counts that were migrated don’t reconcile with physical systems because the timing window wasn’t perfect. These aren’t test failures. They’re production failures that reveal where data governance wasn’t rigorous enough.
System performance constraints appear under load.
Testing runs transactions in controlled batches. Real operations involve concurrent transaction volumes, peak period spikes, and unexpected load patterns. Performance issues that tests didn’t surface appear when multiple users query reports simultaneously or when a batch process runs whilst transaction processing is also occurring. These constraints force decisions about infrastructure, system tuning, or workflow redesign based on evidence rather than assumptions.
Adoption resistance crystallises into actionable intelligence.
Resistance in weeks 1 to 2 often appears as hesitation, workaround exploration, or question-asking. By week two, if resistance is adaptive and rooted in legitimate design or readiness concerns, it becomes specific. “The workflow doesn’t work this way because of X” is more actionable than “I’m not ready for this system.” Organisations that listen to week-two resistance can often redesign elements that actually improve the solution.
The organisations that succeed at implementation are those that treat week-two disruption as discovery rather than disaster. They maintain support intensity specifically because they know disruption reveals critical issues. They establish rapid response mechanisms. They use the disruption window to test fixes and process redesigns with real operational complexity visible for the first time.
This doesn’t mean chaos is acceptable. It means disruption, properly managed, delivers value.
The reality when disruption stacks: multiple concurrent go-lives
The week-two disruption pattern assumes focus. One system. One go-live. One disruption window. Implementation teams concentrated. Support resources dedicated. Executive attention singular.
This describes almost no large organisations actually operating today.
Most organisations manage multiple implementations simultaneously. A financial services firm launches a new customer data platform, updates its payments system, and implements a revised underwriting workflow across the same support organisations and user populations. A healthcare system deploys a new scheduling system, upgrades its clinical documentation platform, and migrates financial systems, often on overlapping timelines. A telecommunications company implements BSS (business support systems) whilst updating OSS (operational support systems) and launching a new customer portal.
When concurrent disruptions overlap, the impacts compound exponentially rather than additively.
Disruption occurring at week two for Initiative A coincides with go-live week one for Initiative B and the first post-implementation month for Initiative C. Support organisations are stretched across three separate incident response mechanisms. Training resources are exhausted from Initiative A training when Initiative B training ramps. User psychological capacity, already strained from one system transition, absorbs another concurrently.
Research on concurrent change shows this empirically. Organisations managing multiple concurrent initiatives report 78% of employees feeling saturated by change. Change-fatigued employees show 54% higher turnover intentions compared to 26% for low-fatigue employees. Productivity losses don’t add up; they cascade. One project’s 12% productivity loss combined with another’s 15% loss doesn’t equal 27% loss. Concurrent pressures often drive losses exceeding 40 to 50%.
The week-two peak disruption of Initiative A, colliding with go-live intensity for Initiative B, creates what one research study termed “stabilisation hell”, a period where organisations struggle simultaneously to resolve unforeseen problems, stabilise new systems, embed users, and maintain business-as-usual operations.
Consider a real scenario. A financial services firm deployed three major technology changes into the same operations team within 12 weeks. Initiative A: New customer data platform. Initiative B: Revised loan underwriting workflow. Initiative C: Updated operational dashboard.
Week four saw Initiative A hit its week-two peak disruption window. Incident volumes spiked. Data quality issues surfaced. Workarounds proliferated. Support tickets exceeded capacity. Week five, Initiative B went live. Training for a new workflow began whilst Initiative A fires were still burning. Operations teams were learning both systems on the fly.
Week eight, Initiative C launched. By then, operations teams had learned two new systems, embedded neither, and were still managing Initiative A stabilisation issues. User morale was low. Stress was high. Error rates were increasing. The organisation had deployed three initiatives but achieved adoption of none. Each system remained partially embedded, each adoption incomplete, each system contributing to rather than resolving operational complexity.
Research on this scenario is sobering. 41% of projects exceed original timelines by 3+ months. 71% of projects surface issues post go-live requiring remediation. When three projects encounter week-two disruptions simultaneously or overlappingly, the probability that all three stabilise successfully drops dramatically. Adoption rates for concurrent initiatives average 60 to 75%, compared to 85 to 95% for single initiatives. Recovery timelines extend from 60 to 90 days to 6 to 12 months or longer.
The core problem: disruption is valuable for diagnosis, but only if organisations have capacity to absorb it. When capacity is already consumed, disruption becomes chaos.
Strategies to prevent operational collapse across the portfolio
Preventing operational disruption when managing concurrent initiatives requires moving beyond project-level thinking to portfolio-level orchestration. This means designing disruption strategically rather than hoping to manage through it.
Step 1: Sequence initiatives to prevent concurrent peak disruptions
The most direct strategy is to avoid allowing week-two peak disruptions to occur simultaneously.
This requires mapping each initiative’s disruption curve. Initiative A will experience peak disruption weeks 2 to 4. Initiative B, scheduled to go live once Initiative A stabilises, will experience peak disruption weeks 8 to 10. Initiative C, sequenced after Initiative B stabilises, disrupts weeks 14 to 16. Across six months, the portfolio experiences three separate four-week disruption windows rather than three concurrent disruption periods.
Does sequencing extend overall timeline? Technically yes. Initiative A starts week one, Initiative B starts week six, Initiative C starts week twelve. Total programme duration: 20 weeks vs 12 weeks if all ran concurrently. But the sequencing isn’t linear slowdown. It’s intelligent pacing.
More critically: what matters isn’t total timeline, it’s adoption and stabilisation. An organisation that deploys three initiatives serially over six months with each fully adopted, stabilised, and delivering value exceeds in value an organisation that deploys three initiatives concurrently in four months with none achieving adoption above 70%.
Sequencing requires change governance to make explicit trade-off decisions. Do we prioritise getting all three initiatives out quickly, or prioritise adoption quality? Change portfolio management creates the visibility required for these decisions, showing that concurrent Initiative A and B deployment creates unsustainable support load, whereas sequencing reduces peak support load by 40%.
Step 2: Consolidate support infrastructure across initiatives
When disruptions must overlap, consolidating support creates capacity that parallel support structures don’t.
Most organisations establish separate support structures for each initiative. Initiative A has its escalation path. Initiative B has its own. Initiative C has its own. This creates three separate 24-hour support rotations, three separate incident categorisation systems, three separate communication channels.
Consolidated support establishes one enterprise support desk handling all issues concurrently. Issues get triaged to the appropriate technical team, but user-facing experience is unified. A customer-service representative doesn’t know whether their problem stems from Initiative A, B, or C, and shouldn’t have to. They have one support number.
Consolidated support also reveals patterns individual support teams miss. When issues across Initiative A and B appear correlated, when Initiative B’s workflow failures coincide with Initiative A data synchronisation issues, consolidated support identifies the dependency. Individual teams miss this connection because they’re focused only on their initiative.
Step 3: Integrate change readiness across initiatives
Standard practice means each initiative runs its own readiness assessment, designs its own training programme, establishes its own change management approach.
This creates training fragmentation. Users receive five separate training programmes from five separate change teams using five different approaches. Training fatigue emerges. Messaging conflicts create confusion.
Integrated readiness means:
One readiness framework applied consistently across all initiatives
Consolidated training covering all initiatives sequentially or in integrated learning paths where possible
Unified change messaging that explains how the portfolio of changes supports a coherent organisational direction
Shared adoption monitoring where one dashboard shows readiness and adoption across all initiatives simultaneously
This doesn’t require initiatives to be combined technically. Initiative A and B remain distinct. But from a change management perspective, they’re orchestrated.
Research shows this approach increases adoption rates 25 to 35% compared to parallel change approaches.
Step 4: Create structured governance over portfolio disruption
Change portfolio management governance operates at two levels:
Initiative level: Sponsor, project manager, change lead, communications lead manage Initiative A’s execution, escalations, and day-to-day decisions.
Portfolio level: Representatives from all initiatives meet fortnightly to discuss:
Emerging disruptions across all initiatives
Support load analysis, identifying where capacity limits are being hit
Escalation patterns and whether issues are compounding across initiatives
Readiness progression and whether adoption targets are being met
Adjustment decisions, including whether to slow Initiative B to support Initiative A stabilisation
Portfolio governance transforms reactive problem management into proactive orchestration. Instead of discovering in week eight that support capacity is exhausted, portfolio governance identifies the constraint in week four and adjusts Initiative B timeline accordingly.
Tools like The Change Compass provide the data governance requires. Real-time dashboards show support load across initiatives. Heatmaps reveal where particular teams are saturated. Adoption metrics show which initiatives are ahead and which are lagging. Incident patterns identify whether issues are initiative-specific or portfolio-level.
Step 5: Use disruption windows strategically for continuous improvement
Week-two disruptions, whilst painful, provide a bounded window for testing process improvements. Once issues surface, organisations can test fixes with real operational data visible.
Rather than trying to suppress disruption, portfolio management creates space to work within it:
Days 1 to 7: Support intensity is maximum. Issues are resolved in real time. Limited time for fundamental redesign.
Days 8 to 14: Peak disruption is more visible. Teams understand patterns. Workarounds have emerged. This is the window to redesign: “The workflow doesn’t work because X. Let’s redesign process Y to address this.” Changes tested at this point, with full production visibility, are often more effective than changes designed offline.
Weeks 3 to 4: Stabilisation period. Most issues are resolved. Remaining issues are refined through iteration.
Organisations that allocate capacity specifically for week-two continuous improvement often emerge with more robust solutions than those that simply try to push through disruption unchanged.
Operational safeguards: systems to prevent disruption from becoming crisis
Beyond sequencing and governance, several operational systems prevent disruption from cascading into crisis:
Load monitoring and reporting
Before initiatives launch, establish baseline metrics:
Support ticket volume (typical week has X tickets)
Incident resolution time (typical issue resolves in Y hours)
User productivity metrics (baseline is Z transactions per shift)
System availability metrics (target is 99.5% uptime)
During disruption weeks, track these metrics daily. When tickets approach 150% of baseline, escalate. When resolution times extend beyond 2x normal, adjust support allocation. When productivity dips exceed 30%, trigger contingency actions.
This monitoring isn’t about stopping disruption. It’s about preventing disruption from becoming uncontrolled. The organisation knows the load is elevated, has data quantifying it, and can make decisions from evidence rather than impression.
Readiness assessment across the portfolio
Don’t run separate readiness assessments. Run one portfolio-level readiness assessment asking:
Which populations are ready for Initiative A?
Which are ready for Initiative B?
Which face concurrent learning demand?
Where do we have capacity for intensive support?
Where should we reduce complexity or defer some initiatives?
This single assessment reveals trade-offs. “Operations is ready for Initiative A but faces capacity constraints with Initiative B concurrent. Options: Defer Initiative B two weeks, assign additional change support resources, or simplify Initiative B scope for operations teams.”
Blackout periods and pacing restrictions
Most organisations establish blackout periods for financial year-end, holiday periods, or peak operational seasons. Many don’t integrate these with initiative timing.
Portfolio management makes these explicit:
October to December: Reduced change deployment (year-end focus)
January weeks 1 to 2: No major launches (people returning from holidays)
July to August: Minimal training (summer schedules)
March to April: Capacity exists; good deployment window
Planning initiatives around blackout periods and organisational capacity rhythms rather than project schedules dramatically improves outcomes.
Contingency support structures
For initiatives launching during moderate-risk windows, establish contingency support plans:
If adoption lags 15% behind target by week two, what additional support deploys?
If critical incidents spike 100% above baseline, what escalation activates?
If user resistance crystallises into specific process redesign needs, what redesign process engages?
If stabilisation targets aren’t met by week four, what options exist?
This isn’t pessimism. It’s realistic acknowledgement that week-two disruption is predictable and preparations can address it.
Integrating disruption management into change portfolio operations
Preventing operational disruption collapse requires integrating disruption management into standard portfolio operations:
Month 1: Portfolio visibility
Map all concurrent initiatives
Identify natural disruption windows
Assess portfolio support capacity
Month 2: Sequencing decisions
Determine which initiatives must sequence vs which can overlap
Identify where support consolidation is possible
Establish integrated readiness framework
Month 3: Governance establishment
Launch portfolio governance forum
Establish disruption monitoring dashboards
Create escalation protocols
Months 4 to 12: Operational execution
Monitor disruption curves as predicted
Activate contingencies if necessary
Capture continuous improvement opportunities
Track adoption across portfolio
Tools supporting this integration, such as change portfolio platforms like The Change Compass, provide the visibility and monitoring capacity required. Real-time dashboards show disruption patterns as they emerge. Adoption tracking reveals whether initiatives are stabilising or deteriorating. Support load analytics identify bottleneck periods before they become crises.
The research imperative: what we know about disruption
The evidence on implementation disruption is clear:
Week-two peak disruption is predictable, not random
Disruption provides diagnostic value when organisations have capacity to absorb and learn from it
Concurrent disruptions compound exponentially, not additively
Sequencing initiatives strategically improves adoption and stabilisation vs concurrent deployment
Organisations with portfolio-level governance achieve 25 to 35% higher adoption rates
Recovery timelines for managed disruption: 60 to 90 days; unmanaged disruption: 6 to 12 months
The alternative to strategic disruption management is reactive crisis management. Most organisations experience week-two disruption reactively, scrambling to support, escalating tickets, hoping for stabilisation. Some organisations, especially those managing portfolios, are choosing instead to anticipate disruption, sequence it thoughtfully, resource it adequately, and extract value from it.
The difference in outcomes is measurable: adoption, timeline, support cost, employee experience, and long-term system value.
Frequently asked questions
Why does disruption peak specifically at week 2, not week 1 or week 3?
Week one operates under artificial conditions: hypervigilant support, implementation team presence, trainers embedded, users following scripts. Real patterns emerge when artificial conditions end. Week two is when users attempt actual workflows, edge cases surface, and accumulated minor issues combine. Peak incident volume and resistance intensity typically occur weeks 2 to 4, with week two as the inflection point.
Should organisations try to suppress week-two disruption?
No. Disruption reveals critical information about process design, integration completeness, data quality, and user readiness. Suppressing it masks problems. The better approach: acknowledge disruption will occur, resource support intensity specifically for the week-two window, and use the disruption as diagnostic opportunity.
How do we prevent week-two disruptions from stacking when managing multiple concurrent initiatives?
Sequence initiatives to avoid concurrent peak disruption windows. Consolidate support infrastructure across initiatives. Integrate change readiness across initiatives rather than running parallel change efforts. Establish portfolio governance making explicit sequencing decisions. Use change portfolio tools providing real-time visibility into support load and adoption across all initiatives.
What’s the difference between well-managed disruption and unmanaged disruption in recovery timelines?
Well-managed disruption with adequate support resources, portfolio orchestration, and continuous improvement capacity returns to baseline productivity within 60 to 90 days post-go-live. Unmanaged disruption with reactive crisis response, inadequate support, and no portfolio coordination extends recovery timelines to 6 to 12 months or longer, often with incomplete adoption.
Can change portfolio management eliminate week-two disruption?
No, and that’s not the goal. Disruption is inherent in significant change. Portfolio management’s purpose is to prevent disruption from cascading into crisis, to ensure organisations have capacity to absorb disruption, and to extract value from disruption rather than merely enduring it.
How does the size of an organisation affect week-two disruption patterns?
Patterns appear consistent: small organisations, large enterprises, government agencies all experience week-two peak disruption. Scale affects the magnitude. A 50-person firm’s week-two disruption affects everyone directly, whilst a 5,000-person firm’s disruption affects specific departments. The timing and diagnostic value remain consistent.
What metrics should we track during the week-two disruption window?
Track system availability (target: maintain 95%+), incident volume (expect 200%+ of normal), mean time to resolution (expect 2x baseline), support ticket backlog (track growth and aging), user productivity in key processes (expect 65 to 75% of baseline), adoption of new workflows (expect initial adoption with workaround development), and employee sentiment (expect stress with specific resistance themes).
How can we use week-two disruption data to improve future implementations?
Document incident patterns, categorise by root cause (design, integration, data, training, performance), and use these insights for process redesign. Test fixes during week-two disruption when full production complexity is visible. Capture workarounds users develop, as they often reveal legitimate unmet needs. Track which readiness interventions were most effective. Use this data to tailor future implementations.
Agile has become the technical operating model for large organisations. You’ll find Scrum teams in finance, Kanban boards in HR, Scaled Agile frameworks spanning entire technology divisions. The velocity and responsiveness are real. What’s also becoming real, though less often discussed, is the hidden cost: when agile technical delivery isn’t matched with agile change management, employees experience whiplash rather than transformation.
A financial services firm we worked with exemplifies the problem. They had implemented SAFe (Scaled Agile) across 150 people split into 12 Agile Release Trains (ARTs). Each ART could ship features in 2-week sprints. The technical execution was solid. But frontline teams found themselves managing changes from five different initiatives simultaneously. Loan officers had training sessions every two weeks. Operations teams were learning new systems before they’d embedded the previous one. The organisation was delivering change at maximum velocity into people who had hit their saturation limit months earlier. After three quarters, they’d achieved technical agility but created change fatigue that actually slowed adoption and spiked operations disruption.
This scenario repeats across industries because organisations may have solved the technical orchestration problem without solving the human orchestration problem. Scaled Agile frameworks like SAFe address how distributed technical teams coordinate delivery. They’re silent on how those technical changes orchestrate employee experience across the organisation. That silence is the gap this article addresses.
The agile norm and the coordination challenge it creates
Agile as a delivery model is now standard practice. What’s still emerging is how organisations manage the change that agile delivery creates at scale.
Here’s the distinction. When a single agile team builds a feature, the team manages its own change: they decide on testing approach, communication cadence, stakeholder engagement. When 12 ARTs build different capabilities simultaneously – a new customer data platform, a revised underwriting workflow, a redesigned payments system – the change impacts collide. Different teams create different messaging. Training runs parallel rather than sequenced. Employee readiness and adoption are fragmented across initiatives.
The heart of the problem is this: agile teams are optimised for one thing, delivering customer-facing capability quickly and iteratively. They operate with sprint goals, velocity metrics, and deployment cadences measured in days. Change – the human, business, and operational impacts of what’s being delivered – operates on different cycles. Change readiness takes weeks or months. Adoption roots over months. People can internalise 2-3 concurrent changes effectively; beyond that, fatigue or inadequate attention set in and adoption rates fall.
Research into agile transformations confirms this tension: 78% of employees report feeling saturated by change when managing concurrent initiatives, and organisations where saturation thresholds are exceeded experience measurable productivity declines and turnover acceleration. Yet these same organisations have achieved technical agile excellence.
The solution isn’t to slow agile delivery. It’s to apply agile principles to change itself – specifically, to orchestrate how multiple change initiatives coordinate their impacts on people and the organisation.
What standard agile practices deliver and where they fall short
Standard agile practices are designed around one core principle: break complex work into smaller discrete pieces, iterate fast in smaller cycles, and use small cross-functional teams to deliver customer outcomes efficiently.
Applied to technical delivery, this works remarkably well. Breaking a major system redesign into two-week sprints means you get feedback every fortnight. You can course-correct within days rather than discovering fatal flaws after six months of waterfall planning. Smaller teams move faster and communicate better than large programmes. Cross-functional teams reduce handoffs and accelerate decision-making.
The effectiveness is measurable. Organisations using iterative, feedback-driven approaches achieve 6.5 times higher success rates than those using linear project management. Continuous measurement delivers 25-35% higher adoption rates than single-point assessments.
But here’s where most organisations get stuck: they implement these technical agile practices without designing the connective glue across initiatives.
Agile thinking within a team doesn’t automatically create agile orchestration across teams. The coordination mechanisms required are different:
Within a team: Agile ceremonies (daily standups, sprint planning, retrospectives) keep a small group aligned. The team shares context daily and adjusts course together.
Across an enterprise with 12 ARTs: There’s no daily standup where everyone appears. There’s no single sprint goal. Different ARTs deploy on different cadences. Without explicit coordination structures, each team optimises locally – which means each team’s change impacts ripple outward without visibility into what other teams are doing.
A customer service rep experiences this fragmentation. Monday she’s in training for the new loan decision system (ART 1). Wednesday she learns the updated customer data workflow (ART 2). Friday she’s reoriented on the new phone system interface (ART 3). Each change is well-designed. Each training is clear. But the content and positioning of these may not be aligned, and their cumulative impact overwhelms the rep’s capacity to learn and embed new ways of working.
The gap isn’t in the quality of individual agile teams. The gap is in the orchestration infrastructure that says: “These three initiatives are landing simultaneously for this population. Let’s redesign sequencing or consolidate training or defer one initiative to create breathing room.” That kind of orchestration requires visibility and decision-making above the individual ART level.
The missing piece: Enterprise-level change coordination
A lot of large organisations have some aspects of scaled agile approach. SAFe includes Program Increment (PI) Planning – a quarterly event where 100+ people from multiple ARTs align on features, dependencies, and capacity across teams. PI Planning is genuinely useful for technical coordination. It prevents duplicate work. It surfaces dependency chains. It creates realistic capacity expectations.
But PI Planning is built for technical delivery, not change impact. It answers: “What will we build this quarter?” It doesn’t answer: “What change will people experience? Which teams face the most disruption? What’s the cumulative employee impact if we proceed as planned?”
This is where change portfolio management enters the picture.
Change portfolio management takes the same orchestration principle that PI Planning applies to features – explicit, cross-team coordination – and applies it to the human and business impacts of change. It answers questions PI Planning can’t:
How many concurrent changes is each role absorbing?
When do we have natural low-change periods where we can embed recent changes before launching new ones?
What’s the cumulative training demand if we proceed with current sequencing?
Are certain teams becoming change-saturated whilst others have capacity?
Which changes are creating the highest resistance, and what does that tell us about design or readiness?
Portfolio management provides three critical functions that distributed agile teams don’t naturally create:
1. Employee/customer change experience design
This means deliberately designing the end-to-end experience of change from the employee’s perspective, not the project’s perspective. If a customer service rep is affected by five initiatives, what’s the optimal way to sequence training? How do we consolidate messaging across initiatives? How do we create clarity about what’s changing vs. what’s staying the same?
Rather than asking “How does each project communicate its changes?”—which creates five separate messaging streams—portfolio management asks “How does the organisation communicate these five changes cohesively?” The difference is profound. It shifts from coordination to integration.
2. People impact monitoring and reporting
Portfolio management tracks metrics that individual projects miss:
Change saturation per roletype: Is the finance team absorbing 2 changes or 7?
Readiness progression: Are training completion rates healthy across initiatives or are they clustering in some areas?
Adoption trajectories: Post-launch, are people actually using new systems/processes or finding workarounds?
Fatigue indicators: Are turnover intentions rising in heavily impacted populations?
These metrics don’t appear in project dashboards because they’re enterprise metrics and not about project delivery. Individual projects see their own adoption. The portfolio sees whether adoption is hindered by saturation in an adjacent initiative.
3. Readiness and adoption design at organisational level
Rather than each project running its own readiness assessment and training programme, portfolio management creates:
A shared readiness framework applied consistently across initiatives, allowing apple-to-apple comparisons
Sequenced capability building (you embed the customer data system before launching the new workflow that depends on clean data)
Consolidated training calendars (rather than five separate training schedules)
Shared adoption monitoring (one dashboard showing whether organisations are actually using the changes or resisting them)
The orchestration infrastructure required
Supporting rapid transformation without burnout requires four specific systems:
1. Change governance across business and enterprise levels
Governance isn’t bureaucracy here. It’s decision-making structure. You need forums where:
Initiative-level change governance (exists in most organisations):
Project sponsor, change lead, communications lead meet weekly
Decisions: messaging, training content, resistance management, adoption tactics
Focus: making this project’s change land successfully
Representatives from each ART, plus HR, plus finance, plus communications
Meet biweekly
Decisions: sequencing of initiatives, portfolio saturation, resource allocation across change efforts, blackout periods
Focus: managing cumulative impact and capacity across all initiatives
The enterprise governance layer is where PI Planning concepts get applied to people. Just as technical PI Planning prevents two ARTs from building the same feature, enterprise change governance prevents two initiatives from saturating the same population simultaneously.
2. Load monitoring and reporting
You can’t manage what you don’t measure. Portfolio change requires visibility into:
Change unit allocation per role Create a simple matrix: Across the vertical axis, list all role types/teams. Across the horizontal axis, list all active initiatives (not just IT – include process changes, restructures, system migrations, anything requiring people to work differently). For each intersection, mark which initiatives touch which roles.
The heatmap becomes immediately actionable. If Customer Service is managing 4 decent-sized changes simultaneously, that’s saturation territory. If you’re planning to launch Programme 5, you know it cannot hit Customer Service until one of their current initiatives is embedded.
Saturation scoring Develop a simple framework:
1-2 concurrent changes per role = Green (sustainable)
4+ concurrent changes = Red (saturation, adoption at risk)
Track this monthly. When saturation appears, trigger decisions: defer an initiative, accelerate embedding of a completed initiative, add change support resources.
When you’re starting out this is the first step. However, when you’re managing a large enterprise with a large volume of projects as well as business-as-usual initiatives, you need finer details in rating the level of impact at an initiative and impact activity level.
Training demand consolidation Rather than five initiatives each scheduling 2-day training courses, portfolio planning consolidates:
Weeks 1-3: Data quality training (prerequisite for multiple initiatives)
Weeks 4-5: New systems training (customer data + general ledger)
Week 6: Process redesign workshop
Weeks 7-8: Embedding (no new training, focus on bedding in changes)
This isn’t sequential delivery (which would slow things down). It’s intelligent batching of learning so that people absorb multiple changes within a supportable timeframe rather than fragmenting across five separate schedules.
3. Shared understanding of heavy workload and blackout periods
Different parts of organisations experience different natural rhythms. Financial services has heavy change periods around year-end close. Retail has saturation during holiday season preparation. Healthcare has patient impact considerations that create unavoidable busy periods.
Portfolio management makes these visible explicitly:
Peak change load periods (identified 12 months ahead):
January: Post-holidays, people are fresh, capacity exists
March-April: Reporting season hits finance; new product launches hit customer-facing teams
June-July: Planning seasons reduce availability for major training
September-October: Budget cycles demand focus in multiple teams
November-December: Year-end pressures spike across organisation
Then when sponsors propose new initiatives, the portfolio team can say: “We can launch this in January when capacity exists. If you push for launch in March, it collides with reporting season and year-end planning—adoption will suffer.” This creates intelligent trade-offs rather than first-come-first-served initiative approval.
Blackout periods (established annually): Organisations might define:
June-July: No major new change initiation (planning cycles)
Week 1-2 January: No training or go-lives (people returning from holidays)
Week 1 December: No launches (focus shifting to year-end)
These aren’t arbitrary. They reflect when the organisation’s capacity for absorbing change genuinely exists or doesn’t.
4. Change portfolio tools that enable this infrastructure
Spreadsheets and email can’t manage enterprise change orchestration at scale. You need tools that:
The Change Compass and similar platforms provide:
Automated analytics generation: Each initiative updates its impacted roles. The tool instantly shows cumulative load by role.
Saturation alerts: When a population hits red saturation, alerts trigger for governance review.
Portfolio dashboard: Executives see at a glance which initiatives are proceeding, their status, and cumulative impact.
Readiness pulse integration: Monthly surveys track training completion, system adoption, and readiness across all initiatives simultaneously.
Adoption tracking: Post-launch data shows whether people are actually using new processes or finding workarounds.
Reporting and analytics: Portfolio leads can identify patterns (e.g., adoption rates are lower when initiatives launch with less than 2 weeks between training completion and go-live).
Tools like this aren’t luxury add-ons. They’re infrastructure. Without them, enterprise governance becomes opinionated conversations and unreliable. With them, you have actionable data. The value is usually at least in the millions annually in business value.
Bringing this together: Implementation roadmap
Month 1: Establish visibility
List all current and planned initiatives (next 12 months)
Create role type-level impact matrix
Generate first saturation heatmap
Brief executive team on portfolio composition
Month 2: Establish governance
Launch biweekly Change Coordination Council
Define enterprise change governance charter
Establish blackout periods for coming 12 months
Train initiative leads on portfolio reporting requirements
Month 3-4: Design consolidated change experience
Coordinate messaging across initiatives
Consolidate training calendar
Create shared readiness framework
Launch portfolio-level adoption dashboard
Month 5+: Operate at portfolio level
Biweekly governance meetings with real decisions about pace and sequencing
Monthly heatmap review and saturation management
Quarterly adoption analysis and course correction
Initiative leads report against portfolio metrics, not just project metrics
The evidence for this approach
Organisations implementing portfolio-level change management see material differences:
6.5x higher initiative success rates through iterative, feedback-driven course correction
Retention improvement: Organisations with low saturation see voluntary turnover 31 percentage points lower than high-saturation peer companies
These aren’t marginal gains. This is the difference between transformation that transforms and change that creates fatigue.
The research is clear: iterative approaches with continuous feedback loops and portfolio-level coordination outperform traditional programme management. Agile delivery frameworks have solved technical orchestration. Portfolio management solves human orchestration. Together, they create rapid transformation without burnout.
PI Planning coordinates technical features and dependencies. It doesn’t track people impact, readiness, or saturation across initiatives. Those require separate data collection and governance layers specific to change.
How is portfolio change management different from standard programme management?
Traditional programmes manage one large initiative. Change portfolio management coordinates impacts across multiple concurrent initiatives, making visible the aggregate burden on people and organisation.
Don’t agile teams already coordinate through standups and retrospectives?
Team-level coordination happens within an ART (agile release train). Enterprise coordination requires governance above team level, visible saturation metrics, and explicit trade-off decisions about which initiatives proceed and when. Without this, local optimisation creates global problems.
What size organisation needs portfolio change management?
Any organisation running 3+ concurrent initiatives needs some form of portfolio coordination. A 50-person firm might use a spreadsheet. A 500-person firm needs structured tools and governance.
How do we get Agile Release Train leads to participate in enterprise change governance?
Show the saturation data. When ART leads see that their initiative is stacking 4 changes onto a customer service team already managing 3 others, the case for coordination becomes obvious. Make governance meetings count—actual decisions, not information sharing.
Does portfolio management slow down agile delivery?
It resequences delivery rather than slowing it. Instead of five initiatives launching in week 5 (creating saturation), portfolio management might sequence them across weeks 3, 5, 7, 9, 11. Total delivery time is similar; adoption rates and employee experience improve dramatically.
What metrics should a portfolio dashboard show?
Change unit allocation per role (saturation heatmap)
Training completion rates across initiatives
Adoption rates post-launch
Employee change fatigue scores (pulse survey)
Initiative status and timeline
Readiness progression
How often should portfolio governance meet?
Monthly is standard. This allows timely response to emerging saturation without creating meeting overhead. Real governance means decisions get made—sequencing changes, reallocating resources, adjusting timelines.
Change saturation is the operational condition where the volume, pace and concurrency of initiatives demanded of an organisation’s workforce exceeds the capacity those teams have to absorb new ways of working. Symptoms include declining adoption rates, missed go-live milestones, rising attrition, and visible disengagement on initiatives that previously ran cleanly. It differs from change fatigue, which is the individual psychological response. Saturation is the portfolio-level structural cause. Once a business unit is saturated, even well-designed initiatives stall, because the receivers no longer have the bandwidth or psychological readiness to engage. Detection requires portfolio-level visibility, not just project-level tracking.
The statistics paint a sobering picture. Research indicates that 73% of organisations report being near, at or beyond their saturation point according to Prosci. For executives and boards tasked with driving transformation whilst maintaining operational excellence, understanding and managing change saturation has become a critical capability rather than an optional consideration.
The Reality of Change Saturation in Modern Organisations
Change saturation represents a fundamental mismatch between supply and demand. Organisations possess a finite change capacity determined by their culture, history, structure, and change management competency, yet they continuously face mounting pressure to transform faster, innovate quicker, and adapt more completely.
Why Change Saturation Is Accelerating
Several forces are driving the acceleration of change initiatives across industries. Digital transformation demands have compressed what were previously five-year horizons into immediate imperatives. Economic uncertainty and rapidly evolving industry conditions force companies to launch multiple strategic responses simultaneously rather than sequentially. Competition intensifies as organisations strive to maintain relevance, leading executives to greenlight numerous initiatives without fully considering cumulative impact.
Research by Mladenova highlights that multiple and overlapping change initiatives have become the norm rather than the exception, exerting additional pressure on organisations already struggling with increasing levels of unpredictability. The research found that the average organisation has undergone five major changes, creating an environment of continuous transformation that exceeds historical norms. Traditional linear change management models, designed for single initiatives, prove inadequate when organisations face simultaneous technological, structural, and cultural transformations.
Peak Saturation Periods: When Organisations Are Most Vulnerable
Analysis of Change Compass data reveals distinct seasonal patterns in change saturation levels. Organisations experience the most pronounced saturation during November, as teams rush to complete year-end initiatives whilst simultaneously planning for the following year’s portfolio. A secondary saturation peak emerges during the February and March period, when new strategic initiatives launch alongside ongoing projects that carried over from the previous year.
These predictable patterns create particular challenges for change practitioners and portfolio managers. November’s saturation stems from the convergence of multiple pressures, including financial year-end deadlines, budget utilisation requirements, and the desire to demonstrate progress before annual reviews. The February-March spike reflects the collision between enthusiasm for new strategic directions and the incomplete adoption of prior initiatives.
Change saturation patterns throughout the year, showing peak periods in November and February/March when change load exceeds organisational capacity
Understanding the Risks and Impacts of Change Saturation
When organisations exceed their change capacity threshold, the consequences cascade across multiple dimensions of performance. These impacts are neither abstract nor theoretical but manifest in measurable declines across operational, financial, and human capital metrics.
Productivity and Performance Impacts
The relationship between change saturation and productivity follows a predictable trajectory. Initially, as change initiatives increase, productivity may remain stable or even improve slightly. However, once saturation thresholds are crossed, productivity experiences sharp declines. Employees struggle to maintain focus across competing priorities, leading to task-switching costs that reduce overall efficiency.
Empirical research examining the phenomenon reveals that 48% of employees experiencing change fatigue report feeling more tired and stressed at work, whilst basic operational performance suffers as attention fragments across too many fronts. Research on role overload demonstrates the mechanism behind these productivity declines: a study of 250 employees found that enterprise digitalization significantly increased role overload, which in turn mediated the relationship between organizational change and employee burnout. The productivity dip manifests not just in individual output but in team coordination, decision quality, and the speed of execution across all initiatives.
Capacity Constraints and Resource Limitations
Change capacity represents a finite resource shaped by several critical factors:
Available time and attention of impacted employees
Leadership bandwidth to sponsor and support initiatives
Financial resources allocated to change activities
Technical and operational infrastructure to enable new ways of working
Organisational energy and willingness to embrace transformation
When organisations fail to account for these constraints in portfolio planning, capacity shortfalls emerge across the initiative landscape. Business functions find themselves overwhelmed with implementation demands beyond what is achievable, creating a vicious circle where incomplete adoption of one initiative reduces capacity for subsequent changes. Alarmingly, only 31% of employees report that their organisation effectively prevents them from becoming overloaded by change-related demands, indicating widespread capacity management failures.
Academic research confirms these dynamics. Studies of 313 middle managers found that organisational capacity for change mediates the influence of managerial capabilities on organisational performance, demonstrating that capacity constraints directly limit transformation outcomes regardless of individual leader quality. Research on middle managers’ role overload further reveals that workplace anxiety mediates the relationship between role overload and resistance to change, creating a reinforcing cycle that compounds capacity constraints.
Change Adoption Achievement Levels
Perhaps the most damaging consequence of saturation is the erosion of adoption quality. When organisations exceed capacity thresholds, changes simply do not stick. Employees may complete training and follow new processes initially, but without sufficient capacity to embed behaviours, they revert to previous methods once immediate oversight diminishes.
The adoption challenge intensifies when employees face simultaneous demands from multiple initiatives. From the employee perspective, the source of change matters less than the cumulative burden. Strategic transformations compete with business-as-usual improvements and regulatory compliance changes, all drawing from the same limited pool of attention and effort.
Prosci research provides compelling evidence of the adoption gap: whilst 76% of organisations that measured compliance with change met or exceeded project objectives, only 24% of those that did not measure compliance achieved their targets. This 52 percentage point difference underscores the critical link between saturation management, measurement discipline, and adoption outcomes. Studies examining change adoption demonstrate that organisations using structured portfolio approaches show significantly higher adoption rates compared to those managing initiatives in isolation, with improvements ranging from 25% to 35%.
Readiness Levels and Psychological Impact
Change saturation does not merely affect task completion but fundamentally undermines psychological readiness for transformation. When employees perceive themselves as drowning in initiatives, several concerning patterns emerge.
Change fatigue develops through constant exposure to transformation demands, manifesting as exhaustion and decreased agency. Research identifies that 54% of employees experiencing change fatigue actively look for new roles, representing a talent retention crisis that compounds capacity constraints. Among change-fatigued employees, only 43% plan to stay with their company, whereas 74% of those experiencing low fatigue intend to remain, revealing a 31 percentage point retention gap directly attributable to saturation. Employee satisfaction scores decline during sustained periods of high change load, creating resistance that undermines even well-designed initiatives.
The readiness dimension extends beyond individual psychology to encompass organisational culture and collective capacity. Organisations with limited change management competency experience saturation at lower initiative volumes compared to those with mature change capabilities. History matters as well. Teams that have experienced failed initiatives develop cynicism that reduces readiness for subsequent changes, regardless of the quality of planning.
Research on employee resistance reveals that 37% of employees resist organisational change, with the top drivers being lack of trust in leadership (41%), lack of awareness about why change is happening (39%), fear of the unknown (38%), insufficient information (28%), and changes to job roles (27%). These resistance patterns intensify under saturation conditions when communication resources are stretched thin and leadership attention is fragmented.
Comprehensive Risk Classification Framework
Change saturation creates a complex web of interconnected risks that extend across traditional risk management categories. Understanding these risk types enables organisations to develop targeted mitigation strategies and allocate appropriate governance attention.
Risk in Change
Risk in change represents threats directly attributable to the transformation initiatives themselves. These risks impact an organisation’s operations, culture, and bottom line throughout the change lifecycle. Change risk management requires a systematic framework that identifies potential obstacles early, enabling timely interventions that increase the likelihood of successful implementation.
Key change risks under saturation conditions include:
Adoption failure risk: the probability that intended changes will not be sustained beyond initial implementation
Readiness gap risk: insufficient stakeholder preparedness creating resistance and delayed adoption
Communication breakdown risk: message saturation and information overload preventing effective stakeholder engagement
Benefit realisation risk: failure to achieve anticipated returns due to incomplete implementation
Change management analytics provide data-based risk factors, including business readiness indicators and potential impact assessments, enabling risk professionals to make informed decisions about portfolio composition and sequencing.
Operational Risk
Operational risk in change saturation contexts stems from failures in internal processes, people, systems, or external events during transformation periods. The structured approach to operational risk management becomes particularly critical when organisations run multiple concurrent initiatives that strain existing control frameworks.
Saturation-amplified operational risks include:
Process integrity risk: critical processes failing or degrading as resources shift to change activities
Control effectiveness risk: required controls not operating correctly during transition periods
System stability risk: technology failures or performance degradation during implementation phases
Human error risk: mistakes increasing as employees navigate unfamiliar processes under time pressure
Data security risk: sensitive information exposed during system migrations or process changes
Operational risk management frameworks should incorporate formal change management processes to mitigate risks arising from modifications to operations, policies, procedures and controls. These frameworks must include mechanisms for preparing, approving, tracking, testing and implementing all changes to systems whilst maintaining an acceptable level of operational safety.
Research on change-oriented operational risk management in complex environments demonstrates that approximately 55% of total risk stems from human factors, followed by management, medium, and machine categories. This distribution underscores the importance of capacity-aware implementation that accounts for human limitations under saturation conditions.
Delivery Risk (Project)
Delivery risk encompasses threats to successful project execution, including timeline slippage, budget overruns, scope creep, and quality degradation. Under saturation conditions, delivery risks compound as resource contention, stakeholder fatigue, and competing priorities undermine traditional project management disciplines.
Project delivery risks intensified by saturation include:
Schedule risk: delays caused by resource availability constraints and stakeholder capacity limitations
Cost risk: budget overruns driven by extended timelines, rework, and unplanned resistance management
Scope risk: uncontrolled expansion or reduction of deliverables as stakeholders struggle to maintain focus
Quality risk: deliverable defects increasing as teams rush to meet deadlines across multiple initiatives
Resource risk: key personnel unavailable when needed due to competing project demands
Dependency risk: critical path delays when predecessor activities fail to complete due to capacity constraints
Project risk registers should identify risks that could arise during the project lifecycle through planning, design, procurement, construction, operations, maintenance and decommissioning. For each risk, teams must identify the consequences should risks eventuate, including impacts on timelines, costs and quality, as well as the likelihood of each consequence occurring.
Strategic Risk
Strategic risks emerge when saturation prevents organisations from achieving their intended strategic objectives or when transformation portfolios become misaligned with strategic priorities. These risks operate at a higher level than individual project failures, threatening competitive position and long-term viability.
Strategic risks manifesting through saturation include:
Competitive disadvantage risk: delayed capability development allowing competitors to capture market position
Strategic opportunity cost: resources locked in underperforming initiatives preventing investment in higher-value opportunities
Market timing risk: transformations completing too late to capture market windows or respond to threats
Strategic coherence risk: contradictory initiatives undermining overall strategic direction and confusing stakeholders
Research demonstrates that strategic business risks requiring different management approaches tend to be neglected compared to operational and compliance risks, despite operating in volatile, uncertain, complex and ambiguous environments where such neglect seems suboptimal. Portfolio-level risk assessment provides governance forums with visibility into where cumulative change creates strategic risk, enabling more informed decisions about sequencing, prioritisation and resource allocation.
Compliance and Regulatory Risk
Compliance risk under saturation arises when organisations struggle to maintain regulatory adherence and control effectiveness whilst implementing multiple concurrent changes. For regulated industries, this risk category carries particular severity as penalties for non-compliance can be substantial.
Saturation-driven compliance risks include:
Regulatory breach risk: failing to maintain compliance with relevant regulations during change processes
Control gap risk: required controls becoming ineffective or absent during transition periods
Audit finding risk: control weaknesses identified during periods of high change activity
Remediation timeline risk: insufficient capacity to address compliance gaps within required timeframes
Documentation risk: inadequate records of control operation and change decisions for regulatory review
In financial services specifically, operational leaders must consider regulatory risk exposure, processes remaining unaligned with regulatory requirements, remediation timelines, and forward-looking compliance risk as systems migrate and processes change. Continuous monitoring programmes that embed compliance checks at every step of delivery transform risk management from a gate to a guardrail, enabling pace whilst maintaining governance rigour.
Financial Risk
Financial risks extend beyond simple budget overruns to encompass broader economic impacts of saturation on organisational performance. These risks materialise through multiple channels, often in ways that exceed initial project cost estimates.
Financial risk categories under saturation include:
Sunk cost risk: wasted resources on failed initiatives that do not achieve adoption targets
Productivity cost risk: revenue losses from operational efficiency declines during change periods
Turnover cost risk: recruitment and training expenses driven by change-induced attrition
Benefit delay risk: postponed value realisation extending payback periods beyond planned horizons
Opportunity cost risk: capital and resources committed to underperforming changes rather than higher-return alternatives
Penalty cost risk: regulatory fines or contractual penalties from compliance failures during transformation
Reputational Risk
Reputational risk emerges when change saturation creates visible failures, stakeholder dissatisfaction, or public incidents that damage organisational standing. In an era of social media and instant communication, change-related problems can rapidly escalate into reputation crises.
Saturation-linked reputational risks include:
Customer experience risk: service disruptions or quality degradation noticed by external stakeholders
Employee reputation risk: public complaints from overworked staff or negative employer review ratings
Partner confidence risk: vendor or alliance partner concerns about organisational stability during transformation
Stakeholder trust risk: erosion of confidence among investors, regulators, or community stakeholders
Brand perception risk: market perception of organisational competence declining due to visible failures
Operational risk frameworks recognise that non-financial risks may have impacts harming the bottom line through reputation damage, making reputational risk assessment a critical component of comprehensive saturation management.
People and Culture Risk
People and culture risks represent threats to organisational capability, employee wellbeing, and cultural integrity during periods of intense transformation. These risks carry long-term consequences that extend beyond individual initiative success or failure.
Human capital risks amplified by saturation include:
Talent retention risk: loss of key personnel to competitors due to change fatigue and burnout
Capability degradation risk: skills erosion as development activities are postponed during intense change periods
Engagement risk: declining employee commitment and discretionary effort undermining performance
Health and wellbeing risk: stress-related illness and absenteeism increasing during sustained transformation
Cultural coherence risk: organisational values and norms fragmenting under contradictory change pressures
Leadership credibility risk: erosion of trust in management due to perceived mishandling of change demands
Research shows that 48% of change-fatigued employees feel more tired and stressed at work, whilst role overload significantly predicts job burnout through the mediating effect of workplace anxiety. These human impacts create reinforcing cycles that accelerate capability loss and reduce organisational resilience.
Financial and Strategic Consequences
The financial damage from poorly managed change saturation extends across six critical areas. Wasted resources and sunk project costs accumulate when initiatives fail to achieve adoption targets. Resistance-driven budget overruns occur as teams spend unplanned resources attempting to overcome saturation-induced obstacles. Operational efficiency declines as productivity dips reduce output across the business.
Revenue losses from delayed improvements compound when saturation prevents the realisation of anticipated benefits. Regulatory compliance penalties may arise if mandatory changes fail to achieve adoption within required timeframes. Supply chain relationship strain emerges when external partners experience the downstream effects of internal dysfunction.
Research quantifying these financial impacts demonstrates significant returns from effective saturation management. Studies show that organisations applying appropriate resistance management techniques increased adoption by 72% and decreased employee turnover by almost 10%, generating savings averaging USD $72,000 per company per year in training programmes alone. Conversely, 71% of employees in poorly managed change environments waste effort on the wrong activities due to leader-created change plans that are not directly relevant to their day-to-day work, representing massive productivity losses.
Perhaps most critically, organisations lose competitive position when transformation initiatives fail to deliver promised capabilities. In fast-moving markets, this strategic cost often exceeds the direct financial damage of failed projects. Research shows that successful change initiatives improve market competition by 40%, whilst companies with effective change management are 50% more likely to achieve long-term growth opportunities. The strategic opportunity cost of saturation-induced failure therefore dwarfs the immediate project-level losses.
Empirical Research on Change Saturation Levels
Academic and industry research provides robust evidence of the prevalence and impact of change saturation across different contexts and geographies. Understanding these research findings enables organisations to benchmark their own experiences and recognise early warning signs before saturation becomes critical.
Prevalence Across Industries
Prosci’s benchmarking data reveals that the percentage of organisations reaching change saturation has increased consistently over successive research cycles. This trend reflects the accelerating pace of business transformation combined with relatively static change capacity development. Research spanning multiple sectors demonstrates that saturation is not confined to specific industries but represents a universal challenge wherever organisations pursue concurrent improvement initiatives.
Analysis of transformation success rates reveals concerning patterns. The CEB Corporate Leadership Council found that whilst the average organisation has undergone five major changes, only one-third of those initiatives are successful. This 34% success rate reflects the cumulative burden of portfolio-level saturation rather than individual project deficiencies. When examined through a portfolio lens, the data suggests that many “failed” initiatives did not lack sound design or execution plans but were undermined by capacity constraints stemming from concurrent competing changes.
Impact on Change Success Probability
Research demonstrates clear correlations between saturation management practices and initiative success rates. Gartner research found that organisations applying open-source change management principles, which emphasise transparency and portfolio-level coordination, increased their probability of change success from 34% to 58%, representing a 24 percentage point improvement. This dramatic increase stems largely from better saturation management through coordinated planning and stakeholder engagement.
Prosci research provides additional granularity on the saturation-success relationship. Studies show that 76% of organisations encountering resistance managed to increase adoption by 72% when they applied appropriate resistance management techniques focused on capacity-aware implementation. This finding indicates that even when saturation creates resistance, targeted interventions can substantially improve outcomes if deployed proactively.
Measurement and Monitoring Research
Research on change measurement practices reveals significant gaps that exacerbate saturation challenges. Only 12% of organisations reported measuring change impact across their portfolio, meaning 88% lack the fundamental data needed to identify saturation before it undermines initiatives. This measurement gap prevents early intervention and forces organisations into reactive crisis management when saturation symptoms become severe.
Studies examining organisations that do implement robust measurement find substantial advantages. Research shows that organisations using continuous measurement and reassessment achieve 25% to 35% higher adoption rates than those conducting single-point readiness assessments. The improvement stems from the ability to detect emerging saturation patterns and adjust implementation pacing or resource allocation before capacity thresholds are breached.
MIT research on efficiency and adaptability challenges conventional assumptions about measurement overhead. Studies found that organisations implementing continuous change measurement with frequent assessment achieved 20-fold reductions in cycle time whilst maintaining adaptive capacity, contradicting the assumption that measurement slows transformation. This finding suggests that robust saturation monitoring actually accelerates change by preventing the costly delays associated with capacity-induced failures.
Employee Experience Research
Research examining employee perspectives provides critical insights into how saturation manifests at the individual level. Studies show that more than half of workplace leaders and staff report their organisations struggle to set well-defined measures of success for change initiatives, making progress tracking more difficult and intensifying the perception of endless transformation. This measurement ambiguity compounds saturation effects by preventing employees from recognising completion and moving forward.
Analysis of employee engagement during change reveals concerning trends. Only 37% of companies believe they are fully leveraging the employee experience during transformation efforts, meaning nearly two-thirds miss opportunities to understand and respond to saturation signals from frontline perspectives. Research demonstrates that employee engagement during change increases intent to stay by 46%, highlighting the strategic importance of saturation management for talent retention.
Studies on communication effectiveness underscore the challenge of maintaining clarity under saturation conditions. Communication leaders report that 45.6% struggle with information overload and 35.6% find it difficult to adapt to digital trends and new technologies. These challenges intensify when multiple initiatives compete for communication bandwidth, creating message saturation that parallels initiative overload.
Comparative Research on Change Approaches
Empirical research comparing different change management approaches reveals that methodology significantly influences saturation resilience. Studies examining iterative versus linear change found that 42% of iterative change projects succeeded whilst only 13% of linear ones did, representing a 29 percentage point success differential. The iterative advantage stems from continuous feedback mechanisms that enable early detection of capacity constraints and adaptive responses.
Research on change communication strategies demonstrates that companies with effective communication increase success by 38% compared to those with poor communication practices. This improvement reflects better stakeholder alignment and reduced confusion under saturation conditions when clear messaging becomes critical.
Studies examining purpose-driven change reveal that companies driven by purpose are three times more successful in fostering innovation and leading transformation compared to other organisations. These purpose-driven entities experience 30% greater innovation and 40% higher employee retention rates than industry peers, suggesting that clear strategic rationale helps buffer against saturation-induced resistance.
Measuring and Monitoring Change Saturation
Effective saturation management begins with accurate measurement. Organisations cannot manage what they do not measure, and change saturation requires portfolio-level visibility that transcends individual initiative tracking.
Establishing Baseline Capacity
The first step in saturation measurement involves determining organisational change capacity. Unlike fixed metrics, capacity varies by department, team, and even individual depending on several factors.
Capacity assessment should consider current workload, historical change absorption rates, skills and competencies of impacted groups, and leadership bandwidth to support transformation. Organisations should identify periods when multiple initiatives resulted in negative operational indicators or leader feedback about change disruption, recording these levels as exceeding the saturation point for specific departments.
A lot of change practitioners use a high level indication of High, Medium, Low in rating change impacts overall at a project level. The problem with this approach is that it is difficult for leaders to understand what this really means and how to make key decisions using such a high level indication. In this approach it is not clear exactly what role type, in what business unit, in what team, in what period of time is impacted and the types of impact. Using tools like The Change Compass, change impact can be expressed in terms of hours of impact per week, providing a quantifiable measure against which capacity thresholds can be plotted. This approach enables visualisation of saturation risk before initiatives launch rather than discovering capacity constraints during implementation.
Portfolio-Level Impact Assessment
Traditional change management often focuses on individual initiatives in isolation, missing the cumulative picture that employees actually experience. Portfolio-level assessment requires aggregating data across all concurrent changes to identify total burden on specific stakeholder groups.
Effective impact assessment frameworks should identify cumulative change impacts across projects, avoid change fatigue and capacity overload through proactive planning, and prioritise initiatives based on organisational capacity and readiness. By tracking concurrent and overlapping changes, leaders can identify where resistance may emerge and proactively address saturation before it derails initiatives.
Digital platforms make portfolio management more feasible by centralising change data, prompting initiative owners to update information regularly, and enabling instant report generation that provides portfolio visibility. These systems function as change portfolio air traffic control, helping organisations safely land multiple initiatives without collisions.
Leading and Lagging Indicators
Comprehensive saturation monitoring requires both leading indicators that predict emerging problems and lagging indicators that confirm outcomes.
Leading indicators for saturation risk include the number of concurrent initiatives per stakeholder group, total planned hours of change impact per department, stakeholder sentiment scores and engagement survey results, change readiness assessment scores, and training completion rates relative to timelines. These metrics enable early intervention before saturation creates irreversible damage.
Lagging indicators confirm the impact of saturation after it occurs. These include initiative adoption rates, productivity metrics for impacted groups, employee turnover and absenteeism, project timeline slippage, and benefit realisation against targets. Whilst lagging indicators cannot prevent saturation, they validate the accuracy of capacity models and inform adjustments for future planning.
Reporting Portfolio Health and Saturation Risks to Leadership
Translating complex change data into actionable executive insights represents a critical capability for change portfolio managers. Boards and senior leaders require clear, strategic-level information that enables rapid decision-making without overwhelming detail.
Principles for Executive Reporting
Executive change management reports must transcend departmental boundaries and speak to broader organisational impact. The focus should centre on portfolio-level insights and key strategic initiatives rather than individual project minutiae. Metrics should align with strategic goals, showcasing how change initiatives contribute to overarching business objectives.
Critically, executives require understanding of totality. What do all these changes collectively mean for the organisation? What employee experiences emerge across multiple initiatives? Reporting should also illuminate how the nature and volume of changes impact overall business performance, as executives remain focused on maintaining operational success during transformation with minimum disruption.
Avoiding certain reporting traps proves equally important. Vanity metrics that showcase activity without demonstrating impact undermine credibility. Activity-focused measurements such as training sessions conducted or newsletters distributed fail to answer whether changes are actually adopted. Overly cost-centric reporting that emphasises expenditure without linking to outcomes misses the strategic value equation.
Data Visualisation Techniques for Saturation Reporting
The choice of visualisation technique significantly impacts how effectively leaders grasp saturation dynamics. Different data types and insights require specific visual approaches.
Heat Maps excel at displaying saturation distribution across departments or time periods. By colour-coding change impact levels, heat maps instantly reveal which areas face the highest saturation risk and when peak periods occur. This visualisation enables rapid identification of imbalances where some departments are overwhelmed whilst others have spare capacity.
Portfolio Dashboard Tiles provide at-a-glance status indicators for key metrics. These data tiles can show current saturation levels relative to capacity, number of initiatives in various stages, adoption rates across the portfolio, and alerts for initiatives exceeding risk thresholds. Tile-based dashboards prevent information overload by summarising complex data into digestible insights.
Trend Line Charts effectively communicate changes in saturation levels over time. By plotting actual change load against capacity thresholds across months or quarters, these visualisations reveal patterns, predict future saturation points, and demonstrate the impact of portfolio decisions on capacity utilisation.
Bubble Charts can display multiple dimensions simultaneously, showing initiative size, impact level, timing, and risk status in a single view. This multidimensional perspective helps executives understand not just how many initiatives are running but their relative significance and saturation contribution.
Comparison Tables work well for presenting adoption metrics, readiness scores, or capacity utilisation across different business units. Tables enable precise numerical comparison whilst supporting quick scanning for outliers requiring attention.
Modern dashboards should incorporate a mixture of visualisation types to aid stakeholder understanding and avoid data saturation. Combining charts with key text descriptions and data tiles creates a balanced information environment that serves diverse executive preferences.
Content Types for Board-Level Reporting
Beyond visualisation techniques, the content structure of portfolio health reports should follow specific patterns that resonate with board priorities.
Strategic Alignment Summary demonstrates how the change portfolio connects to strategic objectives, showing which initiatives drive which goals and identifying gaps where strategic priorities lack supporting changes. This content type answers the fundamental question of whether the organisation is changing in the right directions.
Saturation Risk Assessment presents current capacity utilisation across the portfolio, highlights departments or periods approaching or exceeding thresholds, and identifies collision risks where multiple initiatives impact the same groups. This section should include clear risk ratings and recommended mitigation actions, with data illustrating fluctuations in the volume of change initiatives to help leaders understand whether the organisation is overburdened or maintaining appropriate flow.
Adoption Progress Tracking reports on how effectively changes are being embedded, comparing actual adoption rates against targets and identifying initiatives at risk of failing to achieve intended benefits. This content connects change activities to business outcomes, demonstrating return on transformation investment.
Capacity Outlook projects future saturation based on planned initiatives, enabling proactive decisions about sequencing, resource allocation, or portfolio adjustments. Forward-looking content prevents surprises by giving leaders visibility into emerging capacity constraints before they materialise, pinpointing potential capacity risks in various parts of the business so senior leaders can address looming challenges.
Decision Points highlight specific areas requiring executive intervention, whether approving additional resources, delaying lower-priority initiatives, or adjusting adoption expectations. Effective board reporting does not just inform but explicitly calls out what decisions leaders need to make.
Reporting Cadence and Governance
The frequency and forum for saturation reporting should match the pace of change in the organisation. Organisations managing high volumes of transformation typically require monthly portfolio reviews with leadership, using dashboards as the anchor for discussions on priorities, performance, and strategic fit.
Between formal reviews, dashboards should function as early-warning systems with automated alerts flagging delayed milestones, adoption shortfalls, or emerging saturation risks. Real-time dashboard updates eliminate the lag between problems emerging and leaders becoming aware, enabling faster response.
Portfolio governance bodies should include participation from programme management offices, senior business leaders, and portfolio change managers, with a focus on reporting change saturation indicators, risks identified, and critical decisions on sequencing, prioritisation, and capacity mitigation. This governance structure ensures saturation management receives ongoing executive attention rather than episodic crisis response.
Building Effective Reporting Capabilities
Developing robust portfolio reporting capabilities requires both technology and process. Digital platforms centralise change data, automate routine assessments, and allow fast recognition of leading and lagging indicators. However, technology serves as an enabler rather than a replacement for skilled analysis and strategic judgement.
Organisations should start with their current scale and goals, potentially beginning with structured spreadsheets before investing in dedicated portfolio management platforms. Integration with other business systems enables seamless reporting and reduces manual data entry burden.
Building team skills in data visualisation, stakeholder communication, and analytical interpretation proves equally critical. The most sophisticated dashboard delivers little value if change managers cannot translate data into compelling narratives that drive executive action.
Practical Strategies for Managing Change Saturation
Understanding saturation risks and reporting on portfolio health represents only the starting point. Organisations must implement practical strategies that prevent saturation from occurring and rapidly respond when capacity constraints emerge.
Portfolio Prioritisation and Sequencing
Not all initiatives deserve equal priority, yet organisations often treat them as if they do. Effective saturation management requires making hard choices about which changes proceed, which pause, and which are cancelled entirely.
Prioritisation frameworks should assess strategic value, urgency, resource requirements, and capacity impact of each initiative. Initiatives delivering high strategic value with manageable capacity consumption should proceed first, whilst lower-value, high-impact changes should be delayed until capacity becomes available.
Sequencing decisions must account for interdependencies between initiatives. Some changes create prerequisites for others, requiring thoughtful ordering rather than parallel implementation. Staggering rollouts for overloaded teams prevents collision risks and enables more focused adoption support.
Capacity Enhancement Approaches
Whilst capacity possesses inherent limits, organisations can expand these constraints through targeted interventions. Building change management competency across the organisation increases the efficiency with which teams absorb transformation.
Investing in leadership development ensures sponsors and managers provide consistent support that accelerates adoption. Providing temporary resources or relief for units under strain prevents burnout and maintains productivity during peak change periods.
Developing enterprise change management capabilities standardises approaches, establishes governance, and creates reporting mechanisms that improve efficiency across the portfolio. Organisations with mature change capabilities experience saturation at higher initiative volumes compared to those managing change in ad hoc ways.
Intervention Triggers and Adjustment
Monitoring data should drive action when warning signs emerge. Organisations need predefined trigger points that automatically prompt intervention. For instance, when adoption metrics fall 10% below targets or stakeholder sentiment scores drop into negative ranges, predetermined responses should activate.
Potential interventions include adjusting timelines to reduce pace pressure, providing additional support resources to struggling teams, modifying adoption expectations when capacity proves insufficient, and pausing lower-priority initiatives to free capacity for critical changes.
Speed of response matters critically. The lag between identifying saturation signals and implementing adjustments determines whether interventions succeed or merely slow inevitable failure. Real-time dashboards and automated alerts compress this response time, enabling proactive adjustment.
Building Sustainable Change Capability
Beyond managing immediate saturation risks, organisations must develop sustainable approaches that prevent chronic overload. This requires shifting from reactive crisis management to proactive portfolio governance and capacity planning.
Enterprise change management represents the strategic framework for sustainable transformation. Rather than treating each initiative in isolation, enterprise approaches embed change capability throughout the organisation through standardised methodologies, portfolio-level governance, continuous stakeholder engagement, and ongoing measurement and improvement.
Organisations implementing enterprise change management establish central governance boards, standardise change processes, introduce regular engagement forums, and build continuous feedback loops. These structural elements create the foundation for managing multiple concurrent changes without overwhelming the organisation.
Success requires balancing standardisation with flexibility. Whilst consistent frameworks improve efficiency, different initiatives require tailored approaches based on context, stakeholder needs, and change characteristics. The goal is not rigid uniformity but thoughtful adaptation within coherent systems.
——— —
Frequently Asked Questions
What is change saturation and how do I know if my organisation is experiencing it?
Change saturation occurs when your organisation implements more changes than employees can effectively adopt. Signs include declining productivity, increased employee turnover (particularly the 54% of change-fatigued employees who actively seek new roles), missed project deadlines, low adoption rates despite extensive training, and feedback from managers about overwhelming change demands. Research shows 73% of organisations are near, at, or beyond their saturation point.
How much change can an organisation handle at one time?
There is no universal answer, as change capacity varies by organisation based on culture, history, change management maturity, and current operational demands. The key is measuring your specific organisation’s capacity by tracking when negative impacts emerge, then setting thresholds below those levels. Research demonstrates that organisations with mature change capabilities experience saturation at higher initiative volumes than those with limited competency.
What is the difference between change saturation and change fatigue?
Change saturation describes an organisational state where initiative volume exceeds capacity. Change fatigue represents the individual psychological response to constant change, characterised by exhaustion, cynicism, and decreased willingness to engage with transformation. Saturation often causes fatigue, with research showing that change-fatigued employees are 54% more likely to consider finding new jobs and only 43% plan to stay with their company compared to 74% of those with low fatigue.
How can I measure change saturation in my organisation?
Measure saturation by assessing the number and impact of concurrent initiatives, calculating total change burden on specific stakeholder groups using hours of impact per week, tracking adoption rates and productivity metrics, monitoring employee sentiment and engagement scores, and comparing current change load against historical capacity thresholds. The Prosci Change Saturation Model provides a structured framework for this assessment.
What should I include in a change portfolio dashboard for executives?
Executive dashboards should include strategic alignment summaries, current saturation levels relative to capacity, adoption progress across key initiatives, risk alerts for programmes exceeding thresholds, capacity outlook for planned changes, and specific decision points requiring leadership action. Research shows that mixing visualisation types (heat maps, trend lines, data tiles) aids stakeholder understanding whilst avoiding data overload.
When are organisations most vulnerable to change saturation?
Based on Change Compass data, organisations experience peak saturation during November as year-end pressures converge, and during February and March when new strategic initiatives launch alongside incomplete prior-year changes. However, individual organisations may have different patterns based on their fiscal calendars and planning cycles.
Can we increase our change capacity or are we stuck with inherent limits?
Organisations can expand change capacity through several approaches, including building change management competency across the workforce, developing leadership capabilities in sponsorship and support, investing in tools and processes that improve efficiency, creating enterprise change management frameworks, and learning from previous initiatives to improve effectiveness. Research demonstrates that organisations applying appropriate resistance management techniques increased adoption by 72% and reduced turnover by almost 10%.
What is the first step in preventing change saturation?
Begin by establishing portfolio-level visibility of all current and planned initiatives. Research shows only 12% of organisations measure change impact across their portfolio, meaning 88% lack fundamental data to identify saturation risks. Without understanding the complete change landscape, you cannot identify saturation risks or make informed prioritisation decisions. Map all changes affecting each employee group to reveal overlaps and cumulative burden.
How do risk professionals classify change-related risks?
Risk professionals classify change-related risks across multiple dimensions: Risk in Change (adoption failure, readiness gaps, benefit realisation), Operational Risk (process integrity, control effectiveness, system stability), Delivery Risk (schedule, cost, scope, quality), Strategic Risk (competitive disadvantage, misalignment), Compliance Risk (regulatory breaches, control gaps), Financial Risk (sunk costs, productivity losses), Reputational Risk (stakeholder dissatisfaction), and People Risk (talent retention, burnout, cultural fragmentation). Each category requires specific mitigation strategies and governance attention to manage effectively under saturation conditions.
Measuring change saturation effectively requires moving beyond gut feel to structured, data-driven assessment. Use this practical recipe to measure change saturation using The Change Compass, including step-by-step analysis and formulating recommendations your stakeholders can act on immediately.