Most change managers have tried using AI for something in the past twelve months. Drafting a stakeholder communication. Generating a change impact summary. Running a change plan through ChatGPT. And most have found that the output was adequate, occasionally impressive, but rarely transformative.
That experience has left the profession in an ambiguous position: aware that AI matters, unclear on what it should actually do, and uncertain whether the tools available today are fit for serious change work or are just productivity shortcuts dressed up as something more important.
This guide cuts through that ambiguity. It explains what AI in change management actually means, where it genuinely adds value, where it does not, and what it takes to move from ad hoc AI experimentation to a structured capability that improves outcomes. It maps the full landscape of AI applications in the field, from basic generative tools through to purpose-built change intelligence platforms, so you can make an informed decision about where to invest and in what sequence.
The two ways AI shows up in change management
Before evaluating any AI application, it helps to be precise about what we are talking about. AI appears in change management in two structurally different forms, and conflating them is the source of most of the confusion and disappointment organisations experience.
Generative AI for task acceleration
The first form is generative AI: large language model tools like ChatGPT, Microsoft Copilot, and Google Gemini applied to the drafting and synthesis tasks change managers do every day. This includes generating first drafts of stakeholder communications, producing change impact summaries from meeting notes, synthesising training content, drafting executive briefings, and producing change plans from a brief.
These tools are capable at this work when the inputs are specific, the task is well-defined, and someone experienced reviews and edits the output. They reduce the blank-page friction that slows down delivery teams and can meaningfully accelerate the documentation-heavy early stages of a change programme.
They are not, by themselves, a change management capability. Output quality depends entirely on the quality of the inputs, and those inputs are only as good as the person providing them.
Purpose-built AI embedded in change platforms
The second form is purpose-built AI: algorithms and analytical models embedded in change management platforms designed specifically for the data and decision types that change managers face at portfolio level. This includes saturation forecasting (predicting when aggregate change load will breach absorption capacity), adoption likelihood scoring (identifying which stakeholder groups are at risk of non-adoption), fatigue indexing (tracking cumulative exposure per group across all concurrent initiatives), and narrative generation grounded in your organisation’s actual change data.
This form of AI is structurally different from a general-purpose language model. It is grounded in your organisation’s change data, which is what makes it capable of producing recommendations that are specific rather than generic.
Understanding this distinction is the starting point for making sound decisions about AI adoption in change management. For a detailed analysis of where each type delivers and where it falls short, our article on what AI can and can’t do in change management works through the specifics across each use case.
What AI genuinely delivers for change managers
Setting aside the hype, there are three categories where AI creates real and measurable value for change practitioners today.
Drafting speed and cognitive offload
The most straightforward and proven benefit is acceleration of drafting work. Research from Asana’s State of AI at Work 2025 found that knowledge worker AI usage doubled from 36% to 70% between 2023 and 2025, with workers delegating approximately 27% of their workload to AI-assisted tools. For change managers, the highest-value delegation targets are the time-consuming mid-complexity tasks: stakeholder communication first drafts, change plan outlines, training needs summaries, and status report synthesis.
The key word is “drafting.” These outputs require domain review and context-specific editing before they are usable. But the productivity gain from a 70% complete, structurally sound first draft is real, especially on high-volume programmes with multiple concurrent workstreams and limited resourcing.
The discipline required is not adopting AI. It is building a review process that catches what AI gets wrong, which is always something.
Cross-initiative pattern recognition at portfolio scale
The second benefit is harder to achieve with generic tools but significant where it is available: the ability to detect patterns across multiple initiatives simultaneously. No human change manager can hold the full picture of a 30-initiative portfolio in their head, cross-referenced by impacted stakeholder group, timing, and impact type. Purpose-built AI can.
This matters because the failure modes in large portfolios are systemic, not project-level. A scheduling conflict between two initiatives landing on the same business unit in the same fortnight is invisible from inside either initiative. Behavioural contradictions, where two changes ask the same group to adopt incompatible working patterns, are nearly impossible to spot without aggregated data.
AI-powered conflict detection, as described in detail in our article on change conflict detection, surfaces these patterns before they reach the delivery phase, when they are still sequenceable rather than crisis-manageable.
Adoption forecasting and early warning
The third capability is predictive: using historical engagement, survey, and impact data to generate early-warning signals on adoption risk. Adoption forecasts at the initiative level are useful for sequencing decisions and sponsor attention. At the portfolio level, they become a governance instrument, identifying which clusters of change activity are likely to generate systemic resistance before the rollout is committed.
Prosci’s 12th Edition Best Practices in Change Management, drawing on data from over 10,800 change practitioners, identifies early-warning capability as one of the most significant differentiators between high-performing and low-performing change functions. Organisations that can identify adoption risk before deployment are 6 to 7 times more likely to achieve their intended change outcomes than those responding reactively.
Where AI misleads change managers (and why)
The same capabilities that make AI appealing also make it dangerous when used without the right foundations.
The 80/20 problem
Generic AI tools trained on change management best practice produce output that is typically 80% sound and 20% wrong for the specific organisation. The problem is that the wrong 20% does not announce itself. The credible 80% creates a halo effect that carries the whole output through governance.
Common manifestations include: change plans that assume sponsorship structures the organisation does not have, sequencing that does not account for the organisation’s change history, training approaches that do not match the workforce’s capability profile, and communication channels that bypass the organisation’s actual influence networks. None of these failures are obvious to anyone without deep contextual knowledge, which is precisely the knowledge that generic AI lacks.
This is distinct from hallucination, which is visible and correctable. The 80/20 failure mode is invisible at the point of output and becomes apparent only when the change reaches the impacted population. By then, the cost of correction is significantly higher than it would have been at the planning stage.
The project data trap
A related problem is the confusion between project data and change data. Most organisations have extensive project data: scope documents, risk registers, milestone trackers, budget reports. Almost none of this data describes what the change looks like from the perspective of the impacted employee.
AI grounded only in project data produces recommendations about projects. It cannot describe how 47 employees in the Melbourne operations team will experience a systems migration stacked on top of a restructure and a performance review cycle change, because that information does not exist in any project management tool.
The structural distinction between project data and change data is the most important issue to resolve before investing in any AI tool for change management. It determines whether your AI investment will produce portfolio-level intelligence or just faster versions of the same project-level documents you already had.
The two-tier model: Project-level and portfolio-level AI
The clearest framework for understanding where AI adds value in change management is the two-tier model.
Project-level AI operates within a single initiative. It accelerates task execution: generating change plans, impact assessments, stakeholder matrices, communications, and status reports from project-specific inputs. The Change Compass’s Change Automator is a purpose-built example of this, using your organisation’s structured change data as context to produce artefacts that are organisation-specific rather than generic.
Portfolio-level AI operates across all active initiatives simultaneously. It aggregates stakeholder impact, calculates saturation scores, detects scheduling and behavioural conflicts, forecasts adoption likelihood by stakeholder group, and generates executive narratives grounded in real portfolio data. This is the layer that generic AI cannot reach, because it requires a cross-initiative data architecture that no project management tool or general language model maintains.
The two tiers are complementary, not competitive. Project-level AI reduces the time change managers spend on documentation. Portfolio-level AI improves the quality of strategic decisions made by transformation leaders and executives. Together, they constitute a change management AI automation model that shifts the operating rhythm of a mature change function from reactive and document-heavy to predictive and intelligence-driven.
The most common mistake in AI adoption for change management is using only the project-level tier. This is understandable because project-level tools are more immediately tangible, but it misses the most significant value: the strategic intelligence that only a cross-portfolio view can generate.
The case for purpose-built platforms over generic AI
The logical implication of the two-tier model is that AI in change management becomes most valuable when it is grounded in structured, organisation-specific change data. This is not achievable through prompt engineering alone. It requires a data architecture designed specifically for change.
A Change Intelligence Platform is purpose-built for this requirement. It creates and maintains the system of record for change data across all initiatives, with a consistent taxonomy, structured impact fields, and aggregation capabilities that make portfolio-level AI feasible. The AI in a change intelligence platform is not a general-purpose language model with a change management persona. It is grounded in your organisation’s actual change data.
Why the data question is decisive
A 2025 IBM CEO Study, drawing on responses from 2,000 CEOs globally, found that only 25% of AI initiatives had delivered their expected ROI, and just 16% had successfully scaled. The most commonly cited obstacle was data readiness: 72% of CEOs identified proprietary data as the key to GenAI value, and 68% named integrated enterprise-wide data architecture as critical to success.
In change management terms, the bottleneck is identical. Generic AI cannot deliver portfolio-level value because the data it needs, organised change impact data aggregated across initiatives with a consistent taxonomy, does not exist in a general-purpose tool. Building that data layer is the prerequisite for the AI to do anything strategically useful.
What this means for AI adoption
The progression from “we are experimenting with ChatGPT” to “AI is improving our change outcomes” is not primarily a technology question. It is a data architecture question. Organisations that skip the data foundation step and invest directly in AI tooling find that the tools produce output that is faster but not better. The quality ceiling is set by the data, not the algorithm.
This is why early AI experimentation in change management so often disappoints: practitioners are running sophisticated tools on inadequate data, and no amount of prompt refinement resolves a structural data gap.
How to evaluate AI tools for change management
Given the two-tier model and the data architecture requirements, evaluating AI tools for change management requires a different lens than most technology evaluations. The relevant questions are not about the AI’s features in isolation but about whether the AI can access the data it needs to produce useful output.
The key evaluation criteria are:
Data grounding: Does the AI use your organisation’s actual change data as context, or does it produce generic output from training data alone?
Portfolio scope: Does the tool operate across all initiatives simultaneously, or only within individual projects?
Taxonomy consistency: Does the platform enforce a consistent classification of impact types, stakeholder groups, and change phases across all initiatives? Without this, aggregation is unreliable.
Output specificity: Can the AI produce recommendations that reference specific stakeholder groups, business units, and initiatives from your portfolio, or does it produce change management advice that could apply to any organisation anywhere?
Integration: Does the platform connect to your HRIS, project management tools, and survey platforms to enrich the change data layer with real organisational signals?
Our detailed enterprise change management software buyer’s guide covers these criteria in depth, including the compliance, security, and integration requirements that enterprise procurement and IT teams will need to address.
The most important red flag when evaluating AI tools for change management is confident specificity without data grounding. If a tool produces highly specific recommendations about your organisation’s change programme without access to your organisation’s data, it is either applying generic best practice with a superficial wrapper of specificity or generating plausible-sounding output that has not been validated against your actual context. Both produce the 80/20 problem at scale.
How Change Compass implements AI in change management
Change Compass implements the two-tier model through two connected capabilities.
At the project level, the Change Automator generates change management artefacts from your organisation’s structured change data. Change plans, stakeholder matrices, communications plans, training needs analyses, and status reports are produced using the organisation’s taxonomy, change history, and stakeholder data as context. The output is organisation-specific, which means the editing required before it is usable is significantly less than for generic AI output.
At the portfolio level, Change Compass aggregates impact data across all active initiatives to generate saturation heatmaps, per-group fatigue indices, adoption likelihood scores, and portfolio-wide conflict alerts. The AI layer operates on top of this structured data, enabling capabilities that are not achievable with a standalone language model: forecasting saturation risk before a new initiative is launched, detecting when two initiatives are creating behavioural contradictions for the same stakeholder group, and generating executive narrative that is grounded in real portfolio data.
The data flywheel between the two tiers compounds over time. Every project-level artefact a change manager creates in the platform enriches the portfolio-level data that the AI uses to generate insights and forecasts. The more consistently teams use the platform, the more specific and accurate the portfolio intelligence becomes.
Where to start: a practical adoption roadmap
For change teams at the beginning of their AI journey, a sequenced approach is significantly more reliable than attempting to adopt both tiers simultaneously or investing in tooling before the data foundation exists.
Standardise your change data model. Before AI can add portfolio-level value, you need consistent data across initiatives. Agree on a taxonomy for impact types, a classification system for stakeholder groups, and a common format for impact severity and timing. This can begin in a spreadsheet, but the goal is to move toward a platform that enforces consistency at data entry rather than relying on manual conventions.
Adopt project-level AI for acceleration. Introduce generative AI at the project level for task acceleration: communications drafting, change plan generation, and status synthesis. Establish a clear editing discipline, recognising that AI output requires domain review before it is usable. Track the time saved per task to build the internal case for further investment.
Aggregate into a portfolio view. Once you have consistent data across initiatives, aggregate it into a portfolio view. Even a static quarterly view of impacted stakeholder groups by initiative and timing provides significant value for sequencing decisions. This is the foundation on which portfolio-level AI can later operate.
Deploy portfolio-level AI for strategic decisions. With consistent data and a portfolio view established, purpose-built portfolio AI becomes feasible. Start with saturation forecasting and conflict detection, as these produce the clearest and most immediately actionable signals for senior leaders.
This progression takes most change functions 12 to 24 months to complete, depending on the starting maturity of their data practices. The investment is front-loaded in steps 1 and 3, but the strategic value compounds significantly in step 4 and beyond.
Making AI work in practice
AI in change management is not primarily a technology adoption challenge. The change managers and functions that get the most from AI are those that have already invested in the data practices that give AI something useful to work with: structured impact data, consistent stakeholder taxonomy, and cross-initiative visibility maintained in a single system of record.
The organisations that will be genuinely differentiated by AI over the next three years are not those that adopted the most tools earliest. They are those that built the data foundation that makes AI output specific, accurate, and grounded in real organisational context.
That foundation is worth building whether or not AI is the primary motivation. The visibility and strategic intelligence it creates are valuable in their own right. AI acceleration is an additional return on the same investment, and a significant one as the tools mature.
Frequently asked questions
What is AI in change management? AI in change management refers to the application of artificial intelligence, including generative AI tools and purpose-built analytics platforms, to improve the speed, quality, and strategic value of change management work. It encompasses task-level applications such as drafting communications and generating change plans, and portfolio-level applications including saturation forecasting, adoption risk scoring, and conflict detection across concurrent initiatives.
Can AI replace a change manager? No. AI tools accelerate documentation and surface portfolio-level patterns, but they cannot substitute for the stakeholder relationships, political navigation, and adaptive judgement that define effective change management. Research from Workday found that while 75% of workers are comfortable working alongside AI agents, only 30% are comfortable being managed by one. The human role in change management shifts from document production to sense-making, relationship management, and strategic counsel, which AI cannot replace.
What data does AI need to be useful in change management? AI in change management needs structured, organisation-specific change data: standardised impact classifications, stakeholder group definitions, change history, and timing data across all concurrent initiatives. Without this data, AI tools produce generic output that may be technically sound but contextually wrong for the specific organisation, producing the 80/20 problem described above.
What is the difference between a change management AI tool and a Change Intelligence Platform? A change management AI tool typically applies generative AI to individual change tasks within a single project. A Change Intelligence Platform is a purpose-built system that maintains a cross-initiative data architecture, enabling portfolio-level AI applications including saturation forecasting, conflict detection, and adoption risk scoring. The platform provides the data layer that makes AI recommendations organisation-specific rather than generic.
How long does it take to see real value from AI in change management? Project-level benefits such as drafting acceleration and time savings on documentation are typically visible within weeks of adoption. Portfolio-level benefits require consistent data collection across initiatives, which takes most organisations 12 to 24 months to establish. The strategic payoff, including predictive adoption forecasting and portfolio conflict detection, compounds significantly after the data foundation is in place.
There is an uncomfortable irony at the heart of most change management practices. Change managers are trained to help organisations plan for the human side of transition, measure adoption, track readiness, and manage stakeholder resistance. They can tell you precisely which business units are most exposed to a given change, which employee groups are furthest from readiness, and which initiatives are competing for the same people’s attention at the same time.
What most of them cannot tell you is what their function is worth in dollars.
Change management ROI (the measurable financial return that structured change management delivers relative to its cost) is the business case gap that change leaders have struggled to close for decades. Not because the value is not there, but because the data is rarely collected in a way that makes it legible to finance or the executive team. The business case gets written once, at the start of a programme, and then quietly shelved while the real work begins. By the time a senior leader asks “what did we actually get from the change team?”, the answer has to be reconstructed from memory, output logs, and adoption survey scores that nobody can connect to a dollar figure.
This article makes the case that the problem is not a lack of value. It is a lack of measurement infrastructure. And it provides a practical framework for closing that gap, one that practitioners can apply to their current programmes without waiting for a new mandate or a new budget.
Why change management is one of the few business functions that struggles to quantify its own value
Finance teams measure return on every capital investment. Marketing tracks cost per acquisition and customer lifetime value. IT reports on system uptime, incident rates, and cost per transaction. HR has moved decisively toward workforce analytics in the last decade, with turnover costs, time-to-productivity, and engagement scores now standard inputs into boardroom conversations.
Change management, by contrast, has relied primarily on activity metrics: training completion rates, communications sent, stakeholder engagement sessions held, survey scores at go-live. These are outputs, not outcomes. They measure what the change team did, not what the organisation gained as a result.
The business case problem
The typical change management business case is written before the work begins. It makes the case for investment by projecting the cost of failure: failed adoption, delayed benefit realisation, productivity loss during transition, attrition. These projections are often compelling. They are also speculative, because they are written in advance of the data.
The problem is structural. Most change managers do not control the financial data that would allow them to validate those projections later. Benefit realisation sits with the project sponsor. Productivity data sits with HR or operations. Adoption rates get reported to the project board but rarely get connected back to the financial case. By the time the programme closes, the change team has produced a substantial body of work, and has no mechanism to tie it to the outcomes the executive team cares about.
Why the data disappears
There are three reasons the ROI data gets lost:
Benefit tracking is assigned to the wrong team. Projects own the financial case. Change teams own the people case. When these are managed separately, the connection between adoption and benefit realisation is never made explicit.
The measurement points are front-loaded. Organisations invest in readiness assessment and go-live surveys, but rarely in systematic 60, 90, or 180-day post-implementation tracking. The data that would demonstrate sustained adoption, and connect it to financial outcomes, simply is not collected.
The business case is treated as a document, not a process. Once the investment is approved, the business case is filed. Nobody updates it as the programme delivers. The opportunity to demonstrate value in real time is missed.
What change management ROI actually means
Change management ROI, properly defined, is the net financial benefit delivered by structured change management investment across a programme or portfolio of change initiatives, expressed as a percentage of the cost of that investment.
The formula is conceptually straightforward:
Change management ROI = (Financial benefit delivered by change management / Cost of change management investment) x 100
The challenge is populating the numerator. Unlike a marketing campaign where you can track revenue from a specific channel, the financial benefit of change management is distributed across three layers, each of which requires a different measurement approach.
The three layers of change management ROI
Layer 1: risk mitigation and the cost of failure avoided
The first and most immediately legible ROI layer is risk mitigation: the financial cost that structured change management prevents, relative to what would have happened without it.
The research here is clear. According to Prosci’s 12th Edition Best Practices in Change Management, organisations with excellent change management are six times more likely to meet project objectives than those with poor change management. Willis Towers Watson’s Business Case for Change Management research found that organisations managing change well are 2.5 times more likely to outperform their peers financially and achieve 3.5 times more revenue growth than those that do not.
The risk mitigation value is calculated as:
Risk mitigation value = Project value at risk x Probability of failure without change management x Adoption uplift attributable to change management
For a $20 million ERP implementation with a historically observed 30% risk of low adoption without structured change management, and where change management is estimated to reduce that risk by 70%, the risk mitigation value is: $20M x 0.30 x 0.70 = $4.2 million.
This is a conservative approach. It does not require you to prove that change management delivered the outcome. It only requires you to quantify what was at risk and apply a defensible estimate of the change management contribution. Most project sponsors will accept this framing, because it mirrors how they think about insurance: you buy it to reduce the cost of failure, and you measure its value by what did not happen.
Layer 2: adoption rate improvement and benefit realisation
The second ROI layer is adoption rate improvement. Every change programme has a gap between theoretical benefit (what the change would deliver at 100% adoption) and realised benefit (what it actually delivers at actual adoption rates). Change management’s direct contribution is to close that gap.
This connection between adoption and financial outcomes is often treated as obvious in principle and ignored in practice. McKinsey’s analysis of large transformation programmes found that 42% of projected value is typically lost in the implementation and adoption phases, not because the technology failed, but because people did not use it consistently or at all.
The adoption value calculation is:
Adoption value = Programme benefit at full adoption x (Achieved adoption rate – Baseline adoption rate without structured change management)
If a new sales system is projected to deliver $5 million in productivity gains at 100% adoption, and your change management programme moves adoption from an estimated 55% baseline to 85% achieved, the adoption value is: $5M x (0.85 – 0.55) = $1.5 million.
The baseline adoption rate is the hardest variable to establish. The best approach is to use historical data from comparable programmes in your organisation where change management was minimal or absent. If that data does not exist, Prosci’s research provides sector benchmarks. Alternatively, model it as a sensitivity range (optimistic, base, conservative) and present the range to executives rather than a single point estimate.
Layer 3: benefit realisation acceleration and time-to-value
The third ROI layer is benefit realisation acceleration. Programmes with effective change management do not just achieve higher adoption. They achieve it faster. Every month that a programme runs at partial adoption is a month of benefit that is not being realised.
The acceleration value calculation is:
Acceleration value = Monthly programme benefit x Number of months of acceleration
If a programme is expected to deliver $500,000 per month in operational savings at full adoption, and effective change management accelerates time-to-full-adoption by three months, the acceleration value is: $500K x 3 = $1.5 million.
This calculation is particularly compelling for executives who think in terms of payback periods and net present value. A programme expected to break even at month 18 that breaks even at month 15 has materially better financial performance. Change management’s contribution to that acceleration is both quantifiable and credible, because it is directly connected to the adoption data collected throughout delivery.
The change management ROI calculation framework
The three layers above give you the components. The four-step framework below gives you the structure for assembling them into a business case that executives can interrogate and validate.
Step 1: Establish the cost-of-failure baseline
Before you can claim ROI, you need a denominator: what is this programme worth if things go wrong? Work with the project sponsor to document the total programme investment, the projected benefit at full adoption, the historical failure rate for comparable programmes in your organisation, and the known risk factors such as saturation, leadership misalignment, and competing initiatives.
This baseline is what makes your risk mitigation calculation credible. It also forces an honest conversation at the start of the programme about what is actually at stake.
Step 2: Define the adoption target and measurement approach
Agree in writing with the project sponsor and executive sponsor on what “full adoption” means for this programme (behaviours, not just system logins), how adoption will be measured, what the measurement cadence will be (go-live, 30 days, 90 days, 6 months), and who owns the adoption tracking.
This step is where most business cases fail. The measurement approach is left vague, and when adoption data is not collected systematically, there is nothing to put into the ROI calculation later.
Step 3: Track and update the business case in real time
As the programme delivers, update the business case with actual data: adoption rates at each measurement point, any acceleration or delay relative to the benefit realisation schedule, incidents or productivity dips that the risk mitigation value was designed to prevent, and stakeholder sentiment data that indicates future adoption trajectory.
The business case is a living document, not a filing artefact. If your change team cannot update the financial projections with real adoption data at each governance meeting, the business case has no credibility at programme close.
Step 4: Calculate and report total change management ROI at milestones
At programme close, or at significant milestones for longer programmes, aggregate the three layers:
Total change management value = Risk mitigation value + Adoption value + Acceleration value
Net ROI % = (Total value – Cost of change management) / Cost of change management x 100
Using the worked examples above: $4.2M + $1.5M + $1.5M = $7.2 million in change management value against $800,000 in change management investment. That is an ROI of 800%.
These numbers will vary significantly by programme. The point of the framework is not to produce an impressive-looking figure. It is to produce a number that is defensible, documented, and connected to data collected throughout the programme rather than reconstructed after the fact.
Five common mistakes when building the change management business case
Even practitioners who understand the three-layer model make predictable errors that undermine the credibility of their business case. These are the most common:
Writing the business case for investment approval, then never updating it. This is the single biggest failure mode. The business case becomes a sales document rather than a measurement tool. Any ROI calculation at programme close is regarded as self-serving, because there is no audit trail of data to support it.
Using adoption metrics that do not connect to outcomes. Training completion rates and email open rates are easy to collect but hard to connect to financial value. Define adoption in terms of the behaviour change that leads to outcomes, not proxy metrics that measure activity.
Failing to establish a counterfactual. A claim that “the programme delivered $5 million in value” is not the same as “change management delivered $5 million in value.” You need a credible baseline for what would have happened without structured change management. Without it, executives will rightly attribute the value to the technology or the project team.
Treating benefit realisation as someone else’s job. Change managers often hand off to the business at go-live and stop tracking. The adoption data that would close the ROI loop gets abandoned precisely when it becomes most valuable: in the 90 to 180 days post-implementation when sustained adoption either consolidates or erodes.
Building the business case in isolation. The strongest change management ROI cases are co-developed with finance, the project sponsor, and the executive sponsor. A number endorsed by the CFO carries substantially more weight than a number produced by the change team alone, even if the underlying methodology is identical.
How Change Compass measures and reports change management ROI
One reason change management ROI has historically been so difficult to demonstrate is the fragmentation of the data. Adoption surveys live in one system. Benefit realisation tracking lives in another. Stakeholder sentiment data, if it exists at all, lives in a spreadsheet that gets emailed around and then lost.
Change Compass addresses this by collecting the data throughout the programme rather than requiring you to reconstruct it at the end. The platform aggregates adoption tracking, stakeholder impact analysis, saturation measurement, and readiness scores across the entire portfolio, and surfaces them in reporting that connects the human side of change to programme outcomes in a format executives can act on.
For one enterprise client, this approach identified over $10 million in operational risk being carried silently across five concurrent initiatives, none of which had visibility into what the others were demanding from the same employee groups. Surfacing that risk early, and enabling the portfolio team to sequence and resource more intelligently, is precisely the kind of risk mitigation value that Layer 1 of the ROI framework is designed to capture.
Rather than assembling the change management ROI calculation retrospectively, Change Compass provides the data architecture to make it a running report throughout the programme. Adoption rates, readiness indicators, and saturation scores update in real time. When the executive team asks what the change function has delivered, the answer is already in the system.
For practitioners who want to understand how to structure that data for executive consumption, the Northwestern Mutual case study on elevating change data to executive level illustrates how a large financial services organisation made this shift from retrospective reporting to real-time portfolio intelligence. And for the mechanics of presenting that output in a format executives will actually read, the guide on creating executive-ready change management reports covers the practical steps in detail.
Making the business case a continuous practice
The change management business case is not a document you write at the start of a programme to secure investment. It is a measurement practice you maintain throughout the programme to demonstrate value, course-correct when adoption is lagging, and hold the organisation accountable for the commitments it made when it approved the investment.
This is a different operating model for many change practitioners. It requires agreement with the project sponsor on what will be measured and how. It requires access to the benefit realisation data that typically sits with finance or the business owner. And it requires a discipline of updating the business case at each governance milestone, not just at the end.
The organisations that do this consistently are the ones where change management has genuine executive sponsorship, not because the change team advocated for their own function, but because the data made the case. An adoption rate that moves from 55% to 85% over 90 days, tracked in a dashboard that the executive sponsor reviews every fortnight, is its own argument.
Start with one programme. Agree the measurement approach with the project sponsor before the work begins. Collect the adoption data at every defined milestone. Build an executive change management dashboard that shows the benefit case updating in real time. At programme close, calculate the return on investment using the three-layer framework and present it with the data that supports every number.
Done once, this gives you a template. Done consistently across a portfolio, it gives you the argument that change management is not a cost centre but a return-generating investment, with the evidence to prove it.
Frequently asked questions
What is change management ROI? Change management ROI is the measurable financial return delivered by structured change management investment, expressed as a percentage of the cost of that investment. It is calculated across three value layers: risk mitigation (the financial cost of failed adoption avoided), adoption rate improvement (higher adoption rates connected to greater benefit realisation), and benefit realisation acceleration (faster time-to-value). Each layer requires a different measurement approach and its own calculation.
How do you calculate change management ROI? Use a four-step framework: first, establish the cost-of-failure baseline by quantifying what is financially at risk if adoption is low; second, define the adoption target and agree the measurement approach with the project sponsor before delivery begins; third, track and update the business case in real time with actual adoption data at each governance milestone; fourth, aggregate the three ROI layers at programme close to produce a total value figure and a net ROI percentage.
How do you build a change management business case? An effective change management business case starts with a clear articulation of what is financially at risk if the change delivers low adoption. It then quantifies the likely impact of structured change management on three dimensions: risk reduction, adoption rate improvement, and benefit realisation acceleration. Critically, the business case must be co-developed with the project sponsor and updated throughout the programme with real adoption data, not written once and filed.
What is the typical return on investment for change management? Research by Prosci and Willis Towers Watson consistently finds that organisations with effective change management are two to six times more likely to meet project objectives than those without it. The financial ROI varies significantly by programme size and sector, but a disciplined three-layer calculation framework typically demonstrates returns well above 100% for structured change management investment on large transformation programmes where the value at risk is high.
How do you justify change management investment to executives? The most effective justification frames change management as risk reduction rather than a people process. Executives respond to financial risk arguments: if this programme delivers at 55% adoption instead of 90%, what is the cost of that gap? What has happened on comparable programmes in this organisation? A co-developed business case, endorsed by the project sponsor and finance, that quantifies risk mitigation, adoption improvement, and benefit acceleration in dollar terms is substantially more persuasive than activity metrics or anecdotal claims about the value of people-side support.
A Transformation Director recently described her tool selection process to me with a sentence that has stuck. “Most vendors we evaluated showed us a Gantt chart, a heatmap and a resourcing chart, and called it portfolio management. None of them could easily tell me which of our 30+ initiatives were competing for the same audience bandwidth, and none of them could explain why our adoption scores were sliding even though delivery was on track.”
This is the gap most buyers walk into. The change management software market has grown crowded over the last three years, and almost every vendor now promises a “single view of change”. For a PMO Director with a board paper due in two weeks, the demos look reassuringly similar. They are not. The difference between a visualisation tool and a real change portfolio management platform is the difference between a basic, generic dashboard and an intelligence layer that informs the decisions your executive team makes about sequencing, capacity and risk.
This guide is written for PMO/Transformation Directors and enterprise change leads who are evaluating a change portfolio management tool in 2026. It covers what the category actually requires, why your change data is your system of record, what AI features matter (and which to walk away from), and a seven-criteria framework to use in your shortlist conversations.
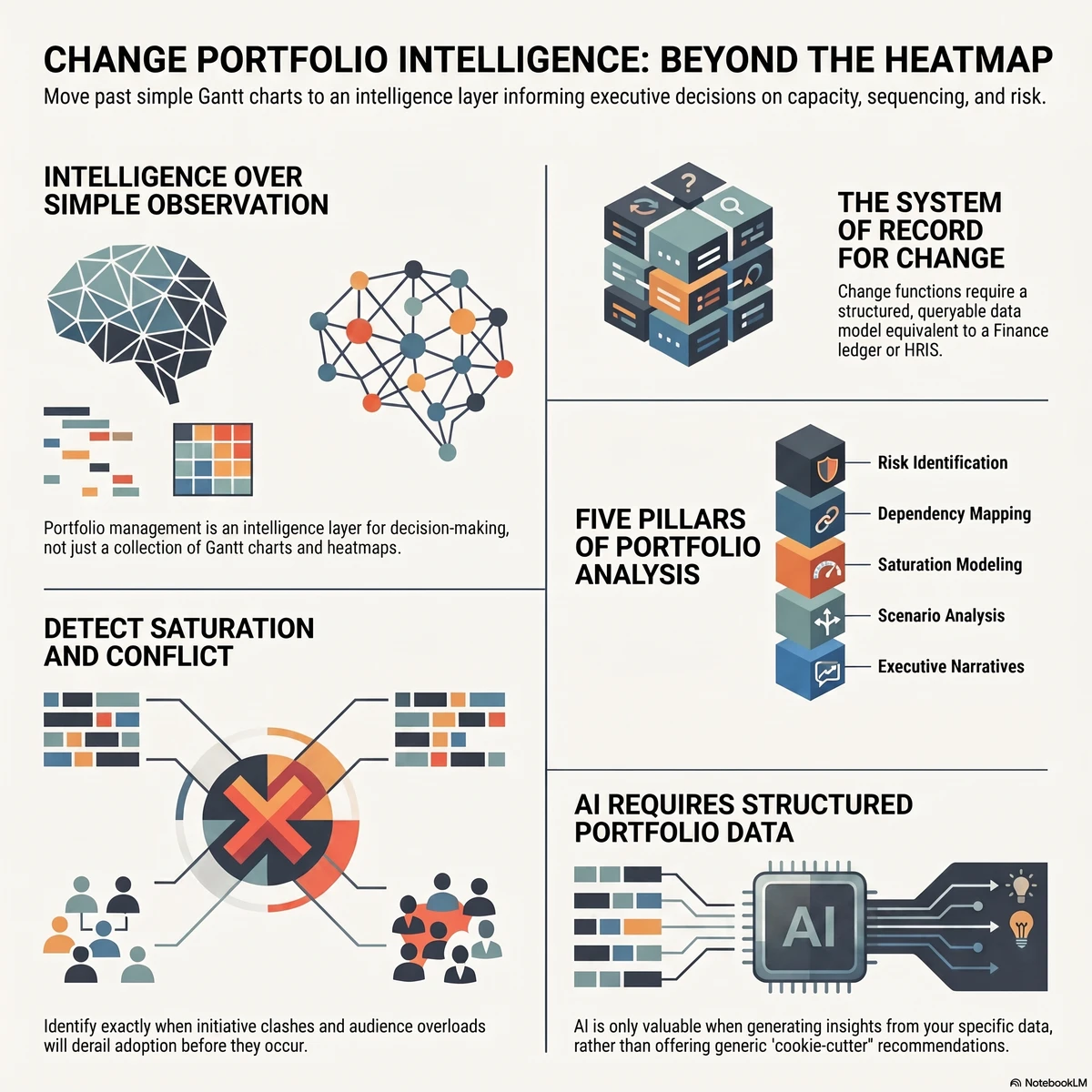
What change portfolio management actually is (and what most tools are selling instead)
Let’s start with a definition. Change portfolio management is the structured, systematic discipline of managing change across the enterprise portfolio. It includes initiative-level analysis, cross-portfolio risk and opportunity identification, capacity assessment, conflict detection and visual data storytelling that informs business decision making at executive level. It is not a chart. It is a practice supported by a system, built on a defined set of change portfolio management best practices.
Most tools you will see in vendor demos are selling a slice of this. They will show you three views and stop:
A Gantt or timeline chart of initiatives plotted across the next 12 to 18 months
A heatmap of impacts by business unit or stakeholder group, usually colour-coded by month
A resourcing chart showing change practitioner allocation across the portfolio
Those three views are useful as visual artefacts. They are not portfolio management. Portfolio management is what you do with them. The vendor that shows you a heatmap but cannot help you interrogate it, model alternative scenarios, or detect the structural risks hiding inside it has given you a clipboard, not a platform. A useful test in a demo: ask “Show me where two initiatives are competing for the same stakeholder group in the same fortnight, and what the projected adoption impact is if we don’t re-sequence.”
The work a PMO is being asked to do has changed. McKinsey’s research on transformation has consistently shown that the bulk of value erosion happens in implementation, not strategy, with 42 per cent of value lost in the implementation and scaling phases. The PMO is the function closest to that loss. To prevent it, you need to do analysis, not just observation.
The portfolio analysis layer most tools skip
The work that turns visualisation into intelligence sits in five activities:
Risk and opportunity identification across the portfolio (where are we exposed, where are we under-using capacity)
Cross-initiative dependency mapping (which initiatives share the same audience, the same systems, or the same critical resources)
Saturation and capacity modelling (what is the true change load on each business unit at each point in time, and where does that breach safe thresholds)
Scenario analysis (if we delay initiative X, what does the load profile look like, and which audiences benefit)
Executive narrative development (how do we tell this story in one slide that drives the right decision)
A change portfolio management tool earns the name when it can support all five. Anything that stops at heatmaps and Gantt charts has stopped at observation.
Why your change data is your system of record
Here is the part most PMO conversations skip. Every other corporate function has a system of record. HR has its HRIS. Finance has its general ledger. Operations has its ERP. Risk has its GRC platform. Change is the only enterprise function still routinely run out of spreadsheets, slide decks and project management tools repurposed for portfolio reporting.
This matters more than it sounds. The system of record is not the tool. It is the authoritative source of data on which decisions are made. When the CFO needs to know the cash position, they don’t ask three teams to email their numbers and reconcile them in Excel. They look at the ledger. When the CHRO needs to know headcount, they look at the HRIS. The PMO is the function that should be the system of record for change data, and most PMOs aren’t, because they don’t have a tool that can hold the data in a structured, queryable, executive-ready form.
Why is this the foundation? Because the data informs everything that comes after it. The approach you recommend to the business, the sequencing decisions you make, the capacity warnings you raise, the readiness conclusions you draw. All of these are only as credible as the data underneath them. If your data lives in fragmented spreadsheets owned by individual change managers, your recommendations are anecdotal. If your data lives in a structured portfolio platform with consistent impact frameworks, audience taxonomies and historical patterns, your recommendations are evidence-based. The platform is upstream of the conversation.
This is also why a change portfolio tool is fundamentally different from a project management tool. Monday, Smartsheet and similar platforms are excellent at task tracking and team coordination. They are not designed to hold change data as a system of record. The fields they track (task, owner, status, due date) are not the fields a change leader needs to make portfolio decisions (impacted audience, change type, adoption risk, saturation contribution, dependency map). Trying to bolt change portfolio management onto a project management tool is like trying to run payroll out of Trello. It will technically work for a while, and it will fail at scale.
For a fuller treatment of why the change function deserves its own intelligence layer rather than a project tool with extra columns, the change intelligence platform pillar article goes deeper into the architecture.
Why standard charts cannot tell your story
The second area where tools quietly fail is data visualisation. The PMO’s job is not to display data. It is to influence executive decisions using data. Those are different jobs, and they need different visualisations.
Most vendors offer a fixed set of charts: a Gantt timeline, an impact heatmap, a resourcing bar chart, possibly a stoplight summary. These are fine for an analyst staring at a screen for ten minutes. They are not what a CEO needs to see in a 5-minute portfolio update.
The complexity of an enterprise change portfolio is genuinely high. You are simultaneously tracking initiatives with different start dates, different audiences (sometimes overlapping, sometimes nested), different change types, different risk profiles, different dependencies and different stages of maturity. A standard chart library can show you any one of those dimensions. None of them can show you the story you need to tell, which is usually two or three of them intersected.
What this means in practice: the data visualisation in a real portfolio tool needs to be flexible. You need to be able to filter, slice, overlay, drill down and reshape the view to match the question being asked. The CFO has a different question to the COO. The board wants a different cut to the divisional MD. The sequencing committee needs to see something different to the audit committee. If your tool gives you the same three charts for all of them, you are doing manual translation work every week that a properly designed platform would do in real time.
A practical test: in your shortlist demos, ask the vendor to build a chart that shows you the top five stakeholder groups by impact load over the next quarter, then layer in the projected change saturation score for each, then highlight which initiatives are driving the highest contribution. If the answer is “we’d need to build a custom report”, you’ve found the ceiling. If they can do it live in the platform, you’ve found a real visualisation engine.
The principle is straightforward: complex change demands flexible visualisation. The story changes, the audience changes, the question changes. The chart must change with it, and one glance must do the work.
AI features: what to look for, what to avoid
If you are evaluating change portfolio tools in 2026 and AI is not on your criteria list, your evaluation is out of date. The PMO use cases for AI fall into two buckets, and both matter:
Reducing manual effort. A change portfolio generates an enormous volume of administrative work: drafting impact statements, summarising initiative updates, normalising data from different change managers, generating stakeholder communications, building first-cut readiness assessments. A capable AI layer should automate large parts of this without removing the change manager from the loop.
Generating insight. This is the higher-value bucket and the one most providers are weaker on. The AI should be able to look across your portfolio and tell you things you wouldn’t have spotted by hand: emerging saturation hotspots, audience groups whose risk profile has shifted, initiatives whose adoption trajectory is diverging from the plan, dependencies that have moved into the critical path.
Both buckets require one thing the vendor demos often skip past: your data. This is the point many PMOs miss when they’re comparing tools against ChatGPT or Copilot. General AI tools cannot do portfolio-level work for you because they have no portfolio data. They can draft a generic impact statement. They cannot tell you that your Q3 SAP rollout is the third initiative landing on Operations in eight weeks and that adoption is at risk because Operations is already at 87 per cent of safe load. The data is what makes the AI useful.
There is a sharper version of this point worth making to your executive team. General-purpose AI tools used without your organisation’s change data will give you cookie-cutter recommendations. The bigger risk is not that the recommendations are generic. It is that they are confidently wrong, in a way that sounds plausible enough to act on. A general model with no context about your portfolio will recommend an approach that’s wrong for your sector, your maturity, your stakeholder base or your sequencing reality. The cost is not the bad recommendation. The cost is the time spent going down a wrong path because the recommendation sounded sensible. We treat this risk in more depth in the companion piece on AI change management automation, which explains the architecture difference between general AI and a change-data-informed AI layer.
What this means for your buyer’s evaluation:
The AI features must be trained on or fed by your portfolio’s structured change data, not bolted on as a generic LLM wrapper
The vendor should be able to demonstrate insight generation, not just text generation (drafting a paragraph is table stakes; spotting a saturation risk is differentiation)
There must be a clear and consistent path for human-in-the-loop review on any AI-generated recommendation that flows to executives
The AI must explain its reasoning (what data did it use, what assumptions did it make), so the change leader using it can defend the recommendation in the room
The vendor that says “yes, we have AI” without being able to demonstrate the data plumbing is, with respect, behind. AI without your data is generic by definition.
The seven criteria for evaluating a change portfolio management tool
If you take one artefact from this article into a shortlist conversation, take this. These are the seven evaluation criteria we recommend PMO Directors use, in priority order. Each is followed by a question to ask in the demo.
#
Criterion
Question to ask in the demo
1
Portfolio analysis depth
“Show me how you identify cross-initiative risk and opportunity, not just where you display it.”
2
Data as system of record
“What is the data model? Can it hold consistent impact, audience and saturation data across all initiatives, regardless of who entered it?”
3
Flexible data visualisation
“Build me a chart now, live, showing X dimension intersected with Y dimension for the top Z audiences.”
4
AI features informed by portfolio data
“Demonstrate one insight the AI surfaced that a human wouldn’t have spotted.”
5
Executive-ready outputs
“Show me the slide or dashboard you would put in front of my CEO. Can it be filtered by their question in real time?”
6
Saturation and capacity modelling
“How do you measure saturation? Is it a real model with thresholds, or a colour applied to a heatmap?”
7
Conflict and dependency detection
“Show me where two initiatives are competing for the same audience in the same window. Did the platform flag it, or did I have to find it?”
The order matters. A platform can have beautiful visualisations and weak data. A platform with weak data will mislead you. Start at criterion two if you’re tight on time. If the data model doesn’t hold up, nothing built on top will.
A few of these are worth a closer look.
Saturation and capacity
Change saturation is the single biggest cause of preventable adoption failure. Prosci’s research and our own client data consistently show that organisations that exceed their safe change load see a measurable drop in adoption rates, often well before any single initiative shows red on its individual report. The portfolio view is the only place this risk becomes visible.
A real saturation model has thresholds (per audience, per role, sometimes per geography), tracks contribution by initiative, and forecasts forward. A fake saturation feature is a heatmap with three colours. Make sure you can tell the difference. For more on the model, see our practical methodology for measuring change saturation.
Conflict and dependency detection
The structural problem with most enterprise change portfolios is not that the initiatives are individually badly run. It is that they are individually well run, on parallel tracks, by teams that never see each other’s stakeholder lists. Conflict detection is the platform capability that makes the hidden visible. Two initiatives competing for the same business unit in the same fortnight is a problem you cannot solve if you cannot see it. The right tool surfaces this automatically, not on request.
Executive reporting
The most overlooked criterion. Your tool is doing one of two things at executive level: making you look credible, or making you look like the spreadsheet team. There is no middle. The platforms that win at this layer let you generate executive views in real time, filter them live in the meeting, and answer questions on the spot. The ones that lose make you go away, build a slide and come back next week.
For a worked example of what executive-grade reporting looks like at a Fortune 500 financial services firm, see our case studies on elevating change data to the executive table.
The vendor landscape: what’s actually out there
The change portfolio management category includes four kinds of tools that PMOs commonly evaluate. None are equivalent.
1. Project and work management platforms (Monday, Smartsheet, Asana, Jira, Microsoft Project). Strong at task tracking, team coordination and basic Gantt visualisation. Weak at change-specific data structures (impacted audience, change type, saturation contribution) and almost universally weak at portfolio-level analytics. Useful as your delivery tool. Not a change portfolio platform. The common failure mode is the PMO that tries to retrofit Monday with custom columns and reports, ends up with a high-maintenance spreadsheet, and concludes “tools don’t work for change”. The tool wasn’t built for change.
2. HR analytics and employee experience platforms (Workday Adaptive, Visier, Glint, Culture Amp). Strong at employee sentiment, engagement data and HR analytics. Weak at initiative tracking and portfolio composition. Useful as a complementary data source feeding readiness insights. Not a portfolio platform on their own.
3. General-purpose AI tools (ChatGPT Enterprise, Copilot, Claude, Gemini). Strong at text generation, drafting and conversational analysis. Weak at portfolio data management because they don’t have your data. Useful as a productivity layer for individual change managers. Not a portfolio platform.
4. Purpose-built change portfolio platforms (The Change Compass and a small number of others). Designed from the data model upwards for change portfolio work: change-native fields, structured audience taxonomies, saturation modelling, cross-initiative analytics, AI insight layer informed by portfolio data, executive-grade visualisation. This is the category to evaluate against your seven criteria.
This taxonomy matters because the wrong category will look adequate in the first 90 days. The cracks show at scale, when the portfolio grows past 20 to 30 active initiatives, when the executive team starts asking forward-looking questions, and when adoption issues start surfacing that the tool cannot diagnose.
A short list of things that should slow your evaluation down, not speed it up:
The demo shows the same three charts (Gantt, heatmap, resourcing) and the vendor calls it portfolio management
The vendor cannot answer how their AI uses your data (the answer “we use OpenAI’s API” is not an architecture)
The data model is not visible or not explained, or every customer apparently configures it from scratch
Saturation is described but not measured (no thresholds, no model, just colour)
Executive reporting is “we’ll build you a custom dashboard” rather than a real-time configurable view
Conflict and dependency detection requires a custom report or human analysis to surface
The vendor’s reference customers are all individual change managers, not PMO Directors or transformation leaders
Pricing is not anchored to data volume or portfolio size, which usually means it will become anchored to them later
None of these is fatal on its own. A pattern of three or more should make you go back to the brief.
What the right tool actually does for you
The point of all of this is not the tool. It is the outcomes the right tool unlocks. A real change portfolio management platform should move the needle on three things:
Systemic change capability. Not the capability of individual change managers, who are usually competent. The capability of the function as a whole to do portfolio-level work consistently. A platform with a real data model lifts the floor of the function. Less time spent reconciling spreadsheets, more time spent on analysis, advisory and influence.
Adoption and readiness. The downstream measure. Better data leads to better sequencing decisions, better load management, better stakeholder conversations and better readiness preparation. Better readiness preparation leads to better adoption. The mechanism is upstream. The result is adoption rates that move because the underlying conditions move.
Executive influence. The metric most PMO Directors quietly care about. Your change data, when held in a system of record and visualised flexibly, becomes a data set the executive team treats as authoritative. The conversation moves from “the change team is asking us to slow down” to “the portfolio data shows we are at 92 per cent capacity in Operations next quarter, here is the sequencing recommendation”. This is the shift Northwestern Mutual described in their work with us: change data elevated to the same level of visibility and priority as financial and operational data.
The Change Compass is the platform we’ve built for this category. We exist because PMO Directors at firms like Northwestern Mutual, IAG and NiSource told us the tooling they had wasn’t enough. We aren’t the only option you should evaluate. We are the option you should benchmark the rest against. If you’d like to see what a purpose-built change portfolio platform looks like applied to your portfolio, our team runs PMO-focused demos that walk through the seven criteria above using real data structures. Book one, or pressure-test your shortlist against the criteria with your own internal team. Either way, the framework is what matters.
Where to start
If you take one action from this article, make it this: before you sit through another vendor demo, write down the three portfolio questions your executive team is asking that your current tooling cannot answer cleanly. Maybe it’s “are we going to overload Operations next quarter”. Maybe it’s “where are two initiatives quietly competing for the same audience”. Maybe it’s “what’s our forward 12-month saturation curve and where does it breach”. Bring those three questions to every demo. Ask each vendor to answer them live, with their tool, using a portfolio data set, not a slide deck. The right tool will answer at least two of them in the demo and show flexibility in catering for audience needs.
The category is changing fast and the gap between the visualisation tools and the real portfolio platforms is widening, not narrowing. Choose the platform that treats your change data as a system of record, makes it flexible to visualise, applies AI on top of it rather than instead of it, and gives you outputs your executive team actually uses. That’s the buy that pays back. Anything less is a clipboard. If your executive team still needs convincing that portfolio data belongs on their agenda, our guide to building change portfolio literacy in senior leaders covers how to bring them along.
What is a change portfolio management tool? A change portfolio management tool is a software platform built specifically to hold, analyse and visualise change data across an enterprise portfolio of initiatives. It is distinct from a project management tool (which tracks tasks and timelines) and from a general BI or analytics tool (which lacks change-specific data structures). It supports portfolio-level activities such as risk identification, capacity and saturation modelling, conflict and dependency detection, and executive reporting.
How is change portfolio management different from project portfolio management? Project portfolio management focuses on delivery: what initiatives are running, who owns them, what milestones are due, what budget is committed. Change portfolio management focuses on the people-side outcomes: which audiences are impacted, by what change types, at what load, with what adoption risk. The two are complementary, but the data structures and the analytical questions are different. A PPM tool tells you whether projects are on track. A change portfolio tool tells you whether your organisation is on track to absorb them.
Do general AI tools like ChatGPT or Copilot replace the need for a change portfolio platform? No. General AI tools are useful for individual productivity tasks (drafting communications, summarising notes, generating first-cut content). They are not portfolio platforms because they don’t hold your change data as a system of record. Recommendations from general AI tools without your portfolio data tend to be generic at best and confidently wrong at worst, because they have no context for your sector, your maturity, your stakeholder base or your sequencing. The two tool categories are complementary, not substitutes.
What is the most important criterion for choosing a change portfolio tool? The data model. A platform with a strong data model can be improved everywhere else; a platform with a weak data model can never be saved by features bolted on top. Ask the vendor to explain how the platform holds impact data, audience taxonomies, saturation contribution and dependencies in a consistent, queryable structure. If they cannot explain it clearly, that’s your answer.
How long should a tool evaluation take? For an enterprise PMO, expect six to twelve weeks from shortlist to decision. The two highest-leverage activities in that window are: (a) running a pilot against your real portfolio data, not a demo data set, and (b) interviewing two or three reference customers at PMO Director level, not change manager level. Skipping either of those will cost you more later than they cost you now.
A change management centre of excellence is usually busy, well-liked, and quietly vulnerable. It runs the methodology, maintains the templates, trains the practitioners, and deploys change managers onto whichever projects shout loudest. Everyone who works with it says good things. And then a new CFO arrives, asks what measurable difference the function makes to the outcomes the board cares about, and the honest answer turns out to be a list of activities rather than a line of evidence. Within two budget cycles the centre is reframed as a cost, its people are redistributed into the business, and the organisation goes back to doing change one project at a time.
This is a common occurance of a change management centre of excellence built on the wrong premise. Most are built as one of two things: a methodology/learning team to improve ‘capability’, or a body shop of change managers. The library version owns standards, templates, and training, and measures itself by adoption of the method. The body-shop version is a pool of change practitioners deployed to projects, measured by utilisation. Both are operationally useful. Neither is strategic, and neither survives serious scrutiny, because both answer the question “are we doing change management well?” when the question executives are actually asking is “will the things we are betting the company on actually land, and can we see the risk in time to act?”
The centres that endure are designed backwards from that second question. They are aligned to executive outcomes, they allocate their scarce resources by strategic importance rather than by who asked first, and they offer differentiated levels of service rather than spreading a thin layer of support evenly across every initiative. Most importantly, they sit on an intelligence layer that lets them see the whole portfolio, which is what separates a strategic capability from a craft shop. This article lays out what that actually requires.
What a change management centre of excellence is actually for
The purpose of a change management centre of excellence is not to do change management well in the ‘theory’. It is to increase the probability that the organisation’s portfolio of change lands, and to give leadership visibility of the risk to that portfolio while there is still time to act. Everything else, the standards, the tooling, the coaching, is in service of that outcome, not an end in itself. When a centre forgets this, it optimises its craft and loses its mandate.
The two default models and why they plateau
The methodology-capability model treats the centre as the custodian of “how we do change here”. It standardises the approach, builds templates, accredits practitioners, and runs a community of practice. This is genuinely valuable, and it is where most centres should start. But it plateaus, because a library is a fixed asset that depreciates. Once the method is published and people are trained, the marginal value of the library falls, while its visible cost stays the same. A library or a distributed change capability improvement at some level cannot tell an executive anything about whether the portfolio is at risk.
The body-shop model treats the centre as a resourcing pool. It hires change managers centrally and deploys them to projects on demand, billing time and measuring utilisation. This feels strategic because it is operationally indispensable, but it is the more dangerous trap of the two. A body shop scales linearly: more change requires more people, costs rise in lockstep with demand, and the function is permanently one efficiency drive away from being outsourced. Worse, because each practitioner is embedded in a single project, no one in the body shop sees across the portfolio. The function that should hold the enterprise view instead holds dozens of disconnected project views.
The strategic reframe: design backwards from outcomes
The reframe that escapes both traps is to design the centre from executive outcomes backwards. Instead of asking “what does good change management look like and how do we deliver it everywhere”, ask “what do our executives need to be confident about to run successful change and transformation, and what would the centre have to see, know, and do to give them that confidence”. The answer reorganises the whole function. It makes portfolio visibility a core capability rather than an afterthought. It makes prioritisation a deliberate act rather than a queue. And it makes the centre a source of intelligence about enterprise risk, not just a supplier of change-management labour.
Start with the outcomes executives actually want
Executives do not want better change management … necessarily. They want a small number of outcomes, and a change management centre of excellence earns its mandate by being demonstrably the function that improves them. In practice, senior leaders are looking for four things from the change portfolio:
Confidence that the critical initiatives will land. Not activity reports, but a credible read on whether the changes the strategy depends on will actually be adopted.
Early warning on risk. The ability to see an adoption problem, a capacity breach, or a conflict between initiatives early enough to do something about it, rather than in a post-implementation review.
Value realisation. Evidence that the benefits in the business case are being captured, and a clear account of where they are leaking. This is the territory of the return on investment of change management, and it is the language that wins executive sponsorship.
Capacity/adoption intelligence for decisions. A defensible answer to “can the organisation absorb this on top of everything else and how are we on track to fully adopt the changes”, so that portfolio and investment decisions are made against real capacity/adoption rather than optimism.
Notice what is not on that list: methodology adoption, template usage, practitioner accreditation, utilisation. Those are means, and a centre that reports them to executives is answering a question no one asked. Design the centre so that its core reporting speaks directly to the four outcomes above, and the conversation about its value changes entirely.
The capabilities a strategic change CoE needs
A strategic centre needs five core capabilities. The first three are what most centres already have or aspire to. The last two are what separate a strategic capability from a methodology library, and they are the ones most often missing.
Capability
What it delivers
Executive outcome it serves
Maturity signal
Standards and method
A consistent, fit-for-purpose change approach
Confidence in delivery quality
The method is used because it helps, not mandated
Tools and templates
Reusable artefacts that lower the cost of good practice
Efficiency and consistency
Practitioners reach for them by default
Coaching and capability building
Skilled change practitioners and change-capable leaders
Confidence the critical initiatives will land
Business leaders run change competently with light support
Portfolio visibility and intelligence
A live, aggregated view of change load, risk, and conflict across the enterprise
Early warning on risk; capacity intelligence
Leadership consults the centre before approving new initiatives
Governance and prioritisation
Disciplined allocation of scarce change resource to what matters most
Value realisation; capacity intelligence
The centre can say no, or not yet, with evidence
The capability that does the most to make a centre strategic is portfolio visibility. A centre that can see across every active initiative, where the load is concentrated, where initiatives collide, which stakeholder groups are saturated, is a centre that can answer the executive’s real questions. Without it, even a well-run centre is, in effect, a methodology library with a coaching service attached. This is also the capability that benefits most from AI-supported change automation, because aggregating and interpreting portfolio data at scale is precisely the kind of work that is impractical to do manually across dozens of initiatives.
Prioritise by strategic importance, not by who asks first (or is more influential)
The defining constraint of every change centre is that change resource is scarce and demand is effectively unlimited. Every initiative wants a change manager. The body-shop response is to ration by availability and seniority, which means resource flows to the loudest sponsors rather than the most important initiatives. The strategic response is to allocate deliberately, by strategic importance.
This requires the centre to hold an explicit view of which initiatives matter most to the enterprise, and to be willing to differentiate. Not every initiative deserves a dedicated change lead, and pretending otherwise is how centres spread themselves so thin that they add little anywhere. The uncomfortable truth is that a centre trying to support everything equally is implicitly deprioritising the initiatives that matter most, by denying them the depth of support their importance warrants. Prioritisation is not bureaucracy. It is the mechanism by which a scarce resource is pointed at the highest-value work, and it is impossible to do credibly without the portfolio visibility described above.
The shift is easier to see with a concrete picture. Consider a centre with six change practitioners facing a portfolio of thirty initiatives. The body-shop instinct is to spread those six across as many initiatives as possible, giving each a fraction of a change manager and none of them enough. Every initiative gets a name against it, and almost none get real support. The strategic alternative is to look at the thirty through the lens of strategic importance, identify the three that the corporate strategy genuinely depends on, and place a dedicated senior lead on each. The remaining three practitioners then run a coaching model across the next tier of important initiatives, while the rest are served by self-serve enablement and portfolio tracking. The same six people now create disproportionate value on the initiatives that matter, instead of uniform mediocrity across all thirty. The only thing that changed was the willingness to differentiate, backed by a clear view of which initiatives sit where.
A tiered service model for limited change resources
The practical expression of prioritisation is a tiered service model. Rather than offering one undifferentiated service (a change manager on your project) to whoever secures one, a strategic centre offers different levels of service matched to the strategic importance and complexity of each initiative. This is the single most effective move a centre can make to escape the body-shop trap, because it breaks the assumption that the centre’s only product is one-to-one practitioner deployment.
A workable four-tier model looks like this:
Tier
Who it is for
What the centre provides
Resource intensity
Tier 1: Embedded
The handful of enterprise-critical, high-complexity initiatives
A dedicated, senior change lead working full-time on the initiative
High
Tier 2: Guided
Important initiatives with a business-side change owner
A centre consultant who coaches the embedded owner, reviews artefacts, and assures quality on a regular cadence
Medium
Tier 3: Enabled
Standard initiatives run by capable business teams
Self-serve toolkit, templates, training, and scheduled office hours; the business runs its own change
Low
Tier 4: Tracked
Everything else with a change footprint
No direct support, but the initiative is captured in the portfolio view for load, conflict, and saturation monitoring
Minimal
Three things make this model work. First, the tier is assigned by strategic importance and complexity, not by who asks, which is what enforces the prioritisation discipline. Second, every initiative gets something, even if it is only Tier 4 portfolio tracking, which means the centre retains enterprise-wide visibility rather than only seeing the projects it staffs. That visibility is what lets the centre answer portfolio-level questions no body shop can. Third, the model scales without scaling headcount linearly, because most initiatives sit in the lighter tiers, and the centre’s scarce senior practitioners are concentrated where they create the most value.
The tiered model also reframes the centre’s identity. It is no longer “the place you get a change manager”. It is the function that decides, on evidence, how much and what kind of change support each initiative warrants, and that holds the only complete view of change across the enterprise. That is a strategic position. A body shop can never occupy it.
The intelligence layer that makes a centre strategic
Every capability above depends on one thing the traditional centre lacks: a live, aggregated view of change across the whole portfolio. Without it, prioritisation is guesswork, the tiered model cannot see what sits in Tier 4, and the executive outcomes about risk and capacity cannot be answered at all. This is why a change management centre of excellence without portfolio data is, in the end, a methodology library with good intentions.
This is the role a change intelligence platform plays for the centre. Change Compass aggregates impact, load, and risk data across every initiative in the portfolio, giving the centre the enterprise-wide view that turns it from a craft function into a strategic one. It is what lets the centre tell an executive, with evidence, that a stakeholder group is saturated, that two initiatives are about to collide, or that the portfolio is carrying more change than it can absorb. The platform does not replace the centre’s people or method. It gives them the intelligence layer that makes their judgement visible and credible at the enterprise level. For centres evaluating how to build this, the criteria are the same ones covered in any serious assessment of change portfolio management tools.
The maturity journey from informal to embedded
No centre arrives fully formed, and trying to stand up all five capabilities at once is a common way to fail. The journey runs through three broad stages.
Informal
Change is done project by project, with no shared method and no central function. Some practitioners are good, some are not, and there is no enterprise view. The first move is to establish standards and a small core team: the methodology-library foundation, which is a legitimate and necessary starting point.
Functional
The centre exists, owns the method, builds capability, and deploys or coaches practitioners. This is where most centres stall, because it is comfortable and visibly useful. The risk is mistaking this stage for the destination. A functional centre is still answering “are we doing change well”, not “will the portfolio land”.
Strategic and embedded
The centre operates the tiered service model, allocates by strategic importance, holds the portfolio intelligence, and reports to executives in the language of risk, capacity, and value. At this stage the centre is consulted before initiatives are approved, not just after they are funded. It has moved from supporting change to shaping the change agenda, and its mandate is secure because its value is visible in the outcomes leaders care about.
Where to start
If your centre today is a library, a body shop, or both, the highest-value first move is not to add people. It is to build the portfolio view and reframe what the centre reports. Start tracking every initiative with a change footprint, even the ones you do not staff, so you can see the enterprise picture. Then introduce the tiered service model, so your scarce senior practitioners are concentrated on the initiatives that matter most rather than spread evenly across all of them. Finally, change what you report to executives, from activity and utilisation to portfolio risk, capacity, and value realisation. A change management centre of excellence becomes strategic the moment it can answer the question executives actually ask, which is not whether change is being managed, but whether the things the organisation is betting on will land, and whether anyone can see the risk in time. Build the centre that answers that, and it will not be the function that gets cut in the next review. It will be the one the board asks for more of.
Frequently asked questions
What is a change management centre of excellence? A change management centre of excellence is a central function that raises the probability the organisation’s change portfolio succeeds, by owning the change method, building capability, allocating scarce change resource, and holding an enterprise-wide view of change risk and capacity. The strongest centres are defined by their portfolio intelligence and executive alignment, not just by the methodology and templates they maintain.
What does a change COE actually do? At maturity, a change COE does five things: it sets standards and method, provides tools and templates, builds change capability through coaching, maintains portfolio visibility across all initiatives, and runs the governance and prioritisation that directs limited change resource to the most important work. The first three are common; the last two are what make a COE genuinely strategic rather than a methodology library.
How do you structure a change COE with limited resources? Use a tiered service model that matches the level of support to each initiative’s strategic importance and complexity. A typical model has four tiers: a dedicated change lead for enterprise-critical initiatives, a coaching and assurance model for important ones, a self-serve toolkit for standard ones, and portfolio tracking only for the rest. This concentrates scarce senior practitioners where they add the most value and keeps every initiative visible.
How is a change COE different from a project management office? A PMO is generally concerned with delivery of projects: scope, schedule, budget, and dependencies. A change COE is concerned with adoption of the changes those projects create, and with the cumulative impact of change on the workforce. The two are complementary, but a change COE answers questions a PMO cannot, particularly about stakeholder load, change saturation, and whether the organisation can absorb what it is delivering.
How do you measure the value of a change COE? Measure it in the language executives use: confidence that critical initiatives will land, early warning on portfolio risk, value realisation against business cases, and capacity intelligence for investment decisions. Avoid reporting only activity metrics such as methodology adoption or practitioner utilisation, because they describe effort rather than the outcomes leadership actually cares about.
Ask a senior change manager in a large organisation whether their portfolio contains change conflicts and the honest answer is usually some version of “probably, but I couldn’t tell you exactly where”. That is not a failure of effort. It is a failure of visibility. In a portfolio of fifteen to forty concurrent initiatives, each governed in its own steering committee with its own definition of success, conflicts between initiatives are the default condition, not the exception. The harder problem is that the conflicts only become obvious in hindsight: in next quarter’s engagement dip, in a softening adoption curve, in a manager’s exit interview that mentions “too much change at once” without naming the specific collisions that caused it.
Change conflict, in the portfolio sense, is any structural collision between two or more change initiatives that competes for the same finite resource inside the impacted employee’s experience. The resource might be attention, time, behavioural bandwidth, leadership credibility, training capacity, or system stability. The conflict is rarely deliberate. It is the predictable consequence of running multiple initiatives that were each designed in isolation, governed in isolation, and measured in isolation.
This is a different concept from interpersonal conflict on a team, and different again from project portfolio dependency conflict in the PMO sense (where the unit of analysis is the deliverable, and the conflict is over scope, schedule, budget, or sequencing of project outputs). Change conflict sits between the two. The unit of analysis is the impacted employee, and the resource being competed for is their absorption capacity. A portfolio with zero project-dependency conflicts can still saturate the workforce in ways that destroy adoption, because the project view does not look sideways at the employee experience.
Change conflict is also one of the principal mechanisms that produces change saturation at the portfolio level. Saturation is the state in which the workforce can no longer absorb additional change. Conflict is one of the underlying drivers, because it draws on the same finite resource from multiple directions at once. Detecting conflict early is one of the most direct levers an organisation has for preventing saturation. Saturation is the outcome. Conflict is one of the causes you can actually do something about.
Why change conflicts are structurally hard to detect
Change conflicts are not hard to detect because they hide. They are hard to detect because the systems we use to govern change portfolios were never designed to see them.
Each initiative has its own sponsor, steering committee, status report, and definition of success. Every one of those artefacts looks inward at the initiative. None of them looks sideways at the other initiatives sharing the workforce. The PMO sees deliverables. The change team sees their initiative’s stakeholders. The HR business partner sees engagement scores. The line manager sees their day. No node in standard project governance is responsible for the intersection.
The result is that conflicts can only be diagnosed retrospectively: in the engagement survey that lands two quarters later, in the adoption metric that softens without obvious cause, in the spike of mid-level attrition, or in the post-implementation review that traces failure to “change fatigue” without naming the specific collisions that caused it. By that point, the cost has compounded, the conflicts that produced it have moved on, and the next portfolio cycle repeats the pattern.
Change conflict detection, as a discipline, is the deliberate work of closing this gap. It treats portfolio collision as a discoverable, classifiable, real-time signal rather than a retrospective story. To do that, you need three things: a named taxonomy of conflict types so you know what you are looking for, a method for surfacing each type before it manifests, and a data layer that can aggregate impact across initiatives without depending on spreadsheets that age out within a fortnight.
The five types of change conflict you need to detect
Change conflict shows up in five distinct, recognisable forms. The categories are not academic. Each has its own diagnostic signal and its own characteristic failure mode when undetected.
Scheduling conflict
The most familiar type, and the only one most PMOs actively manage. Scheduling conflict occurs when two or more initiatives require the same group of employees to engage with major change events in the same window. Two go-lives in the same fortnight. A system cutover the same week as a structural reorganisation announcement. A mandatory training module landing in the same sprint as a performance-review cycle change.
Scheduling conflict is the easiest to spot, because dates are visible, but it is the most underestimated. Resolving it by sliding events apart by a week declares the problem solved without addressing the cumulative cognitive load on the same group across a six-week absorption window.
Priority conflict
Priority conflict occurs when two initiatives ask the same employee, manager, or team to treat their initiative as the top priority for the same period. Operations excellence asks branch managers to focus on cost reduction. The customer experience programme asks them to focus on relationship deepening. The risk culture initiative asks them to focus on conduct and escalation discipline. Each is a legitimate priority on its own. Together, in the same quarter, they are a contradiction.
This is the most corrosive of the five, because it cannot be resolved by sequencing. Employees and middle managers eventually pick one, usually the one whose owner has the most political weight, and the others quietly fail. Detection requires you to compare not just calendars but stated priorities, by stakeholder group.
Leadership and management messaging conflict
Leadership messaging conflict happens when the senior leaders associated with different initiatives say things that contradict each other, or use language that signals different cultures, values, or behavioural expectations. The CFO writes that “speed of execution” is the strategic priority. The CHRO writes that “psychological safety” is the cultural shift. The COO emails about “doing more with less”. The CEO speaks about investing in capability. Together, in the same eight-week period, they tell the employee that leadership does not know what it wants.
Prosci’s 12th Edition Best Practices in Change Management (drawing on more than 10,800 practitioners) repeatedly identifies active and visible sponsorship as the single largest predictor of change success. The corollary, that contradictory sponsorship is a primary predictor of failure, is the part most organisations under-instrument. Management messaging conflict is the line-manager version of the same problem: when middle managers are asked to coach contradictory behaviours, they default to delivering neither.
Behavioural conflict across initiatives
Behavioural conflict is distinct from messaging conflict. Messaging conflict is what leaders say. Behavioural conflict is what initiatives require employees to actually do. Two initiatives can have aligned leadership messaging and still ask employees to perform contradictory behaviours on the ground.
A common example sits in regulated contact-centre environments. A regulatory change programme implements a new disclosure obligation requiring agents to disclose additional product or risk information to customers and to actively prompt for follow-up questions before closing the call. At the same time, the operational leadership team is running an efficiency initiative aimed at reducing the average handle time per call. Both initiatives are legitimate, both have executive sponsors, and both are being delivered correctly within their own scope. From the agent’s seat, they are mutually exclusive instructions arriving in the same week from different parts of the organisation, with no forum in which the contradiction can be raised. A second common pattern: a risk-conduct programme asks bankers to escalate any uncertainty, while a sales productivity programme rewards closing in-meeting.
Behavioural conflict is structurally invisible to most change methodologies because most impact assessments capture process and system changes but not behavioural shifts. Detection requires extending stakeholder impact analysis to include the behavioural request explicitly, and aggregating those requests at the stakeholder-group level.
Resource and capacity conflict
The fifth type is often confused with scheduling conflict. Resource and capacity conflict occurs when multiple initiatives draw on the same finite pool of human capacity, even if their events are not scheduled in the same week. The pool may be the change team itself, the training function, the technology platform team, or, most commonly, a single critical stakeholder group whose absorption capacity is being drawn on for months at a stretch.
Capacity conflict has a cumulative signature. It looks fine in any given week. It produces burnout, error rates, and decision fatigue over a quarter. The diagnostic question is “what is the cumulative draw on this group over a rolling twelve-week window?” not “is there a clash this fortnight?”.
The cost of undetected change conflict
The cost shows up in four observable ways, all measurable if you instrument for them.
The first is collapsed adoption. Prosci’s research consistently shows that initiatives with poor stakeholder readiness are six to seven times more likely to miss their objectives than those with strong readiness, and conflict is a primary driver of poor readiness because stakeholders forced to choose between competing demands will protect their own day-to-day function. The second is leadership credibility erosion. Employees who experience contradictory leadership signals across initiatives stop trusting the strategic narrative itself, and that loss of trust compounds across future changes. The third is attrition. Workplace Intelligence research found that 53% of employees report experiencing too much change at once, with 71% feeling overwhelmed by the volume of change. Employees in saturated, conflict-heavy environments leave at materially higher rates than employees in coherent ones. The fourth, and most often missed, is middle-manager capacity collapse: the layer of the organisation that absorbs portfolio conflict by translating contradictions into a workable narrative for their teams. Over time they stop translating, behavioural change quietly stops across the portfolio, and no project sponsor sees it.
In every one of those failure modes, the underlying conflict was technically detectable at the point of portfolio planning. The cost is not the conflict. The cost is the delay between when the conflict became real and when anyone in the organisation noticed.
How to detect change conflict: a five-step method
Detection is a discipline, not a tool. Whether you do it manually or with platform support, the method is the same.
Establish a common stakeholder taxonomy. Every initiative must categorise impact against the same set of stakeholder groups, defined consistently across the portfolio. Without this you cannot aggregate. Most organisations discover that their initiatives use overlapping but non-identical group names (“branch managers” in one, “frontline leaders” in another, “RMs” in a third), which makes aggregation impossible.
Overlay every initiative on a single calendar at the stakeholder-group level. Not at the project-milestone level. The output should show, for each stakeholder group, every event that touches them across the next twelve weeks, colour-coded by intensity. The eye picks up scheduling and capacity conflicts immediately when the data is visualised this way. This is the function of a change saturation heatmap.
Audit the leadership and management messaging across initiatives. Pull the last eight weeks of all-hands communications, sponsor videos, and manager talking-point packs across every active initiative. Read them as a single corpus. Look for contradictory framing, mismatched language about culture or pace, and gaps where one initiative implicitly contradicts another.
Map behavioural requests at the group level. For each stakeholder group, list every behaviour each initiative is asking them to perform or stop performing. Identify the contradictions. This is the step almost no organisation does, and it is the one that surfaces behavioural conflict.
Compute cumulative draw per stakeholder group. For each group, calculate the volume of impact, training, communication touches, and behavioural requests across a rolling twelve-week window. Mark groups exceeding their absorption ceiling. This is the capacity conflict view, and it requires a defined capacity model to make sense of the numbers.
These five steps together produce a portfolio conflict picture rather than a project conflict picture. The output usually reveals that several initiatives have been quietly damaging each other for months. That discomfort is the entry point to actually managing them.
Why spreadsheets, project management tools, and generic AI cannot detect change conflict
Most organisations attempt change conflict detection with the tools they already have. The attempts fail in predictable ways, and the failure is structural rather than a question of effort.
Spreadsheets can hold the data, but they cannot keep it current. The moment any initiative replans (which happens weekly in a real portfolio), the spreadsheet ages out. A spreadsheet rebuilt monthly is detecting conflicts that have already manifested. A spreadsheet rebuilt weekly consumes a half-time analyst and still trails reality.
Project management tools (Monday, Smartsheet, Jira, MS Project) are designed to track deliverables, not impacts. Their unit of analysis is the project task, not the impacted employee. They have no native model of stakeholder groups, no aggregation across initiatives by group, no behavioural-request layer, and no capacity ceiling against which to compare. You can build extensions, but you end up building a change intelligence platform inside a project tool, badly.
Generic AI assistants (ChatGPT, Copilot, Gemini) have a deeper limitation: they have no access to the organisation’s portfolio data. A ChatGPT prompt about whether initiatives A, B, and C are in conflict can only produce a plausible-sounding generic answer drawn from training data. It cannot know that initiative B has just slipped two weeks, that stakeholder group X is also being touched by initiative D, or that the behavioural request in initiative C contradicts the messaging in A. Conflict detection requires cross-initiative organisational data aggregated in real time, structured against a common taxonomy. That is not a prompt problem. It is a data infrastructure problem.
This is why a purpose-built change intelligence platform sits in a different category from the alternatives. Detection at portfolio scale is not a feature you can bolt onto a general-purpose tool. It is the data architecture or it is nothing.
How Change Compass’s Conflict Detection Engine works
Change Compass implements change conflict detection as a continuously-running engine across the live portfolio, not a periodic spreadsheet exercise. The platform aggregates impact data from every active initiative against a common stakeholder taxonomy, then evaluates each stakeholder group against five conflict signals in real time.
What triggers an alert
The engine surfaces a conflict alert when one or more of these conditions is met for a given stakeholder group within a defined window:
Concentration: the cumulative volume of impact events exceeds the group’s defined absorption threshold within a rolling window.
Overlap: two or more high-intensity events from different initiatives fall within the same fortnight for the same group.
Behavioural contradiction: two initiatives are requesting opposing behaviours from the same group within the same window.
Messaging divergence: sponsor or manager communications across initiatives are flagged as inconsistent in framing or stated priority.
Capacity draw: the group is being drawn on continuously across a twelve-week or longer horizon by three or more initiatives, with no recovery gap.
Each alert is tied back to the specific initiatives causing it, the affected stakeholder group, and the window in which the conflict will manifest. The aim is to give portfolio decision-makers a signal early enough to act on, not after the fact.
How conflicts get resolved
Detection only matters if it leads to action. The engine pairs alerts with resolution options: sequencing recommendations (which initiative to slip and to when, to minimise cumulative load), absorption modelling (what the load picture would look like under each resolution scenario), and escalation triggers when the conflict cannot be resolved at the working level. Resolution is owned by the portfolio change forum, which has the authority to defer, reshape, or, where required, decline an initiative that would breach absorption thresholds. The platform does not make the call. It surfaces the trade-off in a form the executive can decide on.
Case study: detecting and resolving a four-initiative conflict
A mid-market Australian financial services organisation had four concurrent initiatives touching its branch network in Q3: a teller-system upgrade (cutover week 8), a new customer onboarding process (rollout weeks 6 and 10), a risk culture programme (manager workshops weeks 4 to 12), and an efficiency initiative (handle-time targets reset week 7). Each was governed by its own programme team. Each had reported green status. The portfolio change forum had been convened only quarterly.
When the Conflict Detection Engine ran across the live portfolio data, it surfaced four overlapping alerts on the branch-manager group within weeks 6 to 10: a concentration alert (cumulative impact intensity at 1.4x the defined ceiling), an overlap alert (system cutover and onboarding go-live within nine days), a behavioural contradiction alert (risk programme asking for slower deliberation while efficiency programme reduced handle-time targets), and a capacity draw alert (continuous manager workshop attendance across the same twelve-week window).
The resolution, agreed at a portfolio forum convened on the strength of the alerts, sequenced the onboarding rollout into Q4, paired the system cutover with a structured two-week absorption buffer, and reframed the risk and efficiency messaging into a single integrated narrative under the operating committee. None of the four initiatives missed their delivery commitments. Branch adoption of the teller-system upgrade landed twenty-one points above the organisation’s prior cutover average. The detection event paid for the entire engagement in a single intervention.
The pattern is generalisable: detection alone exposes the problem; the value is unlocked when detection feeds a forum that has the authority to act on what it sees.
Common mistakes in change conflict detection
Detection programmes fail in characteristic ways. The most common are:
Treating detection as a one-off mapping exercise. Conflict is a dynamic state. A map built once at the start of the quarter is detecting yesterday’s conflicts. Detection has to refresh continuously.
Detecting only scheduling conflicts. This handles the easiest type and misses the four that matter more. Priority, leadership messaging, behavioural, and capacity conflicts will not show up in a calendar overlay.
Letting detection sit at the change-manager level. Change managers can flag conflicts but cannot resolve priority, leadership, or capacity conflicts on their own authority. Detection without an executive forum to act on alerts is detection that goes nowhere.
Optimising each initiative’s runway over portfolio coherence. Resolution requires individual projects to accept a shape less convenient for them in exchange for a portfolio that lands as a whole. Without that trade, every alert is contested.
Detecting conflict without a capacity model. Conflict only matters relative to capacity. Without a defined model of how much change each group can absorb, every conflict argument becomes a clash of opinions about whether “this group can handle it”.
Where to start
Pick three stakeholder groups that sit at the intersection of the most initiatives in your current portfolio. Spend a fortnight mapping every initiative event, message, and behavioural request hitting each group across the next twelve weeks. Resist the temptation to act before you have the picture. Once you can see it, ask the executive sponsors of those initiatives to review it together. The conversation that follows is almost always the first time anyone in your organisation has tried to manage the portfolio rather than the projects. That conversation, repeated quarterly with a continuously-refreshed data view rather than a static map, is how change conflict detection becomes a governed capability rather than the invisible force quietly compounding adoption risk across every transformation you run.
What is change conflict detection? Change conflict detection is the discipline of identifying collisions between change initiatives before they derail delivery, by aggregating impact, behavioural, messaging, and capacity data across the portfolio against a common stakeholder taxonomy. It is distinct from project dependency tracking (which looks at deliverables) and from interpersonal conflict management (which looks at people). The unit of analysis is the impacted employee, and the goal is to surface collision early enough to resolve.
How do you manage conflicting change initiatives? Conflicting change initiatives are managed by detecting the collision early (through a continuously-refreshed portfolio view), classifying the conflict type (scheduling, priority, leadership messaging, behavioural, or capacity), and resolving it through a portfolio change forum with the authority to sequence, reshape, or decline initiatives that would breach absorption thresholds. Resolution is a portfolio governance act, not a project-level one.
What are the main types of change conflict to look for? There are five recognisable types: scheduling conflict (initiative events colliding in time), priority conflict (initiatives competing for the same top-priority slot), leadership and management messaging conflict (sponsors contradicting each other), behavioural conflict across initiatives (employees being asked to perform contradictory behaviours), and resource and capacity conflict (cumulative draw on a single stakeholder group’s absorption ceiling).
Why can’t generic AI or spreadsheets detect change conflicts? Detection requires cross-initiative organisational data, structured against a common stakeholder taxonomy, aggregated in real time. Spreadsheets age out the moment any initiative replans. Project management tools track deliverables, not employee-level impacts. Generic AI tools have no access to the organisation’s portfolio data and cannot reason about cumulative load on specific stakeholder groups. Detection is a data architecture problem, not a prompt problem.
What’s the difference between change conflict and change saturation? Change saturation is the state in which the workforce can no longer absorb additional change. Change conflict is one of the principal mechanisms that causes saturation, by drawing on the same finite resource from multiple directions at once. Saturation is the outcome; conflict is one of the causes. Detecting and resolving conflict is one of the most direct levers an organisation has for preventing saturation.