Every steering committee asks the same questions:
“Is the project on track?”
“Are we hitting milestones?”
“What’s the budget status?”
Here’s the question almost no one asks:
“What is this change doing to our operational performance right now?”
Not after go-live. Not in a post-implementation review. Right now, during the transition, while people are absorbing the change and running the operation simultaneously.
The silence around this question reveals a fundamental blind spot in how organisations manage transformation. Everyone assumes there will be a temporary productivity dip. They accept it as inevitable. But almost no one measures it. No one knows if it’s a 5% dip or a 25% dip. No one tracks how long recovery takes. And when you’re running multiple changes across the enterprise, those dips stack, compound, and create operational crises that leadership only discovers after significant damage has occurred.
The research on performance dips: what we know and what we ignore
The phenomenon of performance decline during organisational change is well-documented. Research consistently shows measurable productivity drops during implementation periods, yet few organisations actively track these impacts in real time.
The magnitude of performance loss
Studies examining various types of change initiatives reveal striking patterns:
ERP implementations: Performance dips range from 10% to 25% on average, with some organisations experiencing dips as high as 40%.
Enterprise system implementations: Productivity losses range from 5% to 50% depending on the organisation and system complexity.
Electronic health record (EHR) systems: Performance dips can reach 5% to 60%, particularly when high customisation is required.
Digital transformations: McKinsey research found organisations typically experience 10% to 15% productivity dips during implementation phases.
Supply chain systems: Average productivity losses sit at 12%.
Check out this article for various research on the performance dips mentioned.
These aren’t marginal impacts. A 25% productivity dip in a customer service operation processing 10,000 transactions weekly means 2,500 fewer transactions completed. A 15% dip in a manufacturing environment translates directly to output reduction, delayed shipments, and revenue impact. Yet most organisations discover these impacts only after they’ve compounded into visible crises.
Why performance dips occur
The mechanisms behind performance decline during change are well understood from cognitive and operational perspectives:
Cognitive load and task switching: Research on divided attention shows that complex tasks combined with frequent switching between demands significantly degrade performance. Employees navigating new systems whilst maintaining BAU operations experience measurable increases in error rates and reaction times.
Learning curves and proficiency gaps: Even with comprehensive training, real-world application of new processes reveals gaps between classroom scenarios and operational reality. The proficiency developed in controlled training environments doesn’t immediately transfer to production complexity.
Workaround proliferation: When new systems don’t match actual workflow requirements, employees develop workarounds. These workarounds initially appear functional but create hidden dependencies, data quality issues, and cascading problems that surface weeks later.
Support capacity constraints: As implementation teams scale back intensive go-live support, incident resolution slows. Issues that were resolved in minutes during week one take hours or days by week three, compounding operational delays.
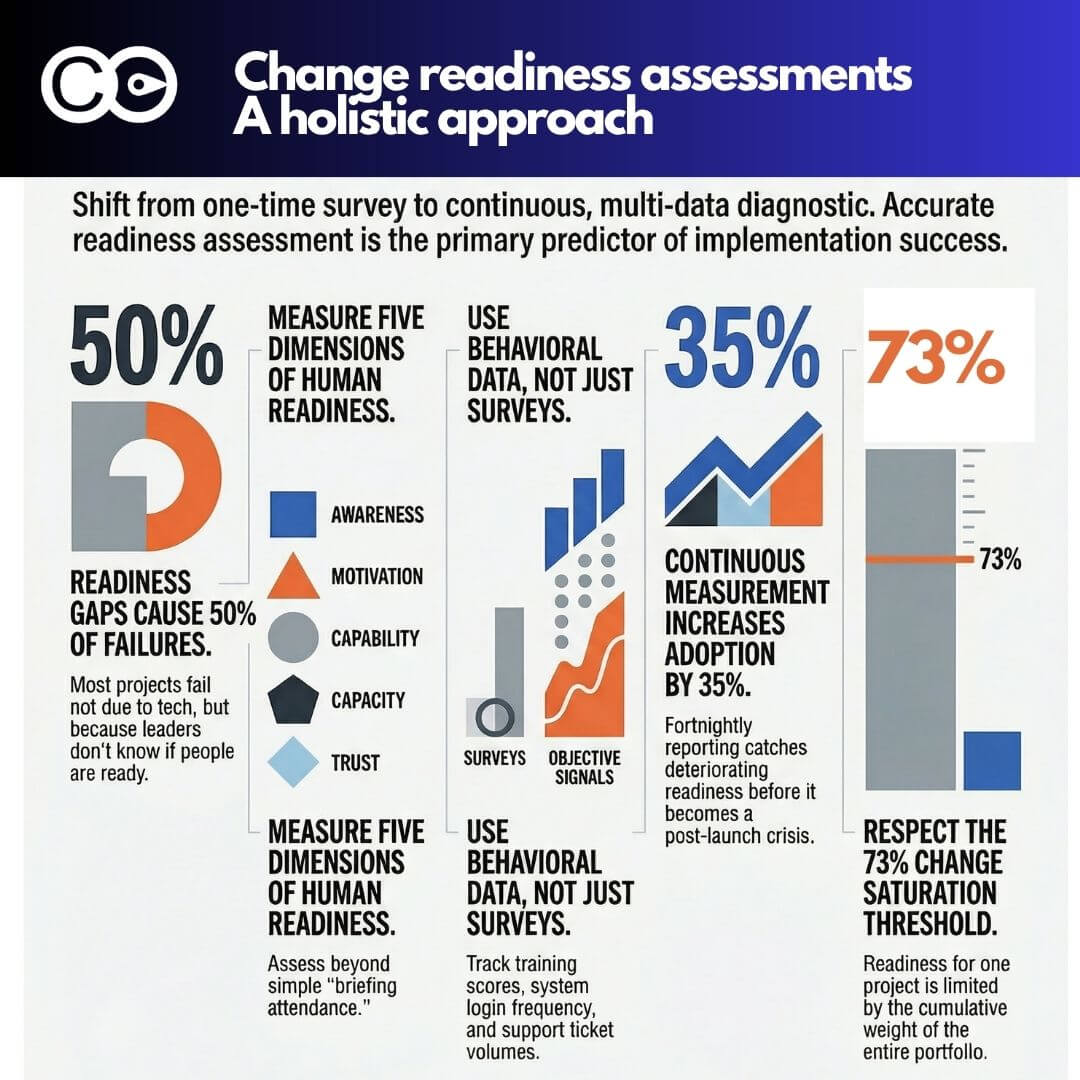
Change saturation: When multiple initiatives land concurrently, performance impacts don’t add linearly—they compound exponentially. Research shows that 48% of employees experiencing change fatigue report increased stress and tiredness, directly impacting productivity.
The recovery timeline reality
Without structured change management and continuous monitoring, organisations experience extended recovery periods. Research indicates:
- Without effective change management: Productivity at week three sits at 65-75% of pre-implementation levels, with recovery timelines extending 4-6 months.
- With effective change management: Recovery happens within 60-90 days, with continuous measurement approaches achieving 25-35% higher adoption rates than single-point assessments.
The difference isn’t marginal. It’s the difference between a brief, managed disruption and a prolonged operational crisis that undermines the business case for change.
The compounding problem: multiple changes, invisible impacts
The performance dip research cited above assumes a critical condition that rarely exists in modern enterprises: one change at a time.
Most organisations today manage portfolios of concurrent initiatives. A finance function implements a new ERP system whilst rolling out revised compliance processes and restructuring the shared services team. A healthcare system deploys new clinical documentation software whilst updating scheduling systems and migrating financial platforms. A telecommunications company launches customer portal changes whilst implementing billing system upgrades and operational support system modifications.
When concurrent changes overlap, impacts don’t simply add up, they multiply.
The mathematics of compound disruption
Consider a realistic scenario: Three initiatives land across the same operations team within 12 weeks:
- Initiative A (customer data platform): Expected 12% productivity dip
- Initiative B (revised underwriting workflow): Expected 15% productivity dip
- Initiative C (updated operational dashboard): Expected 8% productivity dip
If these were sequential, total disruption time would span perhaps 18-24 weeks with three distinct dip-and-recovery cycles. Challenging, but manageable.
When concurrent, the mathematics change. Employees don’t experience 12% + 15% + 8% = 35% productivity loss. They experience cognitive overload that drives productivity losses exceeding 40-50% because:
- Attention fragments across three learning curves simultaneously
- Support capacity spreads thin across three incident response systems
- Training saturation occurs as employees attend sessions for multiple systems without time to embed any
- Workarounds interact as temporary solutions in one system create problems in another
- Psychological capacity depletes as change fatigue sets in
Research confirms this pattern. Organisations managing multiple concurrent initiatives report 78% of employees feeling saturated by change, with change-fatigued employees showing 54% higher turnover intentions. The productivity dip becomes not a temporary disruption but a sustained operational degradation lasting months.
The visibility gap
Here’s the critical problem: Most organisations lack the data infrastructure to see this happening in real time.
Research shows only 12% of organisations measure change impact across their portfolio, meaning 88% lack fundamental data needed to identify saturation before it undermines initiatives. Without portfolio-level visibility, leaders discover compound disruption only after:
- Customer complaints spike
- Error rates become unacceptable
- Revenue targets are missed
- Employee turnover accelerates
- Projects are declared “failures” despite solid technical execution
By then, the cost of remediation far exceeds the cost of prevention.
Why organisations don’t track operational performance during change
If the research is clear and the impacts are measurable, why do so few organisations track operational performance during transitions?
Assumption that disruption is inevitable
Many leaders treat productivity dips as unavoidable costs of change, like renovation dust. “We’re implementing a major system, of course there will be disruption.” This mindset accepts performance loss as fate rather than a variable that leadership actions can influence.
Research challenges this assumption. Studies show that whilst some disruption accompanies complex change, the magnitude and duration are directly influenced by how well the transition is managed. High-performing organisations experience minimal performance penalties precisely because they track, intervene, and course-correct based on operational data.
Lack of baseline data
You can’t measure a dip if you don’t know the baseline. Many organisations lack established operational metrics or track them inconsistently. When change arrives, there’s no reliable pre-change performance level to compare against.
Without baselines, statements like “adoption is going well” or “the team is adjusting” remain subjective assessments unsupported by evidence. Leaders operate on impression rather than data.
Measurement infrastructure gaps
Even organisations with operational metrics often lack systems to correlate performance changes with change activities. They know processing times have increased or error rates have risen, but they can’t pinpoint whether the cause is the new system rollout, the concurrent process redesign, seasonal volume spikes, or unrelated factors.
This correlation gap means operational performance remains in one dashboard, project status in another, and no integration connects them. Steering committees review project milestones without visibility into business impact.
Focus on project metrics over business outcomes
Traditional project governance emphasises activity-based metrics: milestones completed, training sessions delivered, defects resolved. These metrics matter for project execution but don’t answer the question executives actually care about: Is the business performing through this change?
Research from McKinsey shows organisations tracking meaningful operational KPIs during change implementation achieve 51% success rates compared to just 13% for those that don’t, making change efforts four times more likely to succeed when measurement focuses on business outcomes rather than project activities.
Change management credibility gap
When change practitioners report on soft metrics like “stakeholder sentiment” or “readiness scores” without connecting them to hard operational outcomes, they struggle to maintain executive attention. Leaders want to know: What is this doing to our operation? If change management can’t answer with data, the discipline loses credibility.
The solution isn’t to abandon readiness and adoption metrics, those remain essential. The solution is to connect them explicitly to operational performance, demonstrating that well-managed change readiness translates into maintained or improved business outcomes.
What to measure: identifying operational metrics that matter
The first step in tracking operational performance during change is identifying which metrics genuinely reflect business health. Not every metric matters equally, and tracking too many creates noise rather than insight.
The 3-5 critical metrics principle
Focus on the 3-5 operational metrics that matter most to the business. These should be:
Directly tied to business outcomes: Metrics that executive leadership already monitors for business health, not change-specific proxies.
Sensitive to operational disruption: Metrics that would visibly shift if people struggle with new systems or processes.
Measurable at appropriate frequency: Metrics you can track weekly or daily during peak disruption periods, not quarterly lagging indicators.
Understandable to all stakeholders: Metrics that don’t require explanation. “Processing time” is clear. “Readiness index” requires interpretation.
Operational metric categories by function
Different functions have different critical metrics. Here are examples across common areas:
Customer service and support operations:
- Average handling time per transaction
- First-call resolution rate
- Customer satisfaction scores (CSAT)
- Ticket backlog age and volume
- Escalation rates to supervisors
Manufacturing and production:
- Throughput volume (units per shift/day/week)
- Cycle time from order to completion
- Defect rates and rework percentages
- Equipment utilisation rates
- On-time delivery percentages
Finance and accounting:
- Invoice processing time
- Days sales outstanding (DSO)
- Error rates in journal entries or reconciliations
- Month-end close timeline
- Payment processing accuracy
Sales and revenue operations:
- Quote-to-order conversion time
- Sales cycle length
- Forecast accuracy
- Pipeline velocity
- Customer onboarding time
Healthcare clinical operations:
- Patient wait times
- Documentation completion rates
- Medication error rates
- Bed turnover time
- Chart completion timeliness
Technology and IT operations:
- System availability and uptime
- Mean time to resolution (MTTR) for incidents
- Change success rate
- Deployment frequency
- Service desk ticket volume
The specific metrics vary by industry and function, but the principle holds: choose metrics that executives already care about, that reflect operational health, and that would visibly shift if change is disrupting performance.
Leading vs lagging operational indicators
Operational performance measurement should include both leading indicators (predictive) and lagging indicators (confirmatory):
Leading indicators provide early warning of emerging problems:
- Training completion rates relative to go-live timing
- Support ticket volumes and trends
- System login frequency and feature usage
- Employee sentiment scores
- Workaround documentation requests
Lagging indicators confirm actual outcomes:
- Throughput volumes and processing times
- Error rates and rework
- Customer satisfaction scores
- Revenue and cost performance
- Quality metrics
Both matter. Leading indicators enable intervention before performance degrades visibly. Lagging indicators validate whether interventions worked.
How to establish baselines before change lands
Baselines are the foundation of meaningful performance measurement. Without knowing where you started, you can’t quantify impact or demonstrate recovery.
Baseline establishment process
Step 1: Identify the 3-5 critical operational metrics for the impacted function or team, using the principles outlined above.
Step 2: Determine baseline measurement period. Ideally, capture 8-12 weeks of pre-change data to account for normal operational variation. This reveals typical performance ranges rather than single-point snapshots.
Step 3: Document baseline performance. Calculate average performance, typical variation ranges, and any seasonal patterns. For example: “Average processing time: 4.2 minutes per transaction, typical range 3.8-4.6 minutes, with slight increases during month-end periods.”
Step 4: Establish thresholds for concern. Define what magnitude of change warrants intervention. A 5% dip might be acceptable and temporary. A 20% dip signals serious disruption requiring immediate action.
Step 5: Communicate baselines to governance. Ensure steering committees and leadership understand baseline performance and what “normal” looks like before change begins.
Baseline data sources
Where does baseline data come from? Most organisations already collect operational metrics—they just don’t use them for change impact assessment:
- Operational dashboards and business intelligence systems: Most functions track performance metrics for ongoing management. Leverage existing data rather than creating parallel measurement systems.
- Time and motion studies: For processes lacking automated measurement, conduct time studies during the baseline period to understand current performance.
- Quality assurance and audit data: Error rates, defect rates, and compliance metrics often exist in quality systems.
- Customer feedback systems: CSAT scores, Net Promoter Scores (NPS), and complaint volumes provide external validation of operational performance.
- Financial systems: Cost per transaction, revenue per employee, and similar financial metrics reflect operational efficiency.
The goal isn’t to create new measurement infrastructure (though sometimes that’s necessary). The goal is to systematically capture and document performance levels before change disrupts them.
When baselines don’t exist
What if you don’t have historical operational data? You’re implementing change into a new function, or metrics were never established?
Option 1: Rapid baseline establishment. Implement measurement 4-6 weeks before go-live. Not ideal, but better than no baseline.
Option 2: Industry benchmarks. Use external benchmarks to establish expected performance ranges. “Industry average for similar operations is X; we’ll track whether we maintain that level through change”.
Option 3: Relative baselines. If absolute metrics aren’t available, track relative changes: “Week 1 post-change will be our baseline; we’ll track whether performance improves or degrades from that point”.
Option 4: Proxy metrics. If direct operational metrics don’t exist, identify proxies that correlate with performance: employee hours worked, system transaction volumes, customer contact rates.
None of these are as robust as established baselines, but all provide more insight than flying blind.
Tracking operational performance during the transition
Once baselines exist and change begins, systematic tracking transforms assumptions into evidence.
Measurement cadence during change
Pre-change (weeks -8 to 0): Establish and validate baselines. Ensure data collection processes are reliable.
Go-live week (week 1): Daily measurement. Performance during go-live is artificial due to hypervigilant support, but daily tracking captures immediate issues.
Peak disruption period (weeks 2-4): Daily or at minimum three times per week. This is when performance dips typically peak and when early intervention matters most.
Stabilisation period (weeks 5-12): Weekly measurement. Performance should trend toward baseline recovery. Persistent gaps signal unresolved issues.
Post-stabilisation (months 4-6): Biweekly or monthly measurement. Confirm sustained recovery and benefit realisation.
The frequency isn’t arbitrary. Research shows week two is when peak disruption hits as artificial go-live conditions end and real operational complexity surfaces. Daily measurement during this window enables rapid response.
Creating integrated performance dashboards
Operational performance data should integrate with change rollout timelines in unified dashboards visible to all governance forums.
Dashboard design principles:
Integrate operational and change metrics on one view. Left side shows project milestones and change activities. Right side shows operational performance trends. The correlation becomes immediately visible.
Use visual indicators for thresholds. Green (within acceptable variance), amber (approaching concern threshold), red (intervention required). Leaders grasp status at a glance.
Overlay change activities on performance trend lines. When a performance dip occurs, the dashboard shows which change activity coincided. “Error rates spiked on Day 8, coinciding with the process redesign go-live”.
Enable drill-down to detail. High-level executive dashboards show summary trends. Operational leaders can drill into specific teams, shifts, or transaction types.
Update in real-time or near-real-time. During peak disruption periods, yesterday’s data is stale. Automated feeds from operational systems provide current visibility.
Interpretation and intervention triggers
Data without interpretation is noise. Establish clear triggers for intervention:
Threshold 1: Acceptable variance (0-10% from baseline). Continue monitoring. Some variation is normal. No intervention required unless sustained beyond expected recovery window.
Threshold 2: Concern zone (10-20% from baseline). Investigate causes. Increase support intensity. Prepare contingency actions if deterioration continues.
Threshold 3: Critical disruption (>20% from baseline). Immediate intervention required. Options include: pausing additional changes, deploying emergency support resources, simplifying rollout scope, or reverting to previous state if business impact is severe.
These thresholds aren’t universal—they depend on operational criticality and baseline variability. A 15% dip in non-critical administrative processing might be tolerable. A 15% dip in patient safety metrics or financial controls is not.
Bringing operational data into steering committees
Measurement matters only if it drives decisions. That means bringing operational performance data into governance forums where change priorities and resources are allocated.
Shifting the steering committee conversation
Traditional steering committee agendas focus on project status:
These remain important, but they’re insufficient. The agenda must expand to include:
Operational performance trends: “Processing times increased 18% in week two, exceeding our concern threshold. Here’s what we’re seeing and what we’re doing about it.”
Business impact quantification: “The performance dip has reduced throughput by 2,200 transactions this week, representing approximately $X in delayed revenue.”
Correlation analysis: “The spike in errors correlates with the data migration issues we identified in last week’s incident log. Resolution is in progress.”
Recovery trajectory: “Performance recovered from 72% of baseline in week three to 85% in week four. We expect full recovery by week six based on current trend.”
Intervention decisions: “Given concurrent Initiative B launching next week whilst Initiative A is still stabilising, we recommend deferring Initiative B by three weeks to avoid compound disruption.”
This isn’t just reporting. It’s decision-making based on evidence.
Earning credibility through operational language
When change practitioners speak in operational terms … throughput, error rates, processing times, customer satisfaction, they speak the language of business leaders.
“Stakeholder readiness scores improved from 6.2 to 7.1” has less impact than “Processing times returned to baseline levels, confirming the team has embedded the new workflow.” Both metrics have value, but operational outcomes resonate more powerfully with executives focused on business performance.
Research confirms this principle. Change management earns its seat at leadership tables by demonstrating measurable impact on business outcomes, not just change activities.
Portfolio-level operational visibility
When organisations manage multiple concurrent changes, steering committees need portfolio-level operational visibility:
Heatmaps showing which teams are under highest operational pressure from concurrent changes. “Customer service is absorbing changes from Initiatives A, B, and C simultaneously. Operations is managing only Initiative B.”
Aggregate performance impact across all initiatives. “Total enterprise productivity is at 82% of baseline due to overlapping disruptions. Sequencing Initiative D would drop this to 74%, exceeding our risk tolerance.”
Recovery timelines across the portfolio. “Initiative A has stabilised. Initiative B is in week-three disruption. Initiative C hasn’t launched yet. This sequencing allows focused support where it’s needed most.”
This portfolio view enables trade-off decisions impossible at individual project level: defer lower-priority changes, reallocate support resources to highest-disruption areas, establish blackout periods for overloaded teams.
Real-world application: case example
Consider a mid-sized financial services firm implementing three concurrent technology changes affecting the same operations team:
Initiative A: Customer data platform migration
Initiative B: Revised loan underwriting workflow
Initiative C: Updated compliance reporting dashboard
Baseline operational metrics established:
- Loan processing time: 3.2 hours average
- Error rate requiring rework: 4.2%
- Daily loan volume: 180 applications processed
- Customer satisfaction (CSAT): 4.3/5.0
Week 1 (Initiative A go-live): Daily tracking showed processing time increased to 3.8 hours (+19%), error rate jumped to 7.1% (+69%), volume dropped to 165 applications (-8%). CSAT held at 4.2.
Response: Increased on-site support from two FTEs to five. Extended helpdesk hours. Daily huddles to address emerging issues.
Week 3: Processing time recovered to 3.4 hours (+6% from baseline). Error rate improved to 5.1% (+21% from baseline but improving). Volume reached 174 applications (-3%). CSAT recovered to 4.3.
Decision point: Initiative B was scheduled to launch Week 4. Dashboard data showed Initiative A was stabilising but not yet fully recovered. Leadership faced a choice:
Option 1: Proceed with Initiative B as scheduled. Risk compound disruption whilst Initiative A is still embedded.
Option 2: Defer Initiative B launch by three weeks, allowing full Initiative A stabilisation before introducing new disruption.
Decision: Defer Initiative B. The operational data made visible the risk of compound impact. Three-week deferral extended overall timeline but protected operational performance and adoption quality.
Outcome: By Week 6, Initiative A metrics returned to baseline. Initiative B launched Week 7 into a stabilised operation. The team absorbed Initiative B with minimal disruption (processing time peaked at +8% vs the +19% for Initiative A, because the team wasn’t simultaneously managing two changes). Initiative C launched Week 12 after Initiative B stabilised.
Total programme timeline: Extended by three weeks. Total operational disruption: Reduced by an estimated 40% because changes were sequenced to respect team capacity rather than pushed concurrently for timeline optimisation.
This is what operational performance tracking enables: evidence-based decisions that optimise for business outcomes rather than project schedules.
Building the measurement infrastructure
For organisations without existing infrastructure to track operational performance during change, building capability requires systematic steps:
Month 1: Inventory and assess
- Identify all operational metrics currently tracked across functions
- Assess data quality, frequency, and accessibility
- Identify gaps where critical functions lack performance metrics
- Catalogue data sources and integration points
Month 2: Establish standards
- Define the 3-5 critical metrics for each major function
- Standardise calculation methods and reporting formats
- Establish baseline measurement protocols
- Create integration between operational systems and change dashboards
Month 3: Pilot measurement
- Select one upcoming change initiative for pilot
- Implement full baseline-to-recovery tracking
- Test dashboard integration and governance reporting
- Refine based on pilot learnings
Month 4-6: Scale enterprise-wide
- Roll out standardised operational performance tracking across all major initiatives
- Train project managers and change leads on measurement protocols
- Integrate operational performance into steering committee agendas
- Establish portfolio-level tracking for concurrent changes
Month 7+: Continuous improvement
- Refine metrics based on what proves most predictive
- Automate data collection and reporting where possible
- Expand portfolio visibility and decision-making capability
- Build predictive models based on historical change-performance correlation
Tools like The Change Compass provide ready-built infrastructure for this type measurement, enabling organisations to skip months of development and begin tracking immediately.
The strategic value of operational performance tracking
When organisations systematically track operational performance during change, the benefits extend beyond individual project success:
Evidence-based portfolio prioritisation: Data showing which teams are under highest operational pressure enables rational sequencing decisions rather than political negotiations.
Predictive capacity planning: Historical patterns of disruption by change type enable future planning: “ERP implementations typically create 12-15% productivity dips for 8-10 weeks. We need to plan support resources and defer lower-priority work accordingly.”
ROI validation: Connecting change investments to sustained operational improvements demonstrates value. “Initiative A cost $2M and delivered sustained 8% processing time improvement, representing $4M annual benefit.”
Change management credibility: Speaking the language of operational outcomes positions change management as strategic business capability, not administrative overhead.
Risk mitigation: Early detection of performance degradation enables intervention before crises emerge, protecting customer experience and revenue.
Research confirms these benefits are measurable. Organisations using continuous operational performance measurement during change achieve 25-35% higher adoption rates and 6.5x higher initiative success rates than those relying on project activity metrics alone.
Frequently Asked Questions
Why is it important to track operational performance during change implementation?
Tracking operational performance during change reveals the real business impact of transformation in real-time, enabling early intervention before productivity dips become crises. Research shows organisations measuring operational performance during change achieve 51% success rates compared to 13% for those focused only on project metrics.
What operational metrics should I track during organisational change?
Focus on 3-5 metrics that matter most to your business: processing times, error rates, throughput volumes, customer satisfaction scores, and cycle times. These should be metrics executives already monitor for business health, sensitive to disruption, and measurable at high frequency.
How large are typical productivity dips during change implementation?
Research shows productivity dips range from 5-60% depending on change complexity and management approach. ERP implementations average 10-25% dips, digital transformations see 10-15% drops, and EHR systems can experience 5-60% depending on customisation. With effective change management, recovery occurs within 60-90 days.
How do you establish baseline metrics before a change initiative?
Capture 8-12 weeks of pre-change performance data for your critical operational metrics. Document average performance, typical variation ranges, and seasonal patterns. Establish thresholds defining acceptable variance vs concern levels. Communicate baselines to governance before change begins.
What happens when multiple changes impact operations simultaneously?
Concurrent changes create compound disruption where productivity losses multiply rather than add. When three initiatives each causing 10-15% dips overlap, total impact often exceeds 40-50% due to cognitive overload, fragmented attention, and support capacity constraints. Portfolio-level tracking becomes essential.
How often should operational performance be measured during change?
Measure daily during go-live week and peak disruption period (weeks 2-4), when performance dips typically peak. Shift to weekly measurement during stabilisation (weeks 5-12), then biweekly or monthly post-stabilisation. High-frequency measurement during critical windows enables rapid intervention.
What is the connection between change management and operational performance?
Effective change management directly influences operational performance during transition. Organisations with structured change management recover from productivity dips within 60-90 days and achieve 25-35% higher adoption rates. Without change management, recovery extends to 4-6 months with productivity remaining 65-75% of baseline.